Large language models (LLMs) as ‘almost perfect’ user interfaces
I attended a conference recently with, not surprisingly, several talks on LLMs. A couple things became clear: Everyone is wondering when they’ll be able to trust LLMs 100% of the time.People are using LLMs as a natural language user interface for difficult-to-execute tasks. In the context of statistical modeling, what’s interesting to me is: We already have tools that are deterministic and can be ...
 LauraCS
LauraCS
23 views
|
0 replies

 volker_kraft
volker_kraft

 Masukawa_Nao
Masukawa_Nao
 Craige_Hales
Craige_Hales
 Richard_Zink
Richard_Zink
 Byron_JMP
Byron_JMP
 dieterpisot
dieterpisot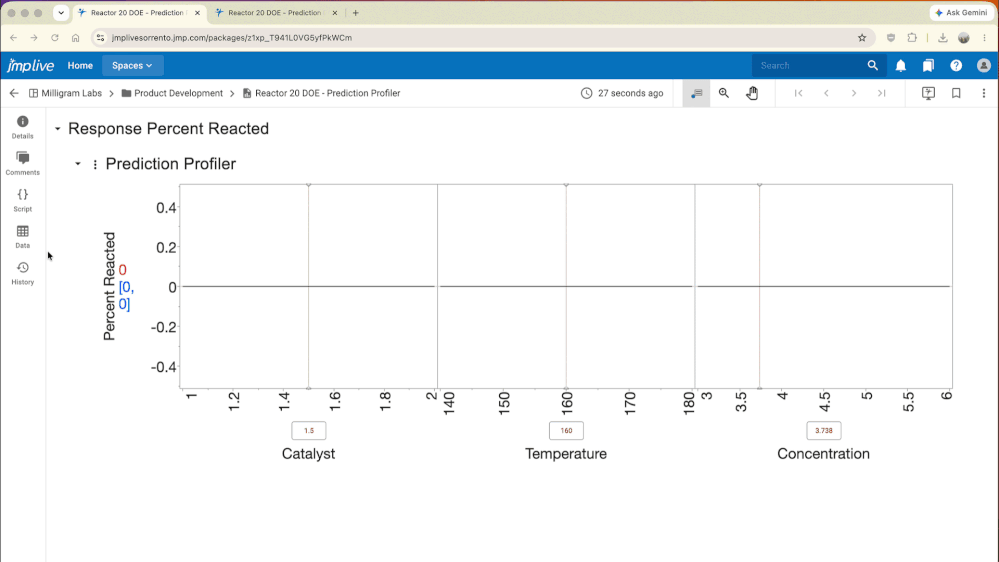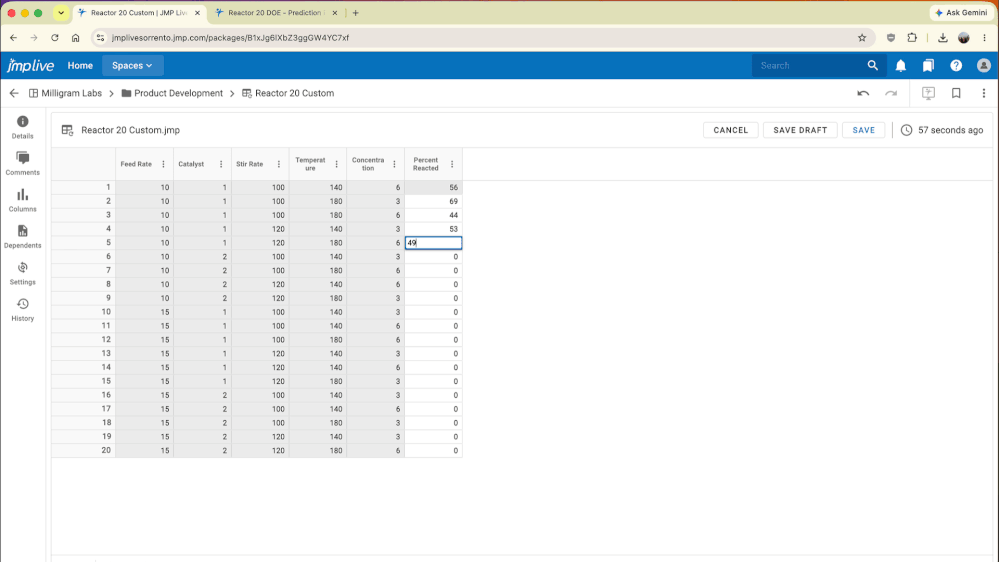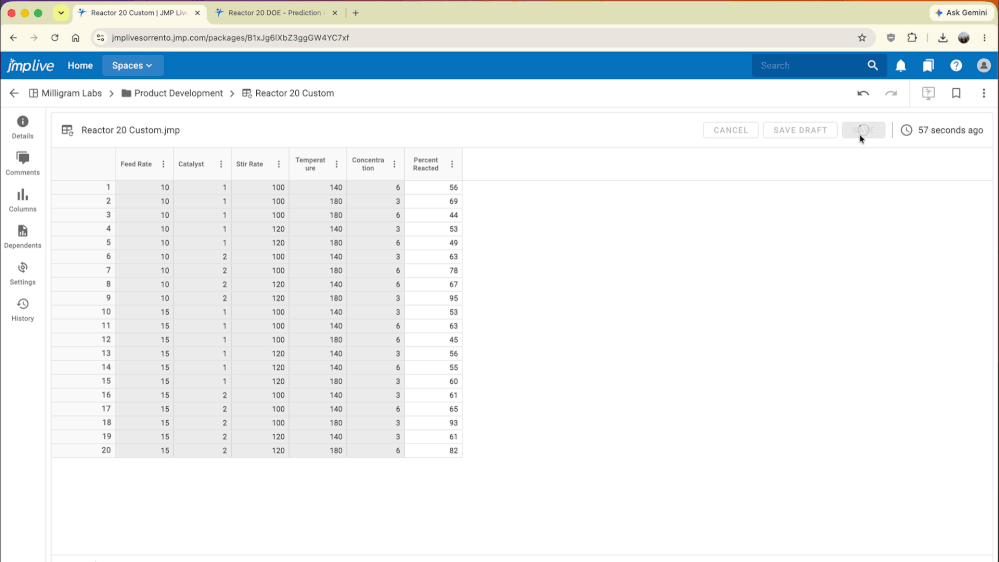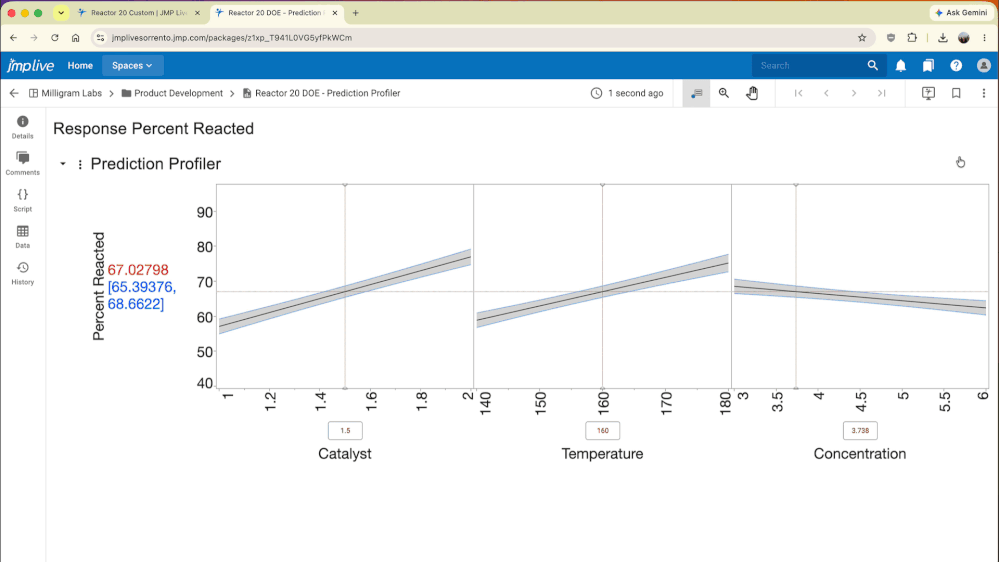
 Wendy_Murphrey
Wendy_Murphrey
 MikeD_Anderson
MikeD_Anderson
 Victor_G
Victor_G




 Jed_Campbell
Jed_Campbell

 anne_milley
anne_milley

