- New to JMP? Join us Sept. 23-24 for the Early User Edition of Discovery Summit, tailor-made for new users. Register now for free!
- Your voice matters! Tell us how you prefer to receive JMP updates, so we can tailor our communication to your needs. Take short survey.
- See how to access JMP Marketplace - and - find, create & share add-ins to extend your JMP. Watch video.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Discussions
Solve problems, and share tips and tricks with other JMP users.- JMP User Community
- :
- Discussions
- :
- Need help with Mutivariate model

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Need help with Mutivariate model
Hello,
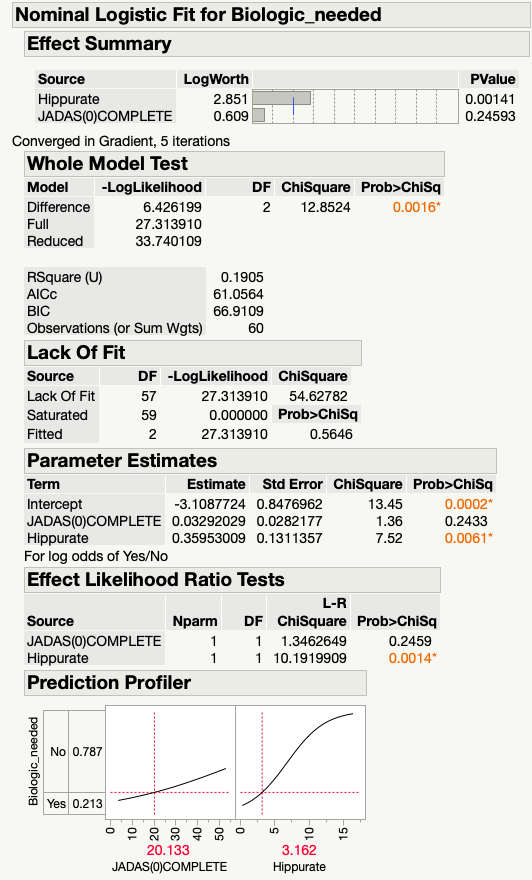
I have two continuous and one categorical variable., running it on JMP Pro 16, (attached the output file from the run), as an input I provided Y as the categorical variable (YES/NO) and, construct model effect as two continuous variable, Personality : Nominal logistic, and Target level : YES
- Firstly, wanted to know that running a Nominal logistic regression model a good option.
- Secondly, how do I find the dependency, means are two continuous variable independently associated with categorical variable , or is there interdependence ?
- Thirdly, how to find if two continuous variables are collinear with each other, without loosing significance.
{kind=link}
- Tags:
- macOS

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Need help with Mutivariate model
Hello @Kumar_Amar,
Welcome in the Community !
I will try my best to answer your questions :
- There is no right or wrong option. However, when trying to explain/understand or predict a categorical response, a nominal logistic regression can be a good starting point, and may help provide a simple model baseline to compare with other modeling options. Moreover, since you only have two possible variables to explain/predict your categorical response, starting with a simple model is a good idea. The choice of the model is linked to various parameters that may help you define what is the "right" choice for you. Here are some questions that may help you refine your questions and goals :
- Question and goal : Is the focus more on prediction (and tree-based model like decision tree/boosted tree or random forest may be helpful) or explanation (with statistical model and significance evaluation) of this classification based on the two factors ?
- User : What is your experience and "background" in modeling and your expectations regarding the performances you would like to achieve (statistical frequentist, bayesian, machine learning, ... mindsets) ?
- Data : Is the data "fixed" or will you acquire more data in the future you would like to classify ? Is the data representative of your system/study case ? How many samples/observations do you have ? Does the data comes from a designed experiments (DoE) or is it collected without any predefined plan ? How balanced is the data between the YES/NO classes ?
- Performance : How do you measure performance on this use case ? Any preference in metrics (precision, recall, F1-score, ...) or any differences between wrong predictions : maybe false positives represent a bigger cost than false positive (or inversely) ? A look at the complete confusion matrix may help to determine where the model makes errors in the classification and may inform about where to set the decision threshold depending on the data imbalance and relative cost of the errors.
- and 3. You can see the dependency between your variables in different ways, but the easiest options might be to use Graph Builder to plot X1 vs. X2 and see if you have any correlations, or use the Multivariate Platform to check correlations between each pair of continuous variables. You can also check individual relations between your categorical response and each of your continuous variable with the Fit Y by X platform.
Finally, in situations involving more variables, you can also check VIF scores. There are several good options listed in the following discussions :
test for colinearity - JMP User Community
Solved: Check for multicollinearity in Ordinal logistic regression - JMP User Community
I hope this answer will help you :)
"It is not unusual for a well-designed experiment to analyze itself" (Box, Hunter and Hunter)
Recommended Articles
- © 2026 JMP Statistical Discovery LLC. All Rights Reserved.
- Terms of Use
- Privacy Statement
- Contact Us