Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
- New to JMP? Let the Data Analysis Director guide you through selecting an analysis task, an analysis goal, and a data type. Available now in the JMP Marketplace!
- See how to install JMP Marketplace extensions to customize and enhance JMP.
JMP Wish List
We want to hear your ideas for improving JMP. Share them here.- JMP User Community
- :
- JMP Wish List : Hot Ideas
We want to hear your ideas for improving JMP software
We know that you have many valuable ideas on potential new features, or enhancements to existing features. You can use this Wish List to share your ideas, and discuss how to improve JMP, with other users across the globe.
Here's how to participate:
- Search: Please search for an existing idea first before submitting a new idea.
- Kudo & Comment Kudo ideas you like, and comment to add to an idea.
- Subscribe: Follow the status of ideas you like. Refer to status definitions to understand where an idea is in its lifecycle. (You are automatically subscribed to ideas you've submitted or commented on.)
- Submit: Post your new idea using the Suggest an Idea button. Please submit one actionable idea per post rather than a single post with multiple ideas.
We can’t implement everything, so please include the following to help JMP Product Management evaluate your ideas for consideration:
- What inspired this wish list request? Please describe the current issue that needs improvement or the problem to be solved that is not easy or possible right now, with an example use case.
- What is the improvement you would like to see? Please describe the idea for improving JMP. Please include mock-ups, wireframes, screenshots, scripts, other documents or examples from other software that help describe the change you would like to see.
- Why is this idea important? Please describe the value to you and/or other users if the idea is implemented (for example, ease of use, must have,…).
I would like it if Graph Builder had a Time variable like Bubble Plot does. It would be great to animate all of the Graph Builder plots across time.
... View more
See more ideas labeled with:
Hi there, Could you please add the option for editing X Axis Settings on Variability charts? From 13.2 onwards it does not seem possible to edit them. Thanks, Gareth
... View more
See more ideas labeled with:
Currently in Graph Builder, when using box plot and points graphs combined in the same graph, the box plots properly segregate into "series" when a category is added to 'overlay' but the points do not overlap their coresponding box plot and are instead jumbled. It is as if the box plots have an hidden overlap variable set to 0% (terminology from excel bar graphs) but the points have a hidden overlap variable set to 100%. There are a few ways to fix it, but are either not exact, or take a lot of work to properly format the image, changing box plot colors for proper grouping, and requiring an extra legend to be added. Here is a post with pics refrencing the effects.
... View more
See more ideas labeled with:
In the Specialized Modeling menu, I frequently find the need to compare curve fitting models. It might be nice to have an easy way to compare all curve fitting models within a particular submenu (e.g., polynomials, sigmoid, multiple parameter logistic, exponential growth and decay). I was wondering if a menu item could be added to compare the curve-fitting of appropriately grouped curve fitting models (analogous to the functionality in the Distribution menu for comparing the various possibilities in the Continuous Fit menu by selecting "All").
... View more
See more ideas labeled with:
I would like to see the version number surfaced on the banner of each JMP window, right after the currently displayed Product
i.e.
JMP Home Window - JMP Pro 13.2.1
Big Class - JMP Pro 14.0.0
Big Class - Bivariate of weight by height - JMP Pro 12.2.0
... View more
See more ideas labeled with:
It would be nice if Tolerance Intervals calculated in the Distribution Platform came with a visualization (e.g.) on top of the Histogram. The graph below gives an example. There, I added the Graph Builder visualization of a Tolerance Interval below the Distribution Histogram. I left out Spec-Limits there, but if so specified in the column properties, they should be shown there, as well.
Similar to other features in Distribution I image it would be possible to show or hide this visualization via the red triangle menu.
There are further ideas presented in the Wish List in connection with Tolerance Intervals, e.g.
https://community.jmp.com/t5/JMP-Wish-List/Setting-Confidence-and-Proportion-to-Cover-for-Tolerance/idi-p/51188
https://community.jmp.com/t5/JMP-Wish-List/3-Sigma-Intervals-and-Tolerance-Intervals-in-Graph-Builder/idi-p/51192
https://community.jmp.com/t5/JMP-Wish-List/Statistical-rationales-for-sample-sizes/idi-p/52052
... View more
See more ideas labeled with:
Hi JMP users, I used to run some non-parametric comparisons for each pair using the Wilcoxon method in a repeated-measures designs through Analysis -> Fit Y by X report. I would like to know if it is possible to develop an effect-size calculator (add-in) for that purpose, please. Thank you.
... View more
See more ideas labeled with:
Hi JMP users, I would like to know if it is possible to develop an add-in to calculate the effect-size for repeated-measures design with random effect. I used to run the LSMeans Tukey HSD algorithm in Fit Model report. Thank you.
... View more
See more ideas labeled with:
Hi,
I'm looking at the Profiler red triangle, under Optimization and Desirability -> Set Desirabilities.
Several of our newer users get confused when they have multiple y variables because JMP pops up a separate modal box to set desirability for each response one at a time. The astute ones notice that each box is for a different response, but others don't notice the subtle change.
Any way we could replace this interface with a single window? Use a List Box or a Combo Box or a Tab Box to arrange the different responses. Then the user can go to "Set Desirabilities", see all the responses in one window, and potentially set all of them from the same window. Or, with flexibility to choose which responses need to be set, having a "select the response to change" property allows the user to skip over two or three responses that don't need to be changed in the first place.
Icing on the cake: allow some sort of "Standardize Desirabilities" option from the Profiler as well. Sure, you can standardize attributes from the data table and set the Response Limits property, but when you're in the middle of a Profiler that isn't intuitive.
... View more
See more ideas labeled with:
With the "New Formula Column", a Log can be easy made. it would be a nice feature to transform spec and control limits, axis settings ect.too.
... View more
See more ideas labeled with:
Most of the tables that JMP uses have the magic JMP Home Button icon bottom right of the table which takes you back to the Home Window . I use the Query builder a lot and if I have a number of JMP applications open it can be quite tricky to find which one contains the query as well as any other tables I'm using. Can the JMP Home window button be added to the Query Builder ( as well as any others not currently having it)? David
... View more
See more ideas labeled with:
Ability to use table or local variables from formula editor to control some values in axis, platforms, …
... View more
See more ideas labeled with:
When updating a target table that includes columns with a List Check property, the update on that column fails silently if the update source table contains items that are not in the target table's List Check.
I agree that the update should fail, but it should fail with a warning and an option to (a) remove the List Check before proceeding or (b) abort the update.
... View more
See more ideas labeled with:
In case there are named ranges in Excel sheets it would be good if those could be accessed when importing data into JMP. I have workbooks containing data in named ranges and want to automate data import. The only way i have so far is to script some "search algorithm" to find the boundaries of the named range or using additional software tools like R or Excel-VBA.
... View more
See more ideas labeled with:
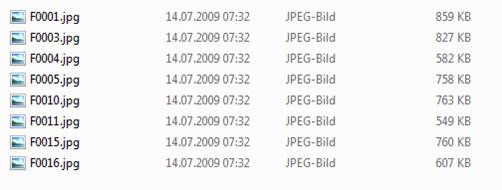
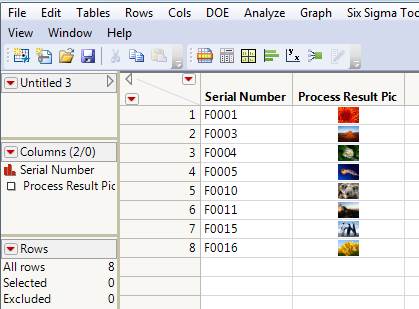
I would like to be able to import selected images from a folder into a new or existing Data Table with the option to either match names of images with names in an existing column or to have the names of the images written in a separate column (see attached illustration). It should be possible to specify a name for the Expression column ("Process Result Pic" in the illustration) and a name for the ID column (if used, "Serial Number" in the illustration), or if names of images should be matched with entries in an existing column, then the name of the existing column must be specified. It would be very handy if file sizes could be reduced (on import) down to a max of x Mbyte, and to a maximum width or height (as in the Column Property "Expression Role"). I'm aware that there is a community entry by M_Anderson with supplied jsl code that goes in a very similar direction, but with the expectation that a column with pic names already exists. I couldn't get this to work (probably I misinterpreted sth there). It would be nice to have an official tool for this with more options. https://community.jmp.com/t5/JMP-Scripts/Adding-Images-to-A-Data-Table-From-a-Directory/ta-p/40341
... View more
{kind=link}
{kind=link}
See more ideas labeled with:
Autosaving data tables should have an option to rename and retain the existing file as "table.jmp.bak" before saving the new version as "table.jmp". The reason is to prevent autosave unintentionally overwriting a "good" copy of a table with a (mis-)edited version.
An even better option is be able to designate a backup folder where N previous versions of the file can be optionally retained.
... View more
See more ideas labeled with:
Status:
Archived
Submitted on
01-04-2018
01:47 PM
Submitted by
walter_isaac
on
01-04-2018
01:47 PM
See the attached journal.
This is a simple example of a variability/gauge plot. from one of the sample datasets.
I do a lot of beginning JMP user training, and I always show them the variability chart because it is so useful for visulaizing the effects of different X factors on a Y response all on one plot.
I would like to be able to do more statistical analysis off this platform. I am looking for the same analysis that is on the fit Y by X platform. For instance in this case an Anova/Tukey means comparison by Gender. And/or a T test comparing gender by each drug.
... View more
See more ideas labeled with:
Status:
Not Planned For Now
Submitted on
12-19-2017
04:06 PM
Submitted by
ewittry
on
12-19-2017
04:06 PM
Expose as many as possible GUI features through JSL. Specifically, in this case, 'new formula column'.
... View more
See more ideas labeled with:
For factorial combinations (in Fit Model), LSMeans tables (also "Connecting Letter Report" tables) should present level names as separate strings in separate columns. That will allow to alternate group order by sorting these tables by level of one factor ("Level i") or by the second factor ("Level j"), regardless the factors' order in the data table.
... View more
Since version 12, "Preferences" allows to set the default Summary Statistics in the output of "Distribution". This option should be effective to all platforms.
... View more
See more ideas labeled with:
Idea Statuses
- New 643
- Needs Info 52
- Acknowledged 726
- Under Consideration 19
- Yes, Stay Tuned! 25
- Delivered 258
- © 2026 JMP Statistical Discovery LLC. All Rights Reserved.
- Terms of Use
- Privacy Statement
- Contact Us