Teaching with JMP Student Edition: JMP Assistant in practice - what it can do for you
What if students could ask their analysis question in plain English and get a real result in seconds? Episode 3 looks at JMP Assistant in practice — what it does well, and why the instructor's role just got more interesting, not smaller.
 volker_kraft
volker_kraft
49 views
|
0 replies

 LauraCS
LauraCS


 Masukawa_Nao
Masukawa_Nao
 Craige_Hales
Craige_Hales
 Richard_Zink
Richard_Zink
 Byron_JMP
Byron_JMP
 dieterpisot
dieterpisot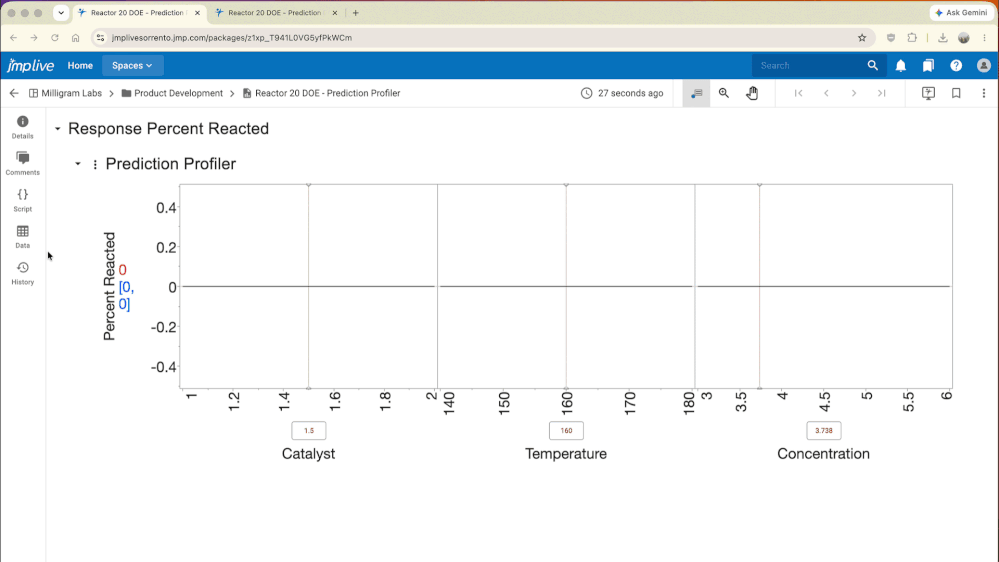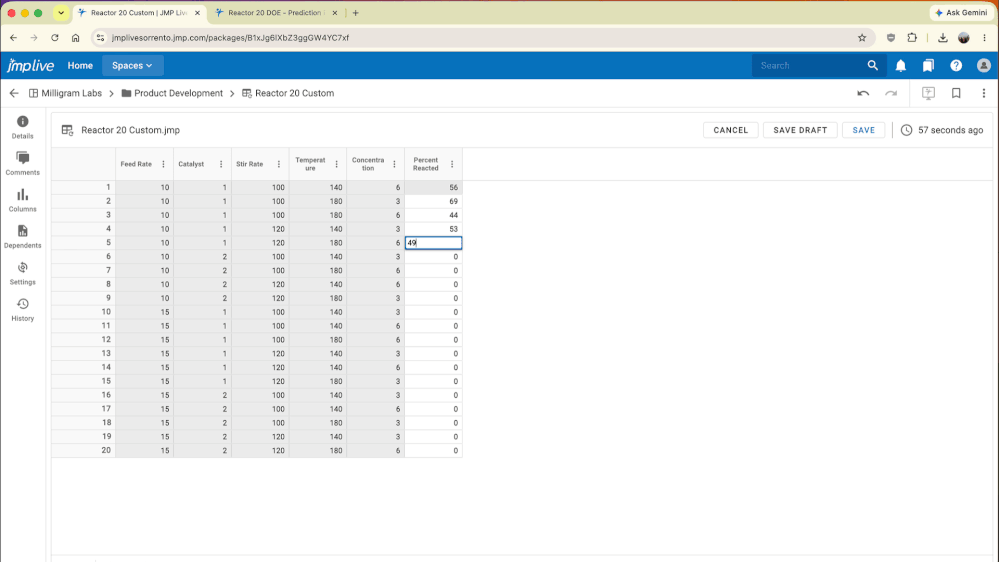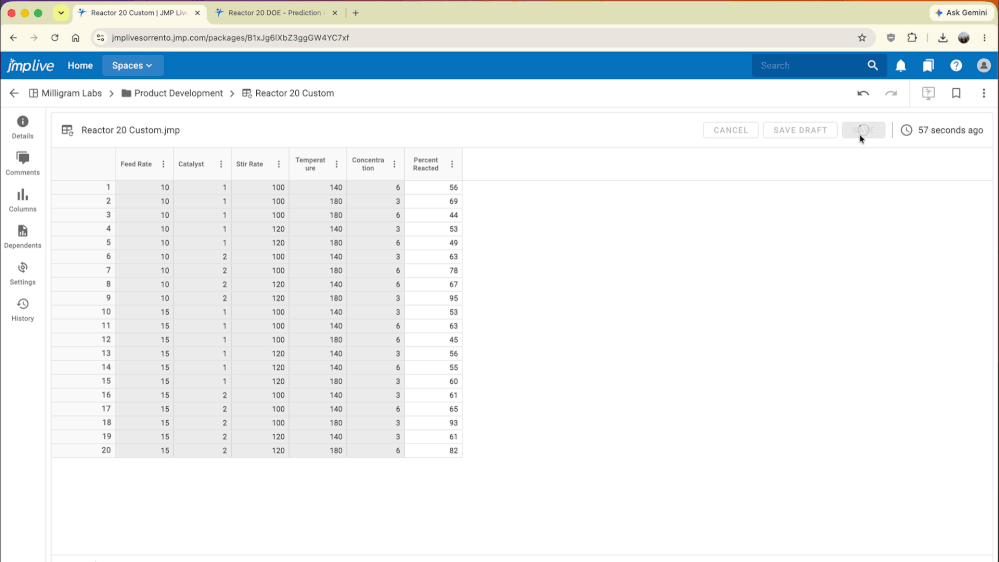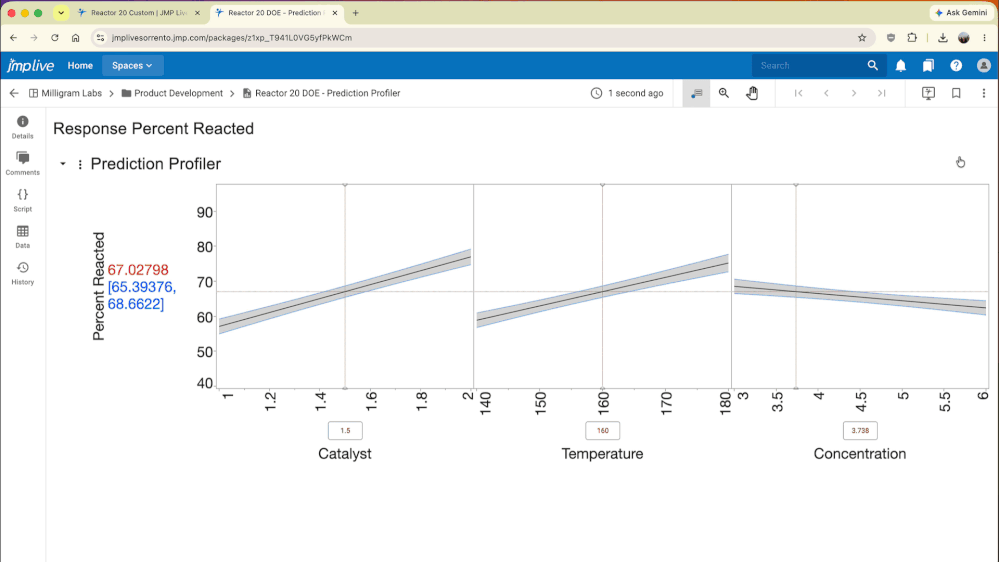
 Wendy_Murphrey
Wendy_Murphrey
 MikeD_Anderson
MikeD_Anderson
 Victor_G
Victor_G




 Jed_Campbell
Jed_Campbell

 anne_milley
anne_milley
