- Instantly extract effect sizes, F-ratios, and FDR-adjusted p-values from your models with the Calculate Effects Sizes extension, available now in the JMP Marketplace!
- New to JMP? Join us Sept. 23-24 for the Early User Edition of Discovery Summit, tailor-made for new users. Register now for free!
- Your voice matters! Tell us how you prefer to receive JMP updates, so we can tailor our communication to your needs. Take short survey.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Discussions
Solve problems, and share tips and tricks with other JMP users.- JMP User Community
- :
- Discussions
- :
- Re: How do I write the data table with repeats and replicates

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
How do I write the data table with repeats and replicates
I am doing a response surface methodology with an entire design replication. I have collected the data and have repeats for each run. Hence I was wondering on the data structure for inputting the repeats in JMP. Minitab structure is to input the repeats in each column. Is this the same for JMP?
Thanks

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: How do I write the data table with repeats and replicates
Hi @sianghongtay22,
It seems you're using replication and repetition indifferently, but these two terms refer to different techniques in DoE that can be used in combination:
- Repetition is about making multiple response measurements on the same experimental run (same sample without any resetting between measurements). Repetitions only reduce the variation from the measurement system (by using the average of the repeated measurements for example).
Your datatable will be structured by adding several columns for each response, corresponding to the repetitions of the measurement on the same experimental unit. You can then combine these columns of results by adding a calculated column of the mean, median, or any other aggregated measure. - Replication is about making multiple independent randomized experimental runs (multiple samples with resetting between each runs) for each treatment combination. Replications reduce the total experimental variation (process + measurements) in order to provide an estimate for pure error and reduce the prediction error (with more accurate parameters estimates).
You can replicate an entire design by using the platform Augment Design and choosing the option "Replicate" after entering the factors and responses in the windows panel : Replicate a Design
In the Custom Design platform, you also have the option to choose a number of runs that will be replicated (called "Replicate Runs"). This does not replicate the entire design, but chooses the optimal design points to replicate : Design Generation
The result of replication is the addition of new experimental units in the design (= rows), with same treatment combinations as other previous runs. The order should be randomized.
I hope this answer clarify the differences between the two and how to structure your table depending on your choices of replication and/or repetitions,
"It is not unusual for a well-designed experiment to analyze itself" (Box, Hunter and Hunter)

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: How do I write the data table with repeats and replicates
Some clarification/augmentation to Victor's response. It is important to think of experimental units when using the terms repeats and replicates.
For repeats, there is 1 experimental unit for each treatment combination. That experimental units is measured multiple times. How those repeated measurements are taken will affect which components of variation are quantified. For e\xample, if the experimental unit is a batch, you could measure the exact same sample from the batch multiple times and this would likely capture the measurement variation. If you sample the batch twice and measure each sample once, you would estimated both the within batch and the measurement variation (confounded).
For replicates, you will have multiple experimental units for the same treatment combination. These may be randomized or collected in blocks. Replication does not necessarily reduce the variation (in fact it may be quite the opposite). For example, if the replicates are done over changing lots of raw material and raw material effects variation, you will actually increase the variation in the experiment. Replication done randomly does allow for an estimation of the experimental error (hopefully with less bias providing a more robust statistical test), increases the inference space, however not can compromise precision. It does not allow for the assignment of the error. Replicates run in blocks, has the advantage of increasing inference space and increasing precision of the experiment (the block effect is accounted for in the model). In addition, blocks treated as fixed effects, has the advantage of assigning the experimental errors.
Now for your questions:
There is no context for your situation, so it is impossible to provide specific advice. However, to set-up the JMP table, you need a separate row for each replicate. I add extra columns for repeats (for each row). To analyze, stack (Tables>Stack) the repeat columns, assess consistency and then summarize the repeat data if appropriate (Tables>Summary>Mean & Variance). Analyze the summary data.

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: How do I write the data table with repeats and replicates
Hi Sir, based on your explanation, can you help me break down some things, such as what would be my experimental run in the attached table, is it repeated design or replicated design. Just to clarify some things, material and thickness are not the factors of the design. They are just the samples which I want to run test on. So for example, I want to run 4 identical experimental runs(----+) on 4 parts but the combination of 4 parts is different [(ply,0),(bly,-10),(ply,-10) and (bly,0)]. So, is this a replication or repeated measurement? If I would have perform the exact experiment(----+) on the same combination of 4 parts[(ply,0),(ply,0),(ply,0) and (ply,0)], then what would be my design called, a repeat or replicate. So in the photo attached, I am performing 4 experimental runs with the exact same settings(----+) but I am running those on different combination of parts.[(part 1 - PLY,0), (part 2 - BLY,-10), (part 3-PLY, -10) and (part 4- BLY,0)]. I hope the information provided is sufficient to answer my question whether the design is repeat or replicate.
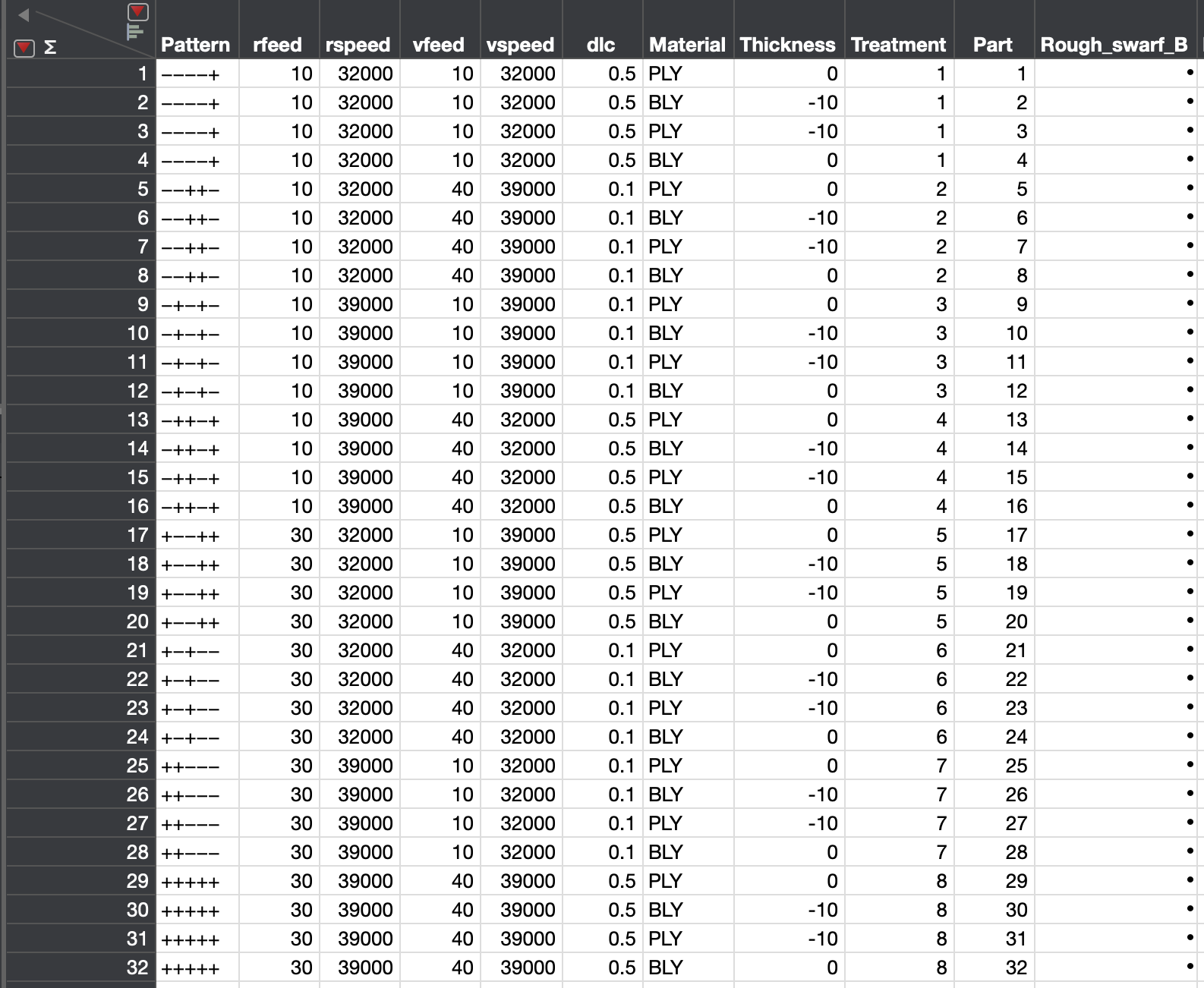{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: How do I write the data table with repeats and replicates
And also if this is repeat design then should not I collect my data across the rows?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: How do I write the data table with repeats and replicates
Here is the key...If you do not change or re-setup the treatment combinations and get "multiple data points" (this could be multiple parts, multiple measures of the same part in different locations, multiple measures of the same part in the same location, etc.), those data points are NOT considered independent events. They are considered repeated measures. They do not add DF's to the design. I'm using the words "data points" because there is not a universally agreed upon label for those measures.
If I interpret your question appropriately, those are repeats, not replicates.
To answer your question below, I would capture the repeats as additional columns. If you add rows, JMP thinks they are additional independent runs of the experiments and considers them additional DF's. Once the additional columns are captured, I would first stack those columns and graph the within treatment data and also look for unusual data points (perhaps a range chart). If there are no unusual data points, then you can summarize those rows by treatment (as you have numbered) using the appropriate summary statistics (e.g., mean, variance). Use Tables>Summary. Then you are back to the appropriate DF's for the experiment for proper analysis.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: How do I write the data table with repeats and replicates
Thank you so much sir, appreciate a lot! You cleared all my doubt. A very big thank you!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: How do I write the data table with repeats and replicates
My pleasure. I'm glad that helped. Happy experimenting...
Recommended Articles
- © 2026 JMP Statistical Discovery LLC. All Rights Reserved.
- Terms of Use
- Privacy Statement
- Contact Us