Teaching Statistical Thinking with JMP Student Edition: A classroom-ready analytics tool
Before AI enters the statistics classroom, what does a genuinely good teaching tool look like without it? Episode 1 of my new series makes the case for JMP Student Edition - a professional environment, not a simplified one.
 volker_kraft
volker_kraft
83 views
|
1 replies

 Masukawa_Nao
Masukawa_Nao
 Craige_Hales
Craige_Hales
 Richard_Zink
Richard_Zink
 Byron_JMP
Byron_JMP
 dieterpisot
dieterpisot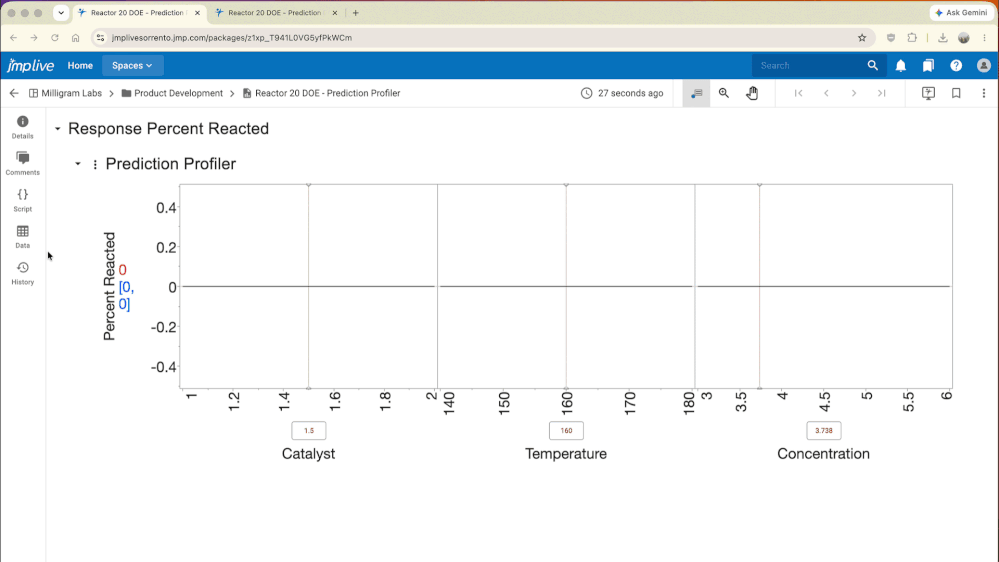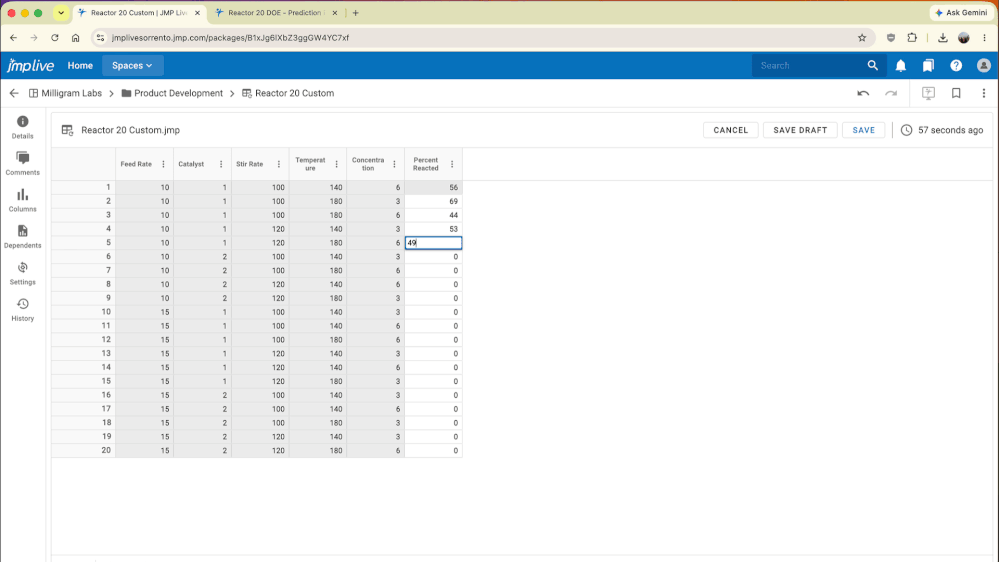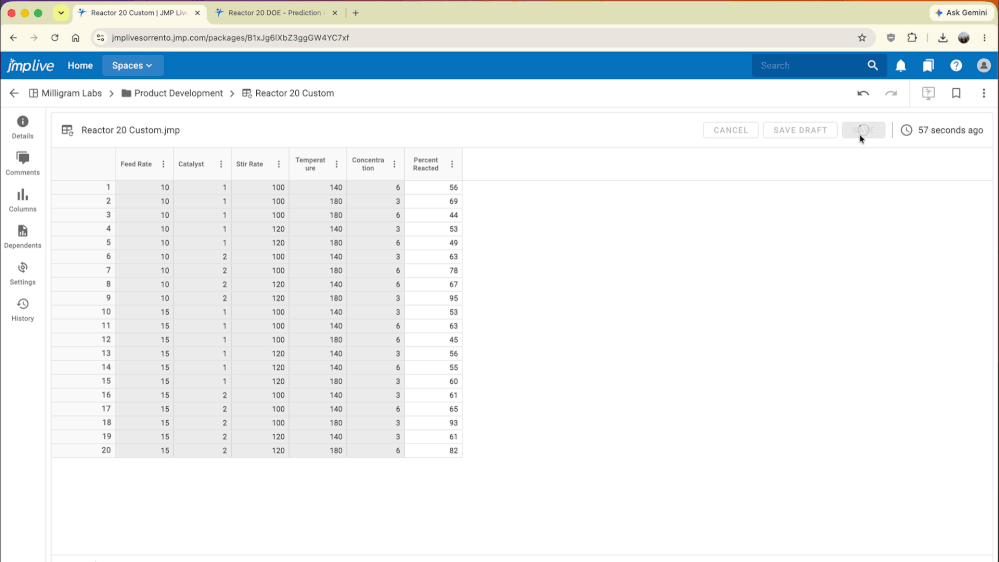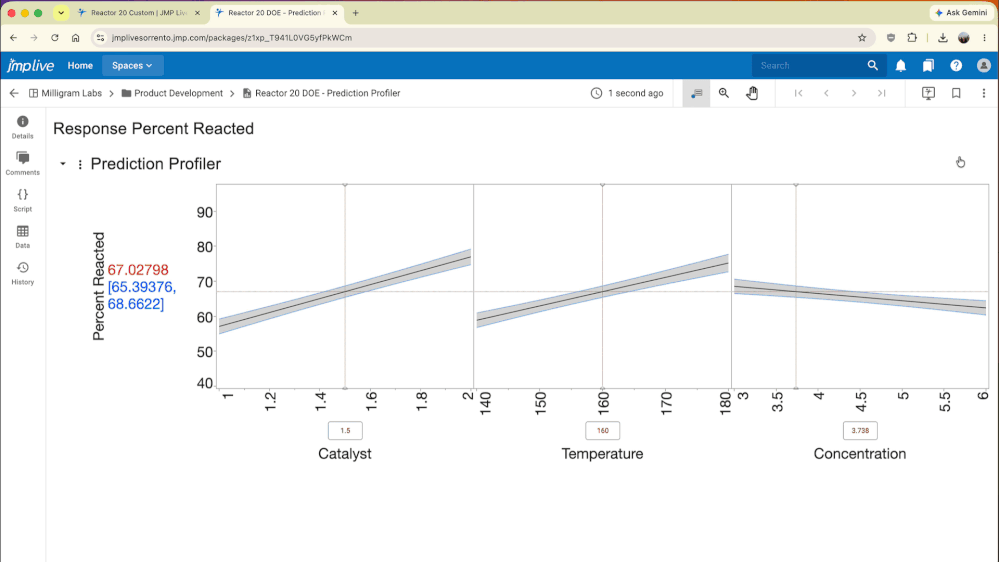
 Wendy_Murphrey
Wendy_Murphrey
 MikeD_Anderson
MikeD_Anderson
 Victor_G
Victor_G




 Jed_Campbell
Jed_Campbell

 anne_milley
anne_milley



