Unlock the Power of DOE
This six-part web series was designed to help you unlock the power of design of experiments (DOE). For those new to DOE, the series will help you unde...
 scott_allen
scott_allen
1836 views
|
2 replies

 Craige_Hales
Craige_Hales
 wendytseng
wendytseng
 WesleySantos
WesleySantos Bill_Worley
Bill_Worley
 Masukawa_Nao
Masukawa_Nao
 Byron_JMP
Byron_JMP
 Dahlia_Watkins
Dahlia_Watkins
 Ryan_Lekivetz
Ryan_Lekivetz



 anne_milley
anne_milley

 sseligman
sseligman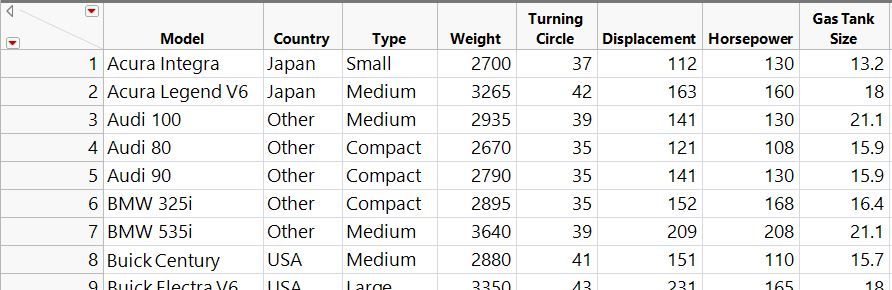

 MikeD_Anderson
MikeD_Anderson
 DaeYun_Kim
DaeYun_Kim
 LandraRobertson
LandraRobertson