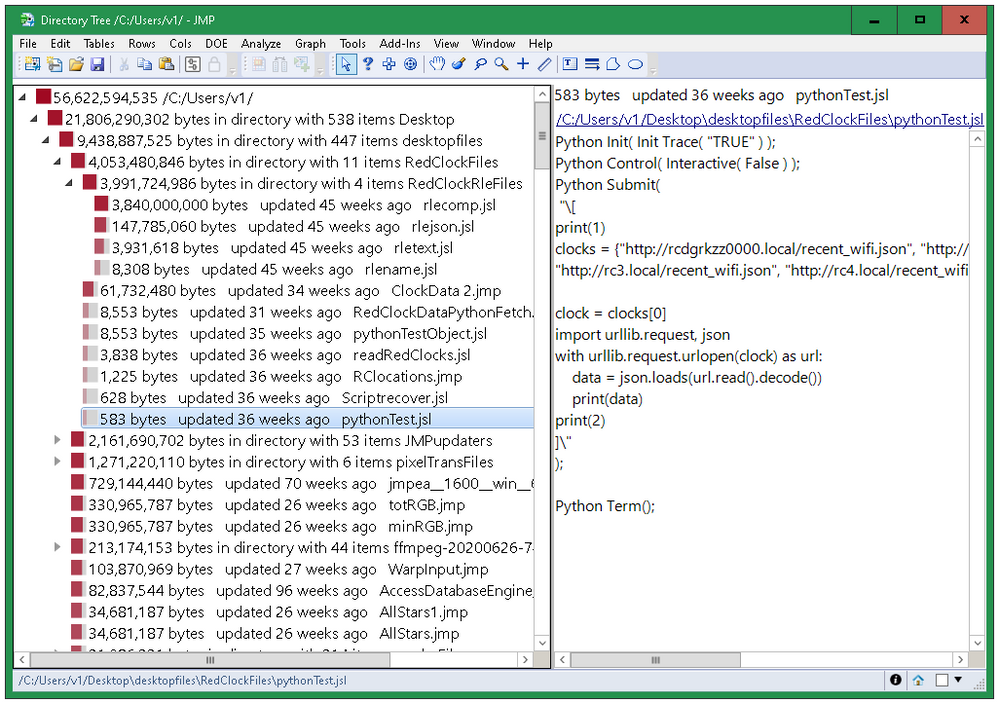
Directory Tree: Explore Space Used by Folders
See which folders are using the most space.
 Craige_Hales
Craige_Hales
1005 views
|
5 replies
 wendytseng
wendytseng
 WesleySantos
WesleySantos Bill_Worley
Bill_Worley
 Masukawa_Nao
Masukawa_Nao
 Byron_JMP
Byron_JMP
 Dahlia_Watkins
Dahlia_Watkins
 Ryan_Lekivetz
Ryan_Lekivetz



 anne_milley
anne_milley

 sseligman
sseligman

 MikeD_Anderson
MikeD_Anderson
 DaeYun_Kim
DaeYun_Kim
 LandraRobertson
LandraRobertson