Make PowerPoint Slides or Word Docs that Auto-Update Figures made in JMP
So, you've spent and hours writing up a report on an an experiment and copying in carefully formatted figures from JMP. Now a week later you have updated data and are absolutely thrilled at the prospect of deleting and replacing all the figures from last week with the new updated figures from this week. Wouldn't it be awesome if there were some way to just run the analysis in JMP from your saved ...
 Byron_JMP
Byron_JMP
67 views
|
0 replies

 dieterpisot
dieterpisot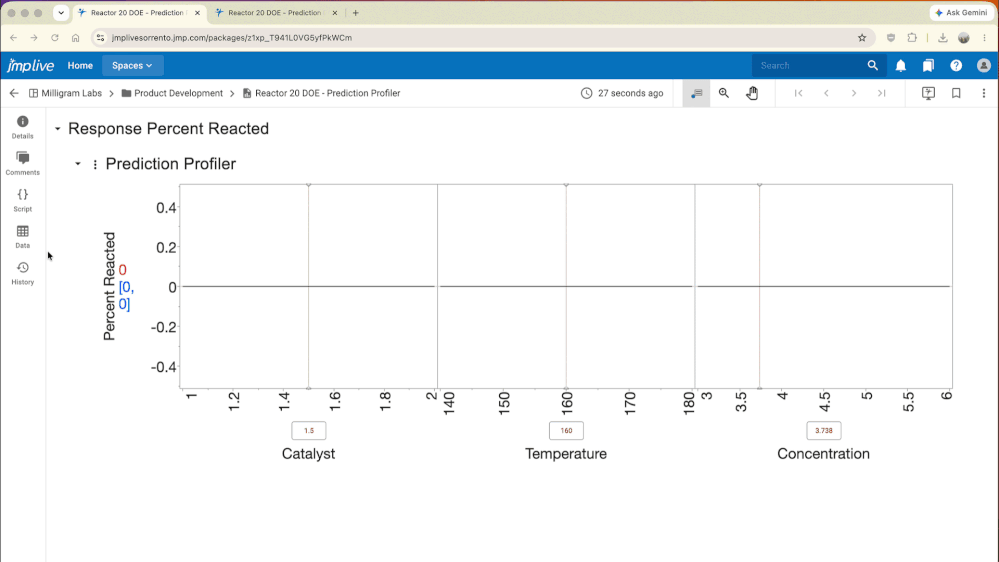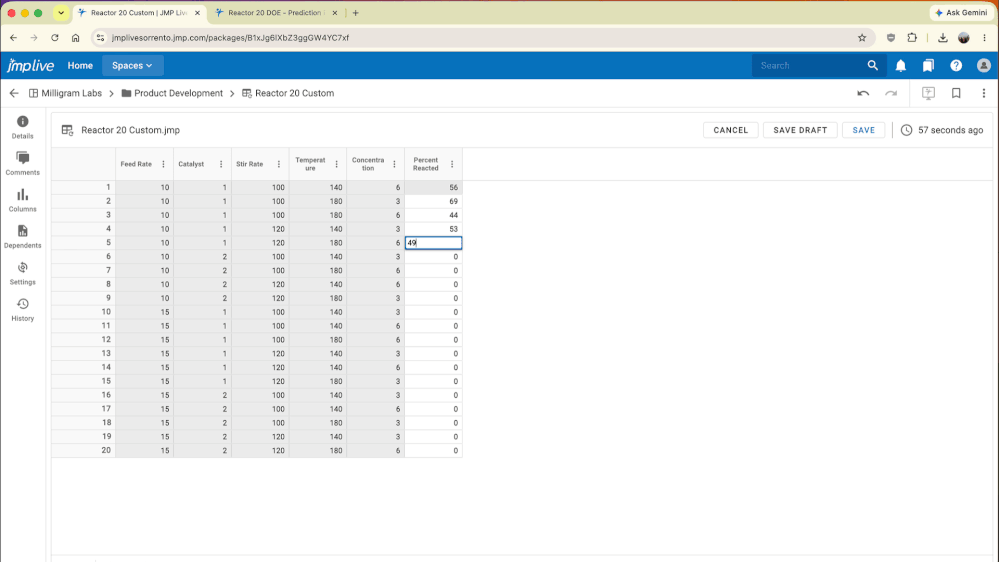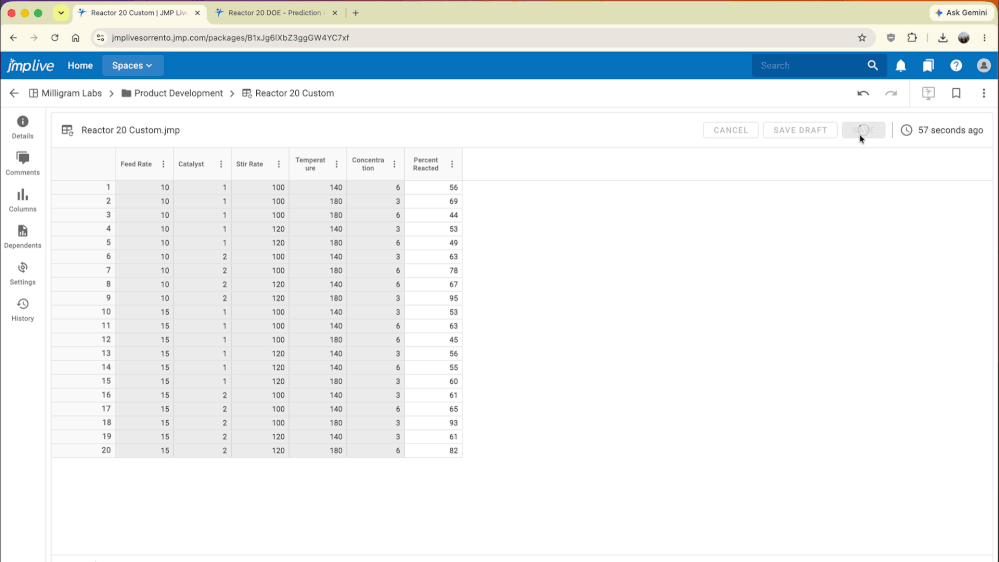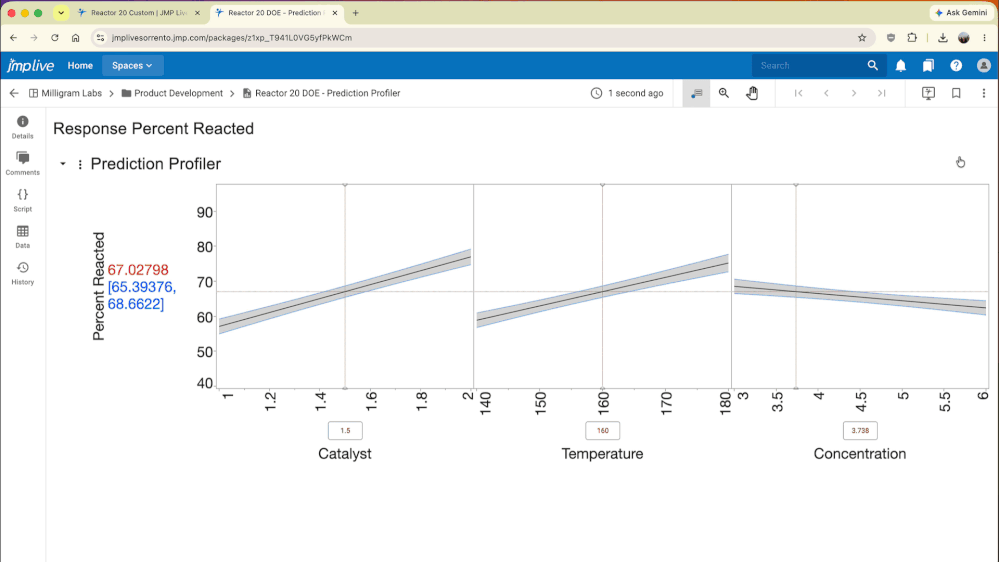
 Wendy_Murphrey
Wendy_Murphrey
 MikeD_Anderson
MikeD_Anderson
 Victor_G
Victor_G


 Richard_Zink
Richard_Zink

 Jed_Campbell
Jed_Campbell

 anne_milley
anne_milley