Opções de gráficos no JMP usando o Graph Builder
Aprenda neste vídeo como acessar gráficos no JMP e usar o graph builder para construir gráficos interativos.
 WesleySantos
WesleySantos
22 views
|
0 replies


 Katie-Beth_V
Katie-Beth_V
 wendytseng
wendytseng

 scott_allen
scott_allen
 Craige_Hales
Craige_Hales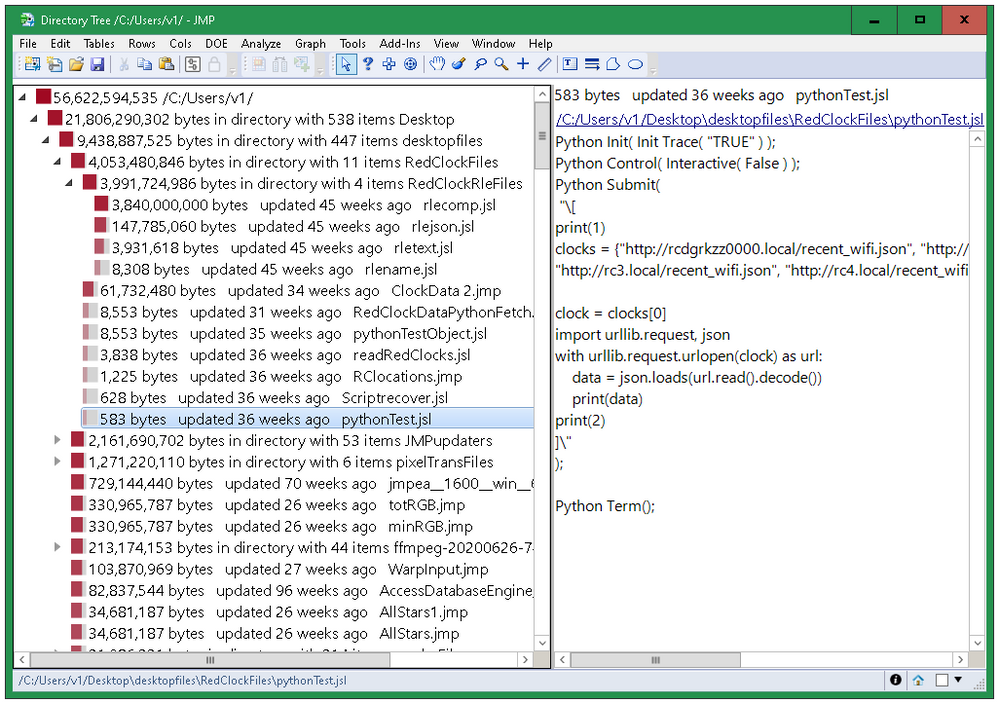
 Bill_Worley
Bill_Worley
 Masukawa_Nao
Masukawa_Nao
 Byron_JMP
Byron_JMP
 Dahlia_Watkins
Dahlia_Watkins
 Ryan_Lekivetz
Ryan_Lekivetz



 anne_milley
anne_milley
