Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
- Learn how to build custom Python data connectors and further customize JMP’s Data Connector Framework with the Python Data Connector Demo, available now in the JMP Marketplace!
- See how to create experiments to support product design and ID useful product features. Register for June 12 webinar, 2pm US Eastern Time.
JMP Wish List
We want to hear your ideas for improving JMP. Share them here.- JMP User Community
- :
- JMP Wish List : New Ideas
We want to hear your ideas for improving JMP software
We know that you have many valuable ideas on potential new features, or enhancements to existing features. You can use this Wish List to share your ideas, and discuss how to improve JMP, with other users across the globe.
Here's how to participate:
- Search: Please search for an existing idea first before submitting a new idea.
- Kudo & Comment Kudo ideas you like, and comment to add to an idea.
- Subscribe: Follow the status of ideas you like. Refer to status definitions to understand where an idea is in its lifecycle. (You are automatically subscribed to ideas you've submitted or commented on.)
- Submit: Post your new idea using the Suggest an Idea button. Please submit one actionable idea per post rather than a single post with multiple ideas.
We can’t implement everything, so please include the following to help JMP Product Management evaluate your ideas for consideration:
- What inspired this wish list request? Please describe the current issue that needs improvement or the problem to be solved that is not easy or possible right now, with an example use case.
- What is the improvement you would like to see? Please describe the idea for improving JMP. Please include mock-ups, wireframes, screenshots, scripts, other documents or examples from other software that help describe the change you would like to see.
- Why is this idea important? Please describe the value to you and/or other users if the idea is implemented (for example, ease of use, must have,…).
Showing ideas with label Data Exploration and Visualization.
Show all ideas
What inspired this wish list request?
Few posts I found from community and pinning ruler could also be fairly helpful from time to time.
What is the improvement you would like to see?
Ability to pin rulers and crosshairs to graphs (with crosshairs it should be possible to hide the aiming circle). Could also be helpful to be able to add multiple of them and possibly have some additional settings such as colors (for ruler also changing increment).
Why is this idea important?
Provides additional tools to annotate your graphs
... View more
See more ideas labeled with:
-
Basic Data Analysis and Modeling
-
Data Exploration and Visualization
-
Sharing and Communicating Results
☐ cool new feature ☑ could help many users! ☑removes something that feels like a „bug“ ☐ nice to have ☐ nobody needs it What inspired this wish list request? In general, Jmp doesn't distinguish between upper and lower case - and Jmp ignores white spaces in Symbol names. So, :age can refer to the same column as :A G E But :age and :A G E can be also different columns. check if column exists? JSL ignores white-spacing for names, most people don't take advantage of this! Let's take the Concatenate platform as an example. This platform is very picky with column names. If Table A has a column :age and table B has a column :A G E,the combined table will contain 2 columns! In general this is a nice feature: better split the columns, the user can merge them later. But for user who lived the carefree life of "difference don't matter" - the first collision with Concatenate can be traumatic. What is the improvement you would like to see? In Concatenate (and other platforms?) please provide an option "Column Names: Exact match". If the option is on, Concatenate is as picky as now, if it's off, Concatenate follows the usual rules of JMP/JSL when comparing column names. Why is this idea important? - The option will give the user more possibilities. - The presence of the option will generate awareness! - The idea is related to the option Exact Match (1 |0) of dt << has column(), which will be introduced with Jmp18: data table : message column exists(colname)? more wishes by
... View more
See more ideas labeled with:
-
Automation and Scripting
-
Data Blending and Cleanup
-
Data Exploration and Visualization
☑ cool new feature ☑ could help many users! ☑ removes something that feels like a „bug“ ☐ nice to have ☐ nobody needs it What inspired this wish list request? Some functions in Jmp take a very long time to get finished. There is a request toSpeed up Tables/Update , because it can take hours to be executed. "Get rows where" is taking way to long Another issue: Life Distribution. Depending on the size of the data table, the user has to wait for hours: https://community.jmp.com/t5/Discussions/how-to-make-cumulative-probability-plots-in-JMP/m-p/717879/highlight/true#M89957 another application case: Database queries. They can be executed in the background. But then the query cannot be included in a script. The next part of the script has to wait for the data to arrive. Would be great if there was an option to interrupt the query if it takes too long. For all these cases, it could help to cancel the activity after a specified Timeout interval: What is the improvement you would like to see? Option: For Try(), please add a possibility to specify a timeout interval. If the execution of the code takes longer, the script is stopped and the table is reverted to the initial state.Timeout of the try function Please add a timeout parameter in the preferences. if the user specifies a timeout of 10 minutes, If starting a platform or executing an action takes longer than 10 minutes, the execution is stopped. For actions which alter the data table, the table is restored to the point before starting executing the action. This should be possible because most actions in Jmp have an undo function. I guess a recovery point is stored before starting the action? Why is this idea important? There is a Wish from 2020 with 79 Kudos:Kill process without killing JMP ! So, it seems that there is an extreme demand here, but it also seems to be extremely complicated to fulfill the users' wish. The Timeout concept could be an easy solution. Every user will accept to wait 10 minutes (and get a coffee - or two) instead of losing the results of many hours because an action in Jmp takes orders of magnitude longer than the user expected. more wishes by
... View more
See more ideas labeled with:
-
Automation and Scripting
-
Data Blending and Cleanup
-
Data Exploration and Visualization
☐ cool new feature ☐ could help many users! ☐ removes a „bug“ ☑ nice to have ☐ nobody needs it What inspired this wish list request? When reshape the appearance of existing report, the Horizontal 0/1 option helps a lot: The horizontal option is not only available for ListBoxes, but also for oher DisplayBoxes, e.g. ColumnSwitcherContextBoxes. Do I want the Column Switcher on the left or on the top? -> just enable or disable the Horizontal option :) For Lineup Boxes it's similar: Just send <<NCol(N) to a lineup Box and the items will be aligned horizontally instead of vertically (if the setting before was NCol(1)) You can imagine what comes next? How do I get the Column Switcher below the graph or to the right? What is the improvement you would like to see? option 1) For DisplayBoxes which can contain multiple sub-items, please provide an option Reverse 0/1 to specify if the items appear 1->N inside the report or in the reverse order. option 2) please provide a functionality to specify the precise order of the sub-items. Maybe even with the possibility to specify a different number M of items to display - for a Display Box with originally N available items. *) <<order({x,y,z}) where the user can specify the number of the sub-item that should appear at position x, the item that should appear at position y and so on. e.g. with the option order ({1,1,1}), the first sub-item of the Listbox should appear 3 times (making sense or not). *) I think it's easier to be open here than to throw an error if M=N and if a specific item is listed multiple times. Why is this idea important? More flexibility when re-formatting a report window that already exists. Giving more flexibility for the placement of e.g. Column Switcher menus. more wishes by
... View more
See more ideas labeled with:
-
Data Exploration and Visualization
Status:
Acknowledged
Submitted on
01-17-2024
02:56 AM
Submitted by
francois_berger
on
01-17-2024
02:56 AM
What inspired this wish list request? What is the improvement you would like to see? Why is this idea important?
... View more
See more ideas labeled with:
-
Data Exploration and Visualization
What inspired this wish list request? I have a table that is already sorted in a specific manner and I can't resort it. I need to do a Column Statistic, but not a standard statistic. I can build JSL in the column formula to go through the whole table to create a matrix "by" the categories of interest, but for this larger table, the JSL layer would be pretty slow and inefficient. JMPs canned columns statistics already gather these matricies - and quite fast - so I would like to leverage that. What is the improvement you would like to see? I would like to see a column function that is more generic... so like ColMean(column, by1, by2, by3) returns the mean of a matrix of values by 'by1', 'by2' and 'by3' .... I would like a function that just returns the matrix of values prior to any math being done. Why is this idea important? As mentioned in the first section, coding this in the column formula would be very inefficient. Coding this in a separate script (a table script, perhaps) could be faster, but then not as 'live' as a formula in a column. With JMPs base infrastructure already existing, being able to leverage it further would be ideal.
... View more
See more ideas labeled with:
What inspired this wish list request? While crosshair tool is useful to read the approximate values around the curves it would be good to snap on a smoother-ed curve that is closest to the crosshair. What is the improvement you would like to see? Snap feature on the graph. Why is this idea important? This will enable quicker and more accurate look at the curve values compared to going into the table.
... View more
See more ideas labeled with:
-
Basic Data Analysis and Modeling
-
Data Exploration and Visualization
What inspired this wish list request? I use the cross-hair tool and measurement tools a lot but find myself having to write down a lot of information I gain from them, which is a waste of time. What is the improvement you would like to see? I would like to see the following: Cross hair Ability to "Pin" the cross-hair tool image Ability to save out the values of the cross hair to a table Measurement tool Ability for the cross hairs to calculate a slope value that would show under the dx and dy values Ability to force the measurement tool to stick in an "x / y" mode (like when the axis are different data types) vs the "slope" mode (when data are the same data types). This will allow you to line up the X and Y values to the data more easily. Ability to "Pin" the measurement tool image Ability to save out the values of the cross hair to a table Why is this idea important? The cross-hair and measurement tools are amazing at allowing you to interact with your data but the usefulness is muted by having to resort to hand calculating / documenting the information that you gain.
... View more
See more ideas labeled with:
-
Data Exploration and Visualization
-
Sharing and Communicating Results
What inspired this wish list request? I use the tree map as a the base graph to report out a dashboard of summary statistics for multiple areas in my plant. The current squarify option leaves some "boxes" almost useless. What is the improvement you would like to see? I'd like to see a "forced square" option in the Layout drop down menu that would make the boxes all the same size, which could mean that there are blank boxes if there are not enough categories to fit a even row/column matrix. Ideally every box would look like chem mill stacked or heat query stacked. You can see on dry times stacked that there is one long and skinny box that is hard to see. Why is this idea important? Dashboards are becoming key tools for conveying operational status quickly so charts that are easy to see all the elements are vital. This is also critical as we move to JMP live as dashboard style graphics are a main reason for the move.
... View more
See more ideas labeled with:
-
Data Exploration and Visualization
-
Quality and Process Engineering
-
Sharing and Communicating Results
☐ cool new feature ☑ could help many users! ☑ removes a „bug“ ☐ nice to have ☐ nobody needs it What inspired this wish list request? Sometimes a user wants to revert a label and cannot do this: In Jmp there is a severe bug: after a manual change of an axis label,when you add or remove subplots, this label doesn't stick to the respective axis - the label sticks to the "position": Manual axis labels are 'mixed up' when plotting multiple columns If a user deletes the text label, he has no access anymore to the label - so: no possibility to edit the label. This issue will be fixed in Jmp 18 :) nice feature: If a user deletes the title of an Outlinebox, the title bar gets removed. But there is no possibility restore the title bar. What is the improvement you would like to see? Please add commands to revert labels: a) revert a specific axis label b) revert all labels of the Graph. Why is this idea important? The feature will make the life of a Jmp user much better. more wishes by
... View more
See more ideas labeled with:
-
Data Exploration and Visualization
☐ cool new feature ☑ could help many users! ☑ removes something which feels like a „bug“ ☐ nice to have ☐ nobody needs it What inspired this wish list request? To generate presentations with consistent design and smooth transitions, users might want to generate Plots with consistent size and design. In Jmp it is very difficult generate plots with consistent plot region and label sizes: Graph builder Frame size JSL In Jmp 18, a new feature was added to store plot settings and to apply the settings to other plots. But this does not include a fixed plot region. Jmp support thinks that it might be possible to gernate plots with consistent plot region size - but cannot provide a recipe nor code to accomplish the task: TS-00076249 The background: In general, every Graph that is exported from Jmp (via Save or copy to clipboard) has a different size of the plot region, even if the Size() setting is the same. Factors which influence the size of the plot region - even for identical Frame sizes: - screen resolution - font sizes - axis orientation - axis label settings - ...? What is the improvement you would like to see? Please proved a method to generate plots with consistent size of the plot region and axis size settings. Why is this idea important? Graphs which are exported from Jmp look nice. But if every graph has slightly different size and label size, this looks chaotic when switching from one slide of a presentation to another. With the new option, this issue can be solved. more wishes submitted by
... View more
See more ideas labeled with:
-
Data Exploration and Visualization
-
Sharing and Communicating Results
What inspired this wish list request? I would like using the label orientation "Automatic" consistently but currently I must define it at each individual axis in graphs. What is the improvement you would like to see? I would like to have it as a preference so that it is applied automatically to all my graphs. Why is this idea important? The proposal is important because it saves us a öot of clicks.
... View more
See more ideas labeled with:
-
Basic Data Analysis and Modeling
-
Data Exploration and Visualization
What inspired this wish list request? Need to be able to match background color in Graph Builder to certain value in gradient legend. What is the improvement you would like to see? Add ability to use an eyedropper to sample a color from within or outside of JMP and be able to set that color for lines or background. Why is this idea important? Further flexibility in visualization capabilities.
... View more
See more ideas labeled with:
-
Data Exploration and Visualization
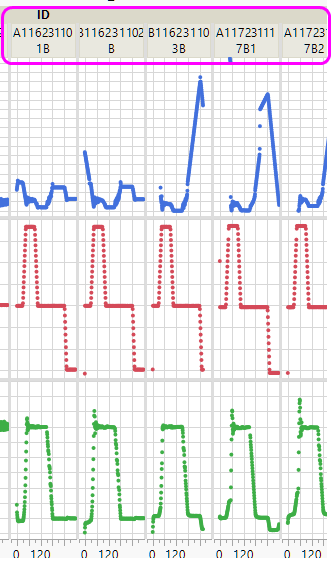
What inspired this wish list request? Please describe the current issue that needs improvement or the problem to be solved that is not easy or possible right now, with an example use case. I am using JMP 17.1.0 on Windows 10. This is a piece of the jsl, the remainder is just axis formatting instructions. In this case the Group X variable = "ID" is a text string that is at least 10 characters long, and with this many IDs to compare, the space is too small to easily read the ID with horizontal orientation. Graph Builder(
Size( 1377, 605 ),
Graph Spacing( 3 ),
Variables(
X( :ProcTime_mins ),
Y( :BVO ),
Y( :TotalAr ),
Y( :VAC ),
Group X( :ID )
), ... What is the improvement you would like to see? Please describe the idea for improving JMP. Please include mock-ups, wireframes, screenshots, scripts, other documents or examples from other software that help describe the change you would like to see. Add an option to change the orientation of the Group X Label to either vertical or horizontal, and the need arises. Why is this idea important? Please describe the value to you and/or other users if the idea is implemented (for example, ease of use, must have,…). I have seen this same question with several solutions in the Community Discussion section but they have not solved the problem. Vertical orientation of the Group X labels would make the ID much easier to read.
... View more
{kind=link}
See more ideas labeled with:
-
Data Exploration and Visualization
☐ cool new feature ☑ could help many users! ☑ removes something that feels like a „bug“ ☐ nice to have ☐ nobody needs it Short: Graph builder needs this function: Long: What inspired this wish list request? Every Jmp user knows this issue: when you invested 15 minutes to optimize your Graph Builder plot, added some subplots, added some categories and then the legend looks like this - and you need another 15 minutes to figure out which entry in the legend corresponds to which subplot. When computers started to have several video outputs, computer users had a similar issue: which monitor setting belongs to which monitor ?!?!? And the programmers had a great invention: an Identify button. The user just has to click the button and numbers will appear: 1) in the overview 2) on each monitor What is the improvement you would like to see? 1) I want the same functionality for Graph builder. An Identify Button . When a user clicks the button, numbers should appear in the Frameboxes and in the legend: [extreme case to illustrate the unbelievalble help of the suggested function] ") please also add a button to "reset" the sequence of entries in the legend to a default setting: all entries from the first subplot, then all entries from the second subplot .... Why is this idea important? Nowadays it's very difficult to use different color coding in different subplots - as soon as a new subplot is added, all the color settings are scrambled. The unpredictable sequence of entries in the legend makes it almost impossible to efficiently adjust the settings. more wishes from
... View more
See more ideas labeled with:
-
Basic Data Analysis and Modeling
-
Data Blending and Cleanup
-
Data Exploration and Visualization
-
Sharing and Communicating Results
What inspired this wish list request? Displaying tables with decimal numbers can be confusing when there is a large number of digits. What is the improvement you would like to see? Possibility of setting the default number of decimal places displayed in the table (for example, limit the default to 2) in the preferences. It will avoid us to do it for each table or desired columns (even if the « Standardize Attributes » helps) Why is this idea important? Help readability in JMP tables;
... View more
See more ideas labeled with:
-
Data Access
-
Data Exploration and Visualization
What inspired this wish list request? The use of iba records (https ://www.iba-ag.com/en/) in the steel and energy industries become an international standard. No direct file import is possible, an intermediate txt file is needed. What is the improvement you would like to see? Direct file import (like excel) using preview. Possible batch import with multiple files because these files are process data recording all day long Why is this idea important? Developing a gateway would make it easy to open up JMP to this field of activity (metals and energy). Developments (c++, .net,… in dll form) for reading iba files are available from iba.
... View more
See more ideas labeled with:
-
Automation and Scripting
-
Data Access
-
Data Exploration and Visualization
What inspired this wish list request? To my knowledge to change the FONT size for the legend in a graph (for example using Bivariate platform) the user changes the Heading Fonts size in the Files>Preferences>Fonts GUI. However, this also changes the font size in the data table for the column headings. What is the improvement you would like to see? Add an option to File > Preferences > Fonts GUI to enable user to customize the font size for a graph and this option would not change the data table column heading font size. Perhaps there is also a way to jsl script the customization of the graph legend font size, but I've not figured out a way to that so far. Why is this idea important? For presentations and graph readability a large legend font size of ~18 or larger is used. However, this makes data column headers large and makes the data table more difficult to work with and can make column headings become only partially veiwable in certain GUI windows, or sub windows with a GUI. User then needs to stretch the window to be able to read the full column name. Unfortunately, sometimes column names get long in attempt to fully describe the given column's content details.
... View more
See more ideas labeled with:
-
Automation and Scripting
-
Data Exploration and Visualization
-
Mass Customization
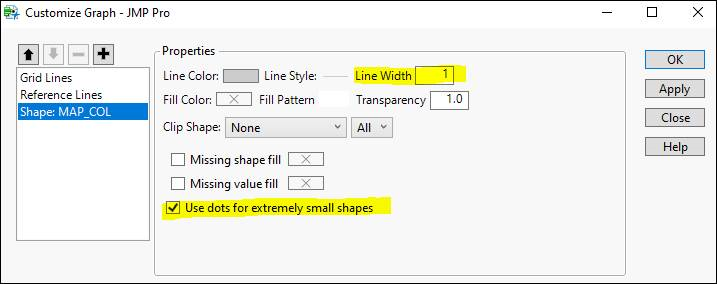
What inspired this wish list request? My team uses Graph Builder’s map role/shapes functionality extensively and we cannot find any way to set these other than via script or manually, which is cumbersome/repetitive. For our use case, we always set the Shape line width from ‘1’ to ‘0’ and unselect “Use dots for extremely small shapes”. Shape properties are accessible by right-clicking the Graph Builder data area > Customize… > Shape: <column_name>. What is the improvement you would like to see? Add Graph Builder Map Shape property defaults to File > Preferences. Why is this idea important? This will cut down on repetitive steps and improve flexibility in mapping options.
... View more
{kind=link}
See more ideas labeled with:
-
Data Exploration and Visualization
What inspired this wish list request?
I was trying to make some errors easily visible in wafermaps and started playing around with Fill Selection Modes. I managed to make my graphs visual enough (but there is no "perfect" option), but I could make it even more visual if I could combine multiple modes (at least two). Also changing and trying out different options requires me to go through multiple menus using mouse.
What is the improvement you would like to see?
I have few suggestions regarding Fill Selection Mode in JMP graphs to make JMP visuals provide more information quicker. There are a lot of different situations where JMPs default option of Selected Patterned isn't really that helpful. I will use Wafer Stacked.jmp as an example dataset for most of these with this starting situation (stacked wafermaps and Defects mean used as color) and I have selected some random areas. There are a lot of other situations where diffee
Not very easy to see QUICKLY what has been selected if I'm using default option "Selected Patterned".
1. Let us combine multiple Fill Selection Modes OR provide new options which have these combinations predefined
Depending what you are trying to present, you might want to highlight your graphs in different ways. In this case I would like to quickly highlight the specific areas of wafermap. Few selection modes work quite well
Selected Darkened
Selected Outlined
Unselected Faded (best for this case in my opinion with current options)
And finally Selected Same Color (otherwise good but it is difficult to change the color AND I will lose information on the graph, so I wouldn't use this in this case)
But what I would like to do is to combine these (at minimum two) or at least have few new options. I would like to combine at least Selected Outlined+Unselected Faded or Selected Darkened + Unselected Faded.
Demonstration of Selected Outlined + Unselected Faded
And in this case maybe better option Selected Darkened + Unselected Faded
2. Let us easily change the Fill Selection Mode without always going though the hassle of right-clicking the graph
Drop-down menu toolbar could be one idea, similar to data table list in Script Editor (of course dropdown wouldn't work unless they are checkboxes if we can make our own combinations). I will most likely write my own add-in which will let user to go to next selection by pressing a button (or shortcut key) for now.
3. Let us easily change the "Fill Selection Color" from somewhere else than JMP Preferences or make the color choice somehow smarter.
Currently I don't know if this color can be changed anywhere else than preferences and depending what I'm doing, the preference color might be very bad.
4. Maybe nice to have in some cases let us define which Pattern to use when using Selected Patterned
Sometimes different pattern could solve a lot of visual issues. We do have a lot of different patterns already available, they are just "never" used
Why is this idea important?
Makes JMPs visuals more visual, quicker and more easy to use.
Other
Other a bit similar suggestion for just graph builder and marker selections: Graph Builder: Marker Selection mode -> multiple selections!
... View more
See more ideas labeled with:
-
Data Exploration and Visualization
-
Sharing and Communicating Results
Idea Statuses
- New 635
- Needs Info 53
- Acknowledged 748
- Under Consideration 19
- Yes, Stay Tuned! 28
- Delivered 258
- © 2026 JMP Statistical Discovery LLC. All Rights Reserved.
- Terms of Use
- Privacy Statement
- Contact Us