It's not Normal, or is it?
In several recent discussions about using parametric tests the question of whether the data is normally distributed (or passes a goodness of fit test ...
 Byron_JMP
Byron_JMP
55 views
|
0 replies
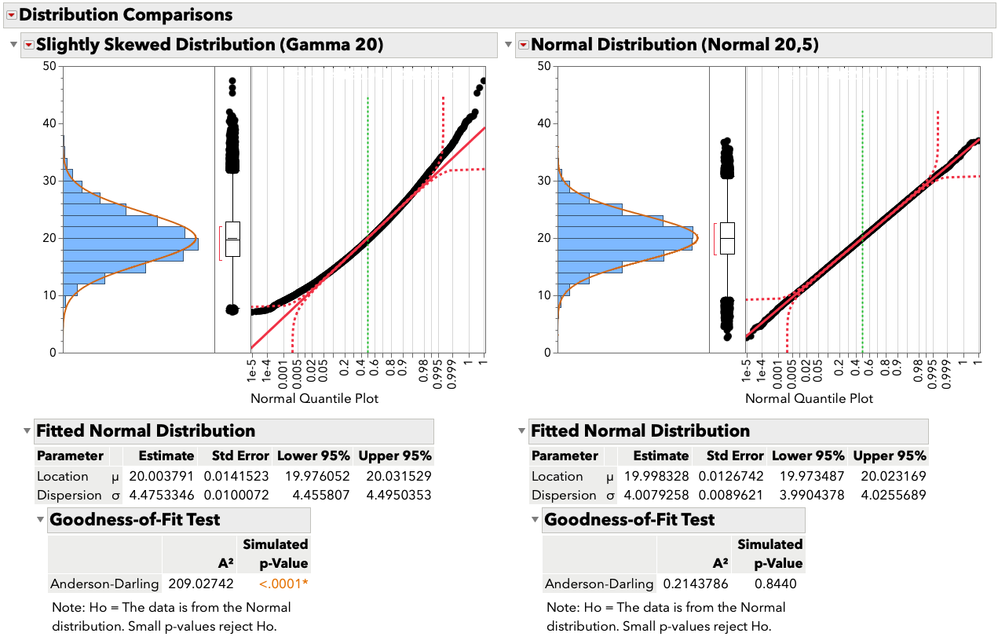
 Jed_Campbell
Jed_Campbell
 JMP_Taiwan
JMP_Taiwan

 LandraRobertson
LandraRobertson
 Ross_Metusalem
Ross_Metusalem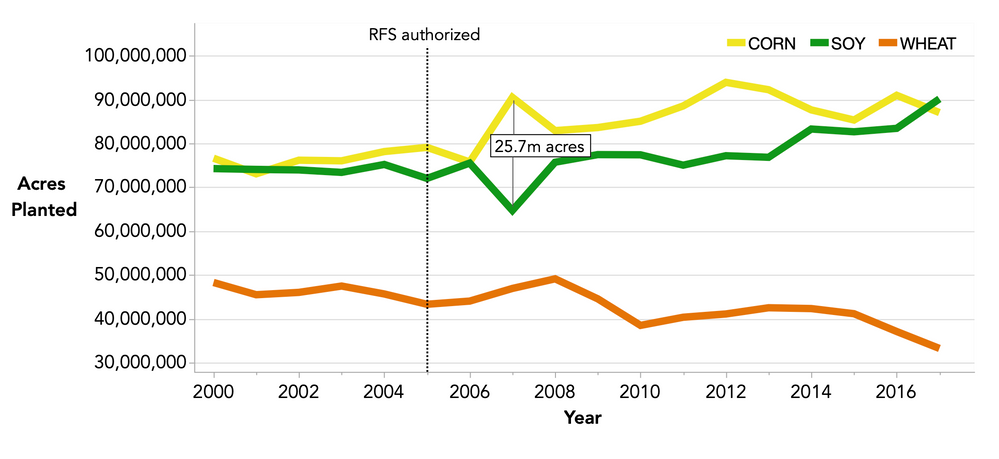
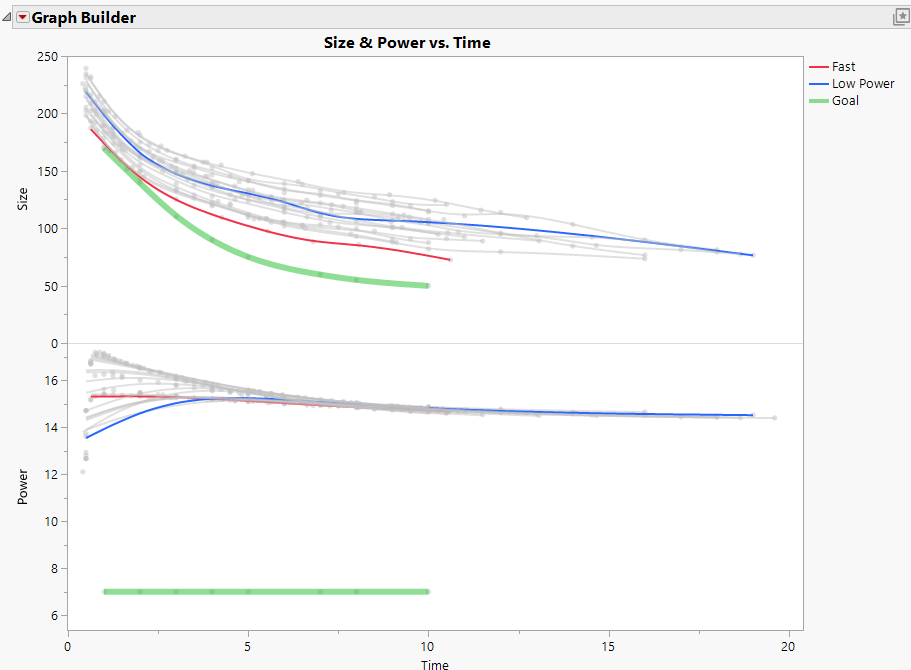
 monique_lander
monique_lander
 MaddiWalsleben
MaddiWalsleben
 scwise
scwise
 DonMcCormack
DonMcCormack
 scott_allen
scott_allen
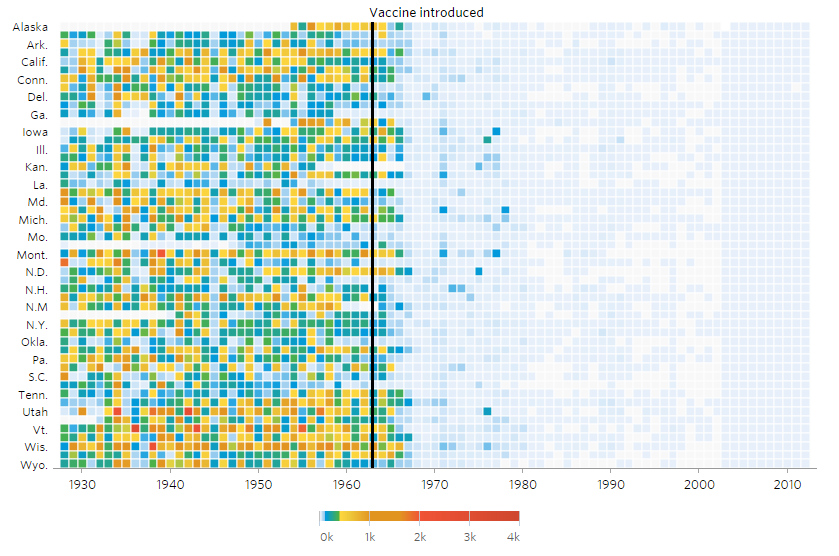
 Daniel_Valente
Daniel_Valente
 anne_milley
anne_milley
 haleyyaremych
haleyyaremych
 Duane_Hayes
Duane_Hayes
 Katie-Beth_V
Katie-Beth_V