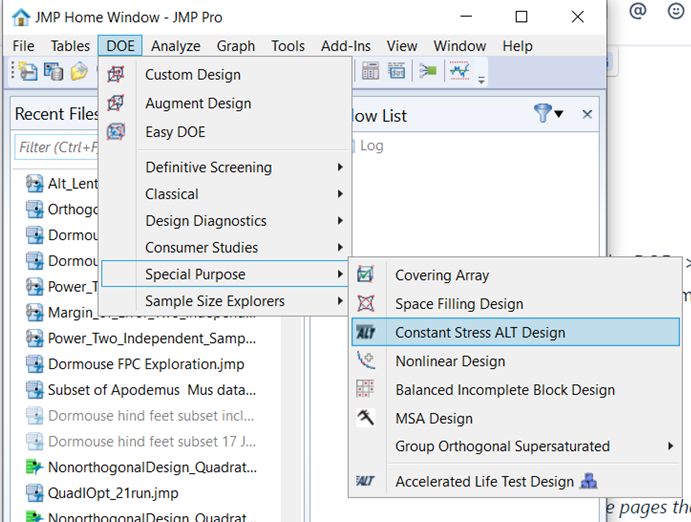
Level up your Python game with JMP
Do you use JMP and Python? Are you using them independently? Python for certain things…JMP for others? Did you know that there are many ways they work...
 wendytseng
wendytseng
77 views
|
0 replies

 Bill_Worley
Bill_Worley
 Dahlia_Watkins
Dahlia_Watkins sseligman
sseligman
 MikeD_Anderson
MikeD_Anderson
 yasmine_hajar
yasmine_hajar Paul_Nelson
Paul_Nelson Valerie_Nedbal
Valerie_Nedbal
 MaryLoveless
MaryLoveless
 SamGardner
SamGardner
 haleyyaremych
haleyyaremych
 AnnieDudley
AnnieDudley

 chris_gotwalt1
chris_gotwalt1
 jordanwalters
jordanwalters
 Daniel_Valente
Daniel_Valente

 bradleyjones
bradleyjones
 Duane_Hayes
Duane_Hayes
 gail_massari
gail_massari