Teaching responsibly with AI: Risks, guardrails, and what I’ve learned the hard way
"The AI said so" — a student's answer to a completely misinterpreted regression. Episode 4 looks at the real risks of AI in the statistics classroom, and four practical guardrails that keep students thinking instead of just approving output.
 volker_kraft
volker_kraft
81 views
|
0 replies


 LauraCS
LauraCS


 Masukawa_Nao
Masukawa_Nao
 Craige_Hales
Craige_Hales
 Richard_Zink
Richard_Zink
 Byron_JMP
Byron_JMP
 dieterpisot
dieterpisot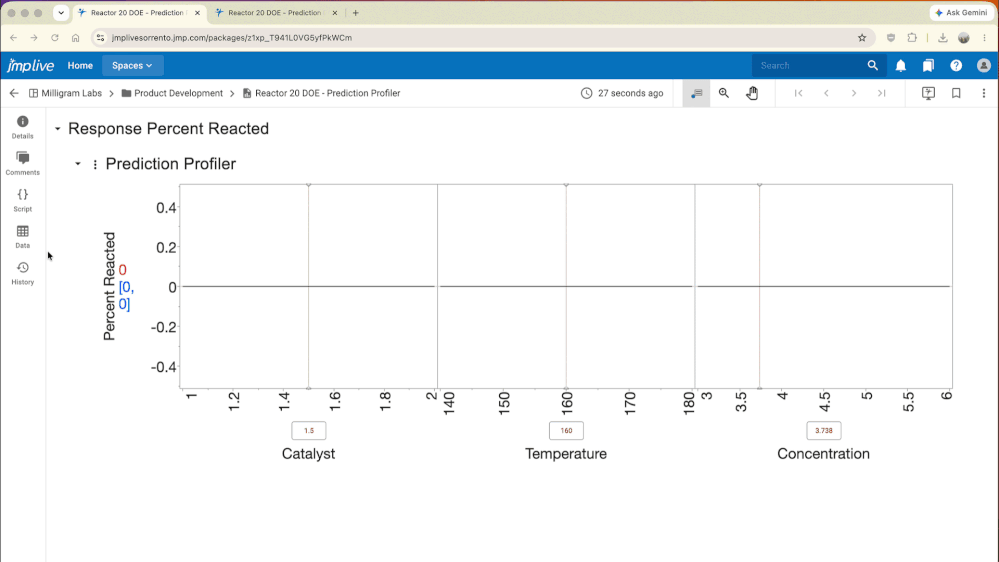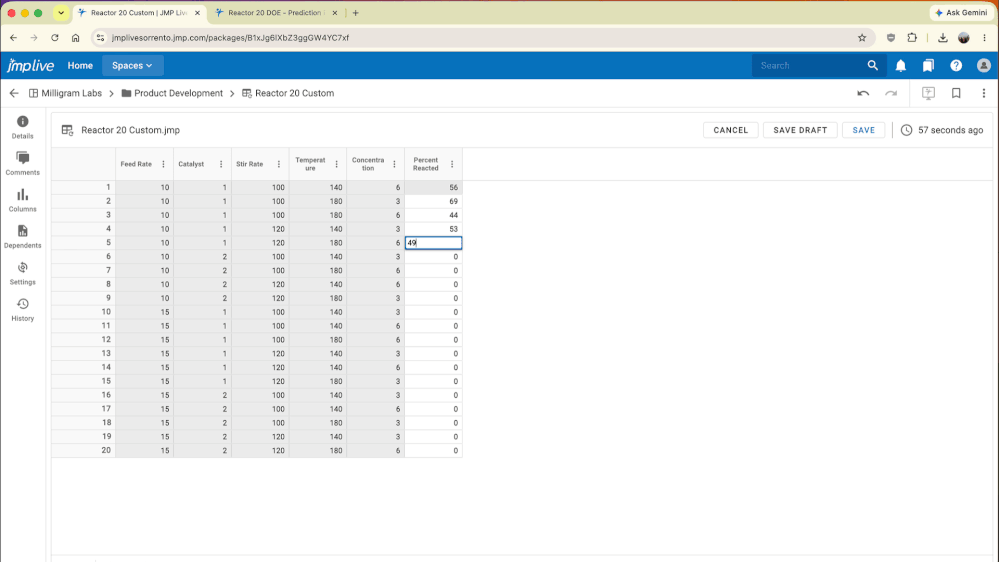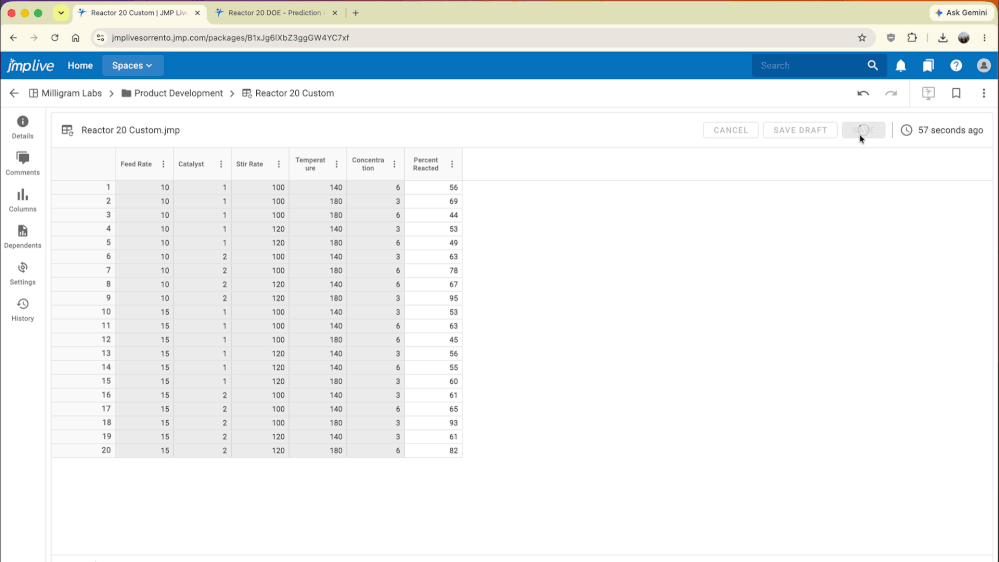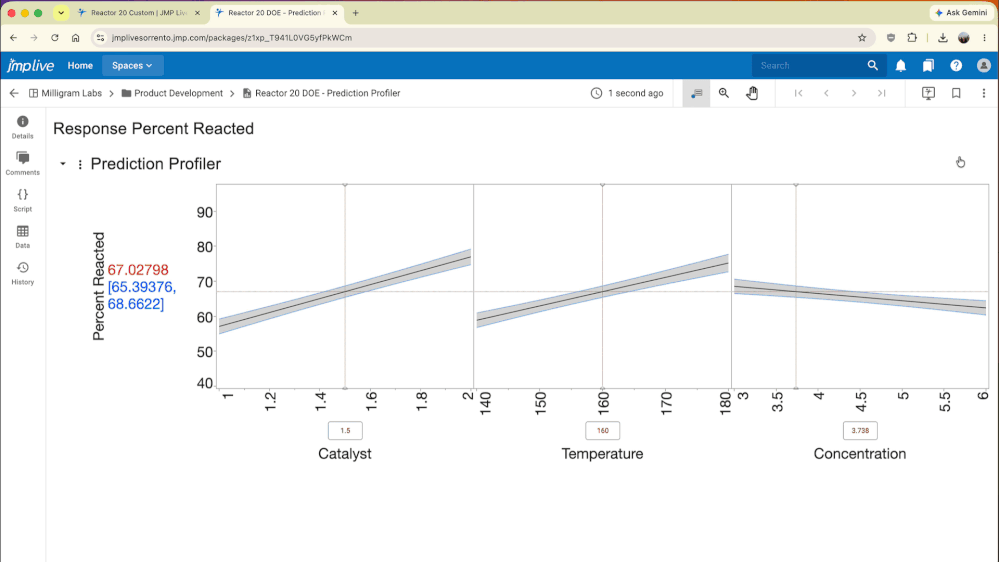
 Wendy_Murphrey
Wendy_Murphrey
 MikeD_Anderson
MikeD_Anderson
 Victor_G
Victor_G




 Jed_Campbell
Jed_Campbell

 anne_milley
anne_milley