Teaching with JMP Student Edition: AI enters the classroom - opportunities for instructors
Students can produce statistical output faster than ever. Evaluating it is a different skill — and that's where the real teaching challenge lies. Episode 2 of my series on AI in the statistics classroom: what changes, what helps, and what's actually on the instructor.
 volker_kraft
volker_kraft
27 views
|
0 replies


 Masukawa_Nao
Masukawa_Nao
 Craige_Hales
Craige_Hales
 Richard_Zink
Richard_Zink
 Byron_JMP
Byron_JMP
 dieterpisot
dieterpisot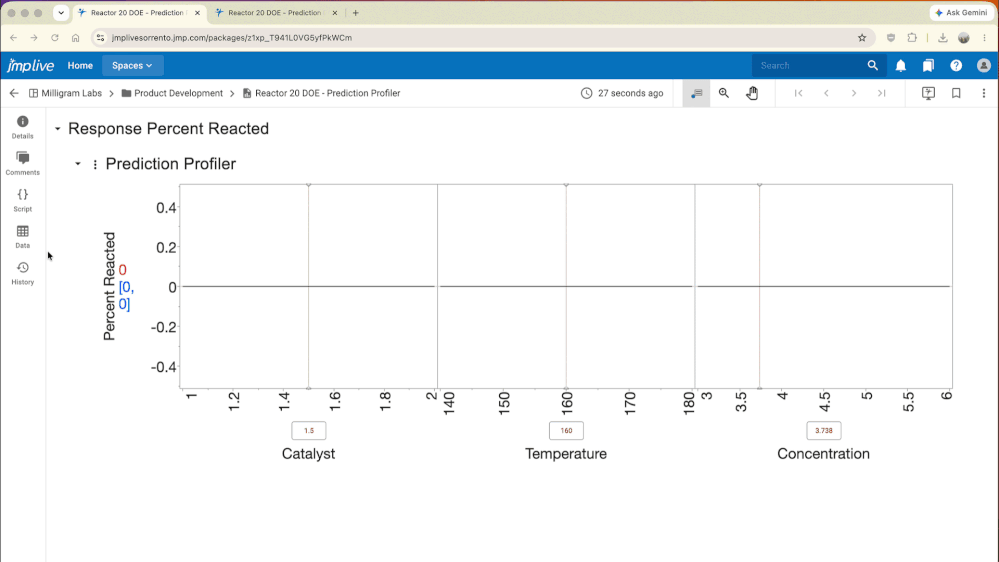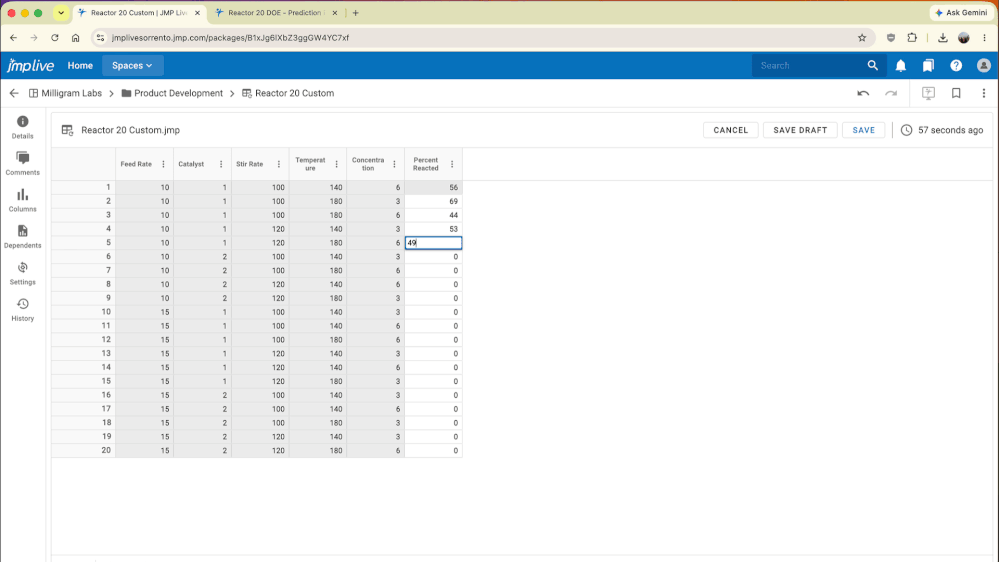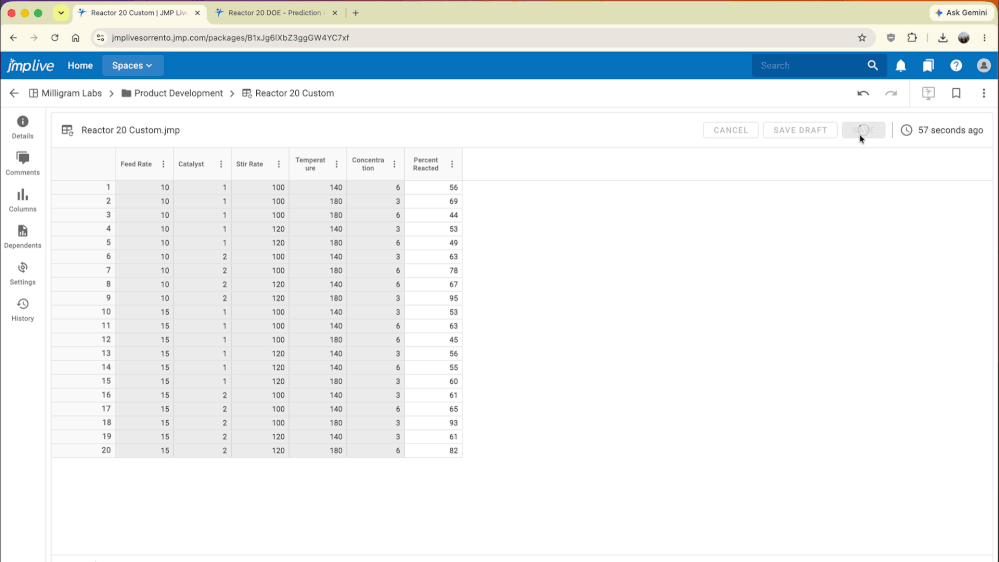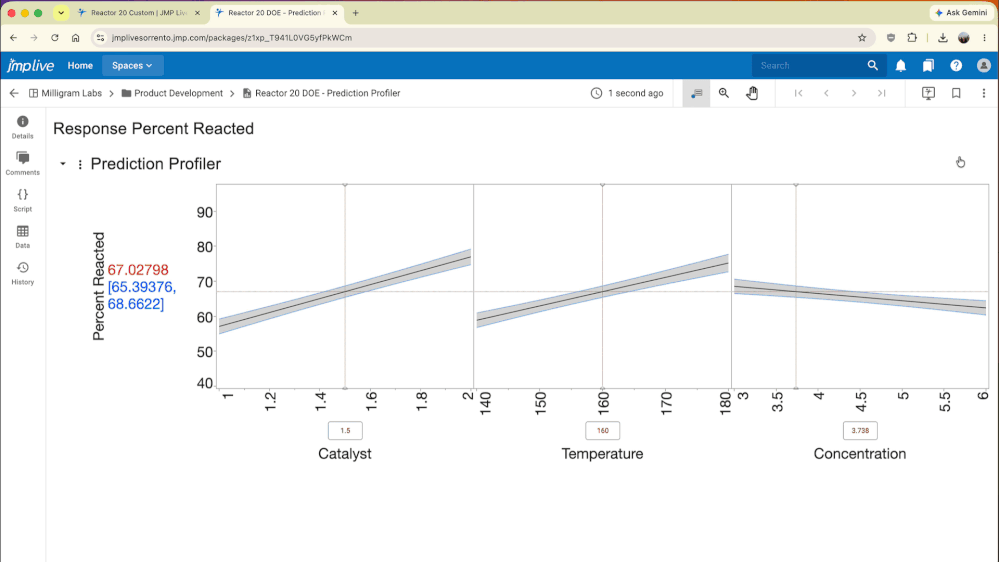
 Wendy_Murphrey
Wendy_Murphrey
 MikeD_Anderson
MikeD_Anderson
 Victor_G
Victor_G




 Jed_Campbell
Jed_Campbell

 anne_milley
anne_milley


