Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
- New to JMP? Let the Data Analysis Director guide you through selecting an analysis task, an analysis goal, and a data type. Available now in the JMP Marketplace!
- See how to install JMP Marketplace extensions to customize and enhance JMP.
JMP Wish List
We want to hear your ideas for improving JMP. Share them here.- JMP User Community
- :
- JMP Wish List
We want to hear your ideas for improving JMP software
We know that you have many valuable ideas on potential new features, or enhancements to existing features. You can use this Wish List to share your ideas, and discuss how to improve JMP, with other users across the globe.
Here's how to participate:
- Search: Please search for an existing idea first before submitting a new idea.
- Kudo & Comment Kudo ideas you like, and comment to add to an idea.
- Subscribe: Follow the status of ideas you like. Refer to status definitions to understand where an idea is in its lifecycle. (You are automatically subscribed to ideas you've submitted or commented on.)
- Submit: Post your new idea using the Suggest an Idea button. Please submit one actionable idea per post rather than a single post with multiple ideas.
We can’t implement everything, so please include the following to help JMP Product Management evaluate your ideas for consideration:
- What inspired this wish list request? Please describe the current issue that needs improvement or the problem to be solved that is not easy or possible right now, with an example use case.
- What is the improvement you would like to see? Please describe the idea for improving JMP. Please include mock-ups, wireframes, screenshots, scripts, other documents or examples from other software that help describe the change you would like to see.
- Why is this idea important? Please describe the value to you and/or other users if the idea is implemented (for example, ease of use, must have,…).
Showing ideas with label Data Exploration and Visualization.
Show all ideas
Now I have to calculate measures of association when fitting a Nominal Logistic Model by hand(Fit Model, module). But they are in the Fit Y by X model. Fit Model allows more flexibility and more independent variables. Would it be possible to have these measures of associations that are now in the Fit Y by X routine for nominal data, also included as far as possible in the Fit Model Routine if you run a Nominal Logistic Fit on Nominal data. That would be very helpful and insightful. If possible also add the Contingency coefficient and Cohen’s omega.
... View more
See more ideas labeled with:
-
Data Exploration and Visualization
What inspired this wish list request?
If a user selects rows in a data table, the corresponding entries in a Tabulate platform are highlighted. This interactivity is very useful - it's similar to the highlighting of data points in a plot when points in another plot are selected.
Unfortunately, in an exported HTML file, the entries are not highlighted.
What is the improvement you would like to see?
Please implement the row highlighting for Tabulate also for interactive HTML files.
Why is this idea important?
Competitor Software provides interactive highlighting for tables - not just for Plots.
... View more
See more ideas labeled with:
-
Data Exploration and Visualization
Status:
Acknowledged
Submitted on
06-02-2023
07:57 AM
Submitted by
 Victor_G
on
06-02-2023
07:57 AM
Victor_G
on
06-02-2023
07:57 AM
What inspired this wish list request?
When building complex models based on large number of collinear/correlated variables, there are several possibilities available. One of them is transforming the variables into principal components, and then create a model based on these principal components to avoid collinearity issues, reduce dimensionality and keep a large part of the initial information.
The problem that could happen in predictive modeling is data leakage : information from the validation set and/or test set is used in the pre-processing and/or model building.
This can happen in PCA platform if validation/test rows are not hidden and excluded : if the PCA is done on the whole dataset and after models are built on the training principal components data, the model still contains a part of the information from the validation and test sets. Model evaluation can become biased as the performances would be assessed too "optimistically".
What is the improvement you would like to see?
As for other platforms (see Fit Model below), I would like a validation role when launching the PCA platform dialog, so that the PCA is created with the training rows, and applied on validation and test rows :
Why is this idea important?
The validation role for PCA would enable user to be more aware of this data leakage situation when they are building predictive models. It's also part of the best practices to split the dataset first into train/valid/test sets before doing any transformation/model, so adding this validation role would enforce a reliable best practice for users. Finally, it would be also easier to use PCA in a more reliable way as a pre-processing step for predictive models with this feature, instead of manually or scripting excluding rows.
... View more
See more ideas labeled with:
-
Basic Data Analysis and Modeling
-
Data Exploration and Visualization
-
Predictive Modeling and Machine Learning
What inspired this wish list request?
When using Multivariate platform and using "Color map on Correlations" and any other of the non-parametric color map on correlation (Spearman, Kendall or Hoeffding's D), the colors in the scale are reversed :
For parametric color map, by default positive correlations are in red, negative ones in blue :
For non-parametric color maps, by default positive correlations are in blue, negative ones in red (reversed color scale) :
What is the improvement you would like to see?
I would prefer having the same color scale/code for both type of correlation map : red for positive correlations, blue for negative ones. The colors difference between the two type of correlation maps can be misleading.
Why is this idea important? This issue should not be a big problem to fix, and would enable to have consistent color scales for correlations by default for all users. It would avoid any manual reformatting (or JSL scripting).
This problem is also highlighted when reading the JMP help : Multivariate Platform Options (jmp.com), where both color maps should have the same color scales : "on a scale from blue (+1) to red (-1)".
... View more
See more ideas labeled with:
-
Basic Data Analysis and Modeling
-
Data Exploration and Visualization
Status:
Acknowledged
Submitted on
05-17-2023
06:58 AM
Submitted by
JMPinthePool
on
05-17-2023
06:58 AM
What inspired this wish list request?
I look at a lot of manufacturing process data, and often the data sets are very big, but sometimes we are interested in a relatively small number of data points.
What is the improvement you would like to see?
It would be really cool if graph builder had this 'floating reference' line functionality, where you could add it and drag it about to where you're interested in order to easily see the associated values for each line - particularly useful if you have 'stacked' y-axes in graph builder - something i find i'm doing more and more.
Why is this idea important?
could be useful for anyone exploring time-stamped data
... View more
See more ideas labeled with:
-
Basic Data Analysis and Modeling
-
Data Exploration and Visualization
-
Quality and Process Engineering
0
Kudos
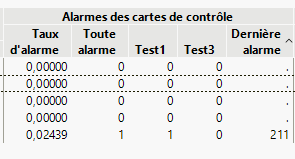
En réalisant une analyse, je me suis rendu compte que le criblage des processus pourrait être encore plus puissant. Au lieu de savoir à quelle ligne correspond l’alarme (paramètre « dernière alarme »), le fait d’avoir la date dans cette colonne serait bénéfique car nous pourrions directement savoir quand a eu lieu la dernière alarme (il y a 3mois ou hier).
Mettre en place une option pour remplacer dans le criblage des processus dans la colonne dernière alarme : pouvoir y mettre une colonne date pour contrôler quand on lieu nos alarmes plutôt que de savoir dans quelle ligne de la base de données l’alarme a eu lieu
... View more
{kind=link}
See more ideas labeled with:
-
Data Exploration and Visualization
Status:
Acknowledged
Submitted on
04-25-2023
12:03 PM
Submitted by
Moisedau
on
04-25-2023
12:03 PM
I perform multivariate linear regressions using the stepwise statistical analysis method, and when I need to remove variables with a high VIF in the coefficient estimation section, I have to search for them among the summary of effects section to select and remove them.
The improvement I would like to see is the ability to directly select variables in the coefficient estimation section, which would automatically select the corresponding variable in the summary of effects section for removal.
This would save a lot of time when conducting this type of test with a large number of variables.
... View more
See more ideas labeled with:
-
Advanced Statistical Modeling
-
Data Exploration and Visualization
-
Quality and Process Engineering
Hello,
Can the functionality of Compare Data Tables be extended to allow comparison of more than two data tables at a time? In the interim, is there a workaround to enable this? In my current use case, I'd like to compare changes across three data tables.
Thank you.
Regards
Mehul Shroff
... View more
See more ideas labeled with:
-
Data Blending and Cleanup
-
Data Exploration and Visualization
Status:
Under Consideration
Submitted on
04-15-2023
01:38 PM
Submitted by
MShroff
on
04-15-2023
01:38 PM
Hello,
Can the following be added to the rules table of the AA report?
- Support for condition and consequent?
- PS and IS Measures (see attached)?
Thanks and regards
Mehul Shroff
... View more
See more ideas labeled with:
-
Data Exploration and Visualization
-
Predictive Modeling and Machine Learning
What inspired this wish list request? What is the improvement you would like to see? Why is this idea important?
... View more
See more ideas labeled with:
-
Data Exploration and Visualization
What inspired this wish list request? What is the improvement you would like to see? Why is this idea important?
... View more
See more ideas labeled with:
-
Data Exploration and Visualization
0
Kudos
☑ cool new feature ☑ could help many users! ☐ removes a „bug“ ☐ nice to have ☐ nobody needs it #myTop10_2023 ➜ Jmp18 :) What inspired this wish list request? Many of the plot types in Graph Builder have the option to apply a summary statistics before displaying the data, but Smoother doesn't have this feature. Therefore, the Smoother data can deviate a lot from what is plotted as Points or Line. What is the improvement you would like to see Please add the functionality of Summary Statistics also to Smoother. Why is this idea important? With the possibility to use a summary statistics for Smoother, it will be much easier to plot such curves and to get the smoother aligned to what the other plot types display. At the moment, the user has to re-program the functionality of Summary Statistics via Column formulas to preprocess the data to use it with Smoother. Names Default To Here( 1 );
dt = Open( "$SAMPLE_DATA/Big Class.jmp" );
Graph Builder(
Size( 535, 458 ),
Show Control Panel( 0 ),
Summary Statistic( "Median" ),
Graph Spacing( 4 ),
Variables( X( :age ), Y( :height ) ),
Elements(
Points( X, Y, Legend( 5 ), Summary Statistic( "Min" ) ),
Smoother( X, Y, Legend( 6 ) ),
Line( X, Y, Legend( 7 ), Summary Statistic( "Min" ) )
)
)
; more wishes submitted by
... View more
See more ideas labeled with:
-
Data Exploration and Visualization
Hello, I would like to request the option to do a Fit All for Discrete Fit in the Distribution Platform, similar to what's available for Continuous Fit. Regards Mehul Shroff
... View more
See more ideas labeled with:
-
Data Exploration and Visualization
What inspired this wish list request? What is the improvement you would like to see? Allow Graph Builder to create error bars/confidence bands using model based estimates. Why is this idea important?
... View more
See more ideas labeled with:
-
Data Exploration and Visualization
Since long I'm observing that row states Hide, Exclude and Hide&Exclude are not always working as expected. I made a demo case for Exclude and Hide. I would expect that an excluded row is not part of an analysis but it is shown in graphs. It works like this - sometimes. Just run the attached script. The behavior is the same in JMP16 and 17. Interacting with the data is the core of JMP's analytical promise. It must be consistent across platforms otherwise the user can't trust results.
... View more
See more ideas labeled with:
-
Data Exploration and Visualization
What inspired this wish list request? What is the improvement you would like to see? Why is this idea important? It is important to show that there is data at a zero bar and all chart elements should change independently in graph builder (these also aligns with what a user is expecting)
... View more
See more ideas labeled with:
-
Data Exploration and Visualization
The current summary of a smoothing spline shows the lambda parameter which is hard to connect to the smoothness of the fit when introducing this methodology. To offer a more interpretable measure of the smoothing spline, the output could add the trace of the projection matrix, aka, the equivalent degrees of freedom (EDF). With the EDF, it would then be simpler to contrast the fit of a smoothing spline to, for example, the fit of a polynomial with an equal number of parameters. The EDF is a component of the output for a smoothing spline in R.
... View more
See more ideas labeled with:
-
Basic Data Analysis and Modeling
-
Data Exploration and Visualization
Status:
Acknowledged
Submitted on
03-12-2023
07:20 AM
Submitted by
Victor_G
on
03-12-2023
07:20 AM
What inspired this wish list request?
I'm using JMP Pro 17 and really happy with the introduction of Design Space Profiler.
However, I was surprised to see that inside some models' platforms that can use Profiler, the Design Space Profiler was not directly accessible/available (example here with SVM, not having the possibility to directly use Design Space Profiler feature, but this "bug" is also present for Bootstrap Forest, Boosted Tree, and perhaps some other modeling platforms) :
For some other models' platforms, the Design Space Profiler is directly accessible/available (here with Neural Networks) :
What is the improvement you would like to see?
There is still a workaround for this situation, by saving the formulas in the datatable and create a Profiler based on these formulas. The Design Space Profiler is then always available :
But it would be easier if the Design Space Profiler was available "by default" in all modeling platforms that have access to the Profiler.
Why is this idea important?
The Design Space Profiler is a very informative and interesting feature.
JMP beginners may not be aware of the possible workaround, and may miss some very interesting informations because of the "non-native" presence of this feature in all modeling platforms.
... View more
See more ideas labeled with:
-
Advanced Statistical Modeling
-
Data Exploration and Visualization
-
Predictive Modeling and Machine Learning
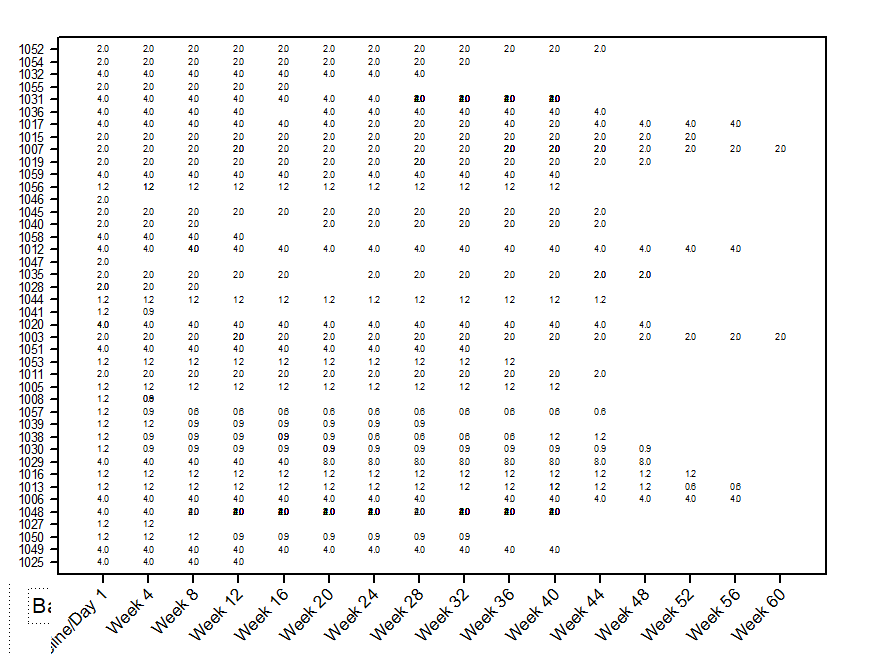
What inspired this wish list request? I would like to be able to visualize an additional variable What is the improvement you would like to see? I would like to create a graph where the symbols or points can be substituted with numbers or letters from a column I select. See example attached generated in Sigmaplot. Why is this idea important? This allows display of additional variable without having to hover.
... View more
{kind=link}
See more ideas labeled with:
-
Data Exploration and Visualization
What inspired this wish list request? I have done a number of experiments using DOE and am a novice at the process. We had a demo of the easy DOE with our company representative and it looks amazing! However, it doesn't help us with What is the improvement you would like to see? It would be super helpful if we could take a previous design and put it into the easy DOE interface to help with the analysis on the back end. I know it wouldn't help with the design, but it would give valuable insights on how to look at our outputs Why is this idea important? THis would make the easy DOE an even more powerful tool. Experiments take a lot of time and energy so if we could get more/better information out of them rather than redoing them to get the benefit of easy DOE we would be really happy.
... View more
See more ideas labeled with:
-
Data Exploration and Visualization
-
Design of Experiments
Idea Statuses
- New 642
- Needs Info 52
- Acknowledged 726
- Under Consideration 19
- Yes, Stay Tuned! 25
- Delivered 258
- © 2026 JMP Statistical Discovery LLC. All Rights Reserved.
- Terms of Use
- Privacy Statement
- Contact Us