- Instantly extract effect sizes, F-ratios, and FDR-adjusted p-values from your models with the Calculate Effects Sizes extension, available now in the JMP Marketplace!
- New to JMP? Join us Sept. 23-24 for the Early User Edition of Discovery Summit, tailor-made for new users. Register now for free!
- See how to use the JMP Marketplace – Free tools to expand JMP capabilities. Register. July 10, 2 pm US Eastern Time.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Discussions
Solve problems, and share tips and tricks with other JMP users.- JMP User Community
- :
- Discussions
- :
- count unique

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
count unique
Hi, I have a table with transaction data like the below.
transactionID, individualID, product
1, a, apple
2, a, orange
3, b, apple
4, b, banana
5, c, orange
I want to do in tabulate, not using script, to count how many unique individualID by product.
Does anyone know how to do this?
I can do summary table using individualID and product first, and then do a tabulate on it to get the uniqueID count by product, but this is 2 steps. Wondering is there a way we can do it in tabulate just one step cause i constantly need to do this for many different groups?
Thank you!
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: count unique
I am unsure of how to use Tabulate to do this, but if you're open to using another platform, this is really easy to do using the JMP Query Builder:
1) Select Tables > JMP Query Builder from the main menu.
2) In the ensuing window, click the "Build Query" button, located in the window's lower right corner.
3) In the ensuing window:
- Double-click on the product column, casting it into the "included columns" pane.
- Double-click on the individual ID column, casting it into the "included columns" pane.
- Right-click on the t1.product column, now in the "included columns" pane, and select "Order By".
- From the drop-down menu in the t1.individualID column's Aggregation field in the "included columns" pane, select Count DISTINCT.
- At the bottom of the window, click "Run Query", producing a table with what I believe you are after. (?)
Cheers,
Brady

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: count unique
One more option is to calculate that in your original data table using a column with the col sum() function with a 'by' variable, but referencing the number 1 instead of a column, which turns it into a 'count' function. If you need it in the tabulate or table format, you could then tabulate using an average or median:

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: count unique
I am unsure of how to use Tabulate to do this, but if you're open to using another platform, this is really easy to do using the JMP Query Builder:
1) Select Tables > JMP Query Builder from the main menu.
2) In the ensuing window, click the "Build Query" button, located in the window's lower right corner.
3) In the ensuing window:
- Double-click on the product column, casting it into the "included columns" pane.
- Double-click on the individual ID column, casting it into the "included columns" pane.
- Right-click on the t1.product column, now in the "included columns" pane, and select "Order By".
- From the drop-down menu in the t1.individualID column's Aggregation field in the "included columns" pane, select Count DISTINCT.
- At the bottom of the window, click "Run Query", producing a table with what I believe you are after. (?)
Cheers,
Brady

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: count unique
It seems like Tabulate platform doesn't behave nicely with Character datatype for analysis. You could change individualID to numeric (recode or create formula to new column) and then use tabulate:

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: count unique

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: count unique
Thank you very much. This is the most efficient way to generate table results for counting unique values and proportions.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: count unique
Thank you so much Brady!
Never used this query builder and it's super powerful!
I just tried taking 2 source tables and did query, and it's so smart that it matched the individual ID on its own and returned the correct unique counts.
2 questions to the query builder:
1. I could see 3 green triangles as attached after I ran the above query. To re-run the same query with updated data, which triangles should I use?
2. If I have many different queries, how do I store them in one place, and then later when I got the latest data, to apply the queries on it again?
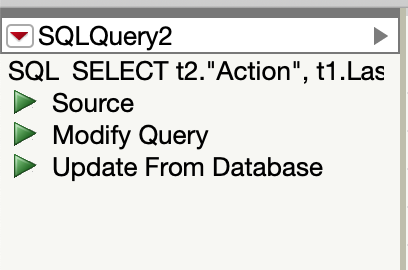{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: count unique
I could see 3 green triangles as attached after I ran the above query. To re-run the same query with updated data, which triangles should I use?
It depends... The "Source" script produces a new table when run, while the "Update From Database" script refreshes the present table (i.e., without creating a new table.)
Note: A handy feature of JMP data tables is that if you name a script "On Open", it will run whenever the JMP data table containing it is opened. So, you can rename the "Update from Database" script to "On Open" to assure that you're always starting off with updated results. Of course, this script can still be run whenever you wish, by clicking the green arrow.
If I have many different queries, how do I store them in one place, and then later when I got the latest data, to apply the queries on it again?
There are several ways to address this, I'll offer a couple of the easiest.
- You could use the "On Open" trick mentioned above if you have simple queries with no derivative dependencies. (i.e., no single query needs to be run prior to any other, to obtain correct results for its table)
- You could create a "master" script, by copying + pasting each of the scripts into it. The order may or may not matter, depending on your situation, and you may need to insert controls into the script to make sure results from prior queries are finished before proceeding.
I've not had to do much of this in practice, so it might be worthwhile to ask the community this question in a new discussion, to see what are actually the most popular approaches "in the field", and why.
Cheers,
Brady
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: count unique
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: count unique
One more option is to calculate that in your original data table using a column with the col sum() function with a 'by' variable, but referencing the number 1 instead of a column, which turns it into a 'count' function. If you need it in the tabulate or table format, you could then tabulate using an average or median:
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: count unique
Recommended Articles
- © 2026 JMP Statistical Discovery LLC. All Rights Reserved.
- Terms of Use
- Privacy Statement
- Contact Us