- Instantly extract effect sizes, F-ratios, and FDR-adjusted p-values from your models with the Calculate Effects Sizes extension, available now in the JMP Marketplace!
- New to JMP? Join us Sept. 23-24 for the Early User Edition of Discovery Summit, tailor-made for new users. Register now for free!
- Your voice matters! Tell us how you prefer to receive JMP updates, so we can tailor our communication to your needs. Take short survey.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Discussions
Solve problems, and share tips and tricks with other JMP users.- JMP User Community
- :
- Discussions
- :
- Choosing factors in model building with forward stepwise regression

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Choosing factors in model building with forward stepwise regression
Hello!
I am using JMP 13 in my master's thesis in order to build a statistical model. I am new at building models, so I apologize in advance if my questions seem a little basic, but any kind of help would really mean a lot to me.
In my master's thesis, I did a Definitive Screening Design (6 factors + 2 fake factors, 7 responses, 17 runs) in order to study some process. After completing all the experiment and analysis necessary, I analyzed the gathered data with two analytical methodologies proposed by Jones and Nachtsheim in 2016 (Effective model selection for DSDs (EMS) method or Forward stepwise regression (FSR)). They say that EMS is generally preferred, but FSR performs adequately if the number of active effects is no more than half the number of runs and there are at most two active two-way interactions or at most one active quadratic effect (DOE Guide p. 257). These conditions hold for all of our responses.
I have some questions regarding selecting factors for model building with the FSR method. I did the FSR with the following conditions:
Stopping Rule: Minimum AICc
Direction: Forward
Rules: Combine
FSR chose some factors and I made a model with standard least squares.
So here is my first question:
In Effect Summary (See the photo Effect Summary 1 below) I noticed, that factor Temp (5,25) has a PValue 0,16260. I know that this factor is included because of the combine rule (Temp. is included in interaction Konc.lakt*Temp. which has a PValue under 0,05). Is it necessary for the model that Temp. is included or can I build a model without it, although Temp. is included in interaction? If Temp. is removed, JMP keeps warning me, that Temp. is missing.
I also noticed that it doesn't change the model much if I delete Temp. as a factor, which makes sense because of the high PValue, which I understand as a sign that the factor is insignificant. (or am I wrong?). The PValues of other included factors changed as well, so now factor Konc.lakt also had a PValue larger than 0,05 (should I excluded it as well?).
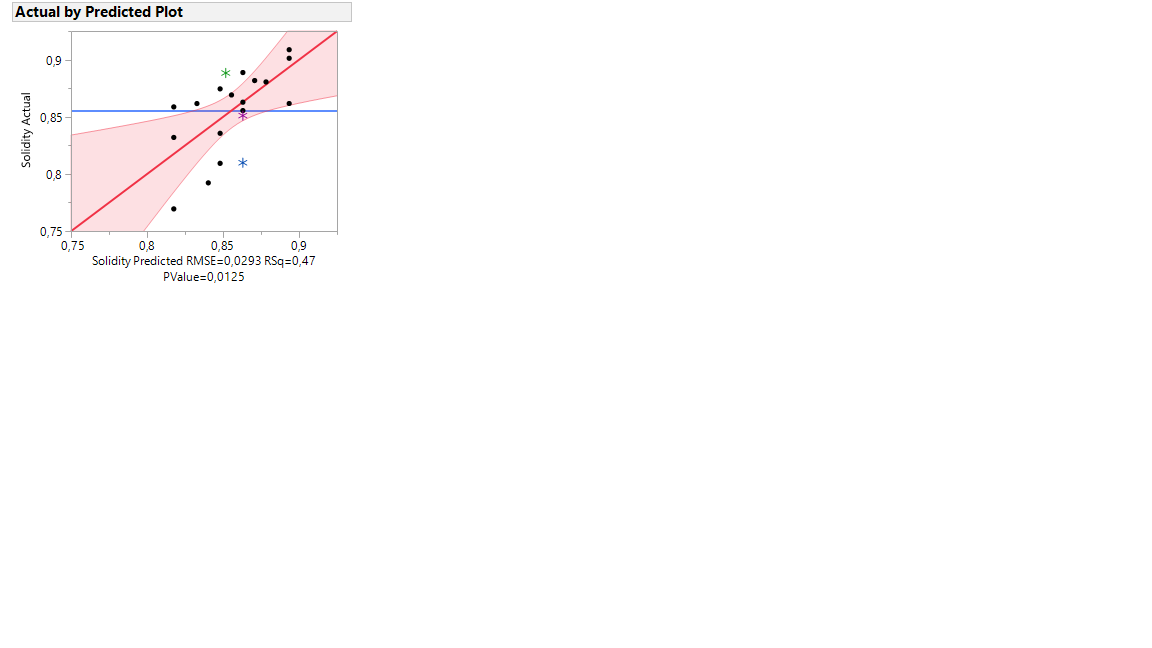
I compared the models. (See photos below: Actual by predicted plot 1 for reduced model and Actual by predicted plot 2 for not reduced model). I compared the model with all the effects on the picture Effect Summary 1 and the model with only factors which have PValue lower than 0,05 (See photo Effect summary 2). The models seem very similar, the model with more included effects has a little better fit (which makes sense), but not very much, residual analysis is also very similar and points from additional experiments, which were not used to make a model (blue, purple and green stars) are in the similar positions. Is it right, that I keep the less active effects in the model? I don't think so, since these effects don't change the model much, so including them could be misleading and we could overfit the model. Or am I perhaps wrong?
If I look at another response, where I get only one factor with value lower than 0,05, then adding another factor to the model improves model a bit more than in previous example, (better fitting, better residual analysis) but still not very much (See photo below: Actual by predicted plot 3 for not reduced model and Actual by predicted plot 4 for reduced model). Do things change if we are left with only one factor in the reduced model?
Thank you for all your answers and effort in advance.
Danijel
.png){kind=link}
.png){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Choosing factors in model building with forward stepwise regression
For your first question, it's not an absolute necessity but that combine rule is meant to respect the Effect Heredity principle. It's generally bad practice to remove main effects and leave interactions that contain that effect in the model. That being said, if you do remove it, you are effectively saying the average effect of Temperature across all other factor levels is 0, but that the effect size can be non-zero depending on the level(s) of other factors (through the interactions).
If factors have a high degree of correlation with each other, p-values can change dramatically depending on what comes in and out of the model. Since you did a DSD, your main effects should all be completely orthogonal, so I don't think that's what's going on with Konc.lakt. Alpha-levels are not sacred. It's ok to use your judgement if the p-value is marginal.
Another piece of advice I'd give you is to be generous with alpha for this type of design. DSDs don't have the greatest statistical power because they are generally very economical designs. It would be pretty easy to cut a few factors that actually do matter. I'd rather be overfit than underfit. Your model seem underfit in Actual by Predicted 4. It's also a good idea to do confirmation runs on a few different points within your design space to make sure your model provides reasonable predictions.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Choosing factors in model building with forward stepwise regression
For your first question, it's not an absolute necessity but that combine rule is meant to respect the Effect Heredity principle. It's generally bad practice to remove main effects and leave interactions that contain that effect in the model. That being said, if you do remove it, you are effectively saying the average effect of Temperature across all other factor levels is 0, but that the effect size can be non-zero depending on the level(s) of other factors (through the interactions).
If factors have a high degree of correlation with each other, p-values can change dramatically depending on what comes in and out of the model. Since you did a DSD, your main effects should all be completely orthogonal, so I don't think that's what's going on with Konc.lakt. Alpha-levels are not sacred. It's ok to use your judgement if the p-value is marginal.
Another piece of advice I'd give you is to be generous with alpha for this type of design. DSDs don't have the greatest statistical power because they are generally very economical designs. It would be pretty easy to cut a few factors that actually do matter. I'd rather be overfit than underfit. Your model seem underfit in Actual by Predicted 4. It's also a good idea to do confirmation runs on a few different points within your design space to make sure your model provides reasonable predictions.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Choosing factors in model building with forward stepwise regression

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Choosing factors in model building with forward stepwise regression
Danijel,
Does your test method for your responses, namely, roundness and solidity have adequate capability? If you analyzed your samples multiple times on the same day and over time, do you get reproducible results. I am curous since often we find that many signals rise from the noise once we have our test method noise understood.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Choosing factors in model building with forward stepwise regression
That is a good point. I think so, but I will have to check it. The model looks much better on some other responses, I actualy picked the worst two models, because I am wondering how could I make these models better. Response solidity was measured out of curiousity and it should came out as a good or bad anlytical method. I guess the method is not that good...
I was also thinking what could be done to improve the model. I guess if the analytical method is bad, there is not much to do beside repeating measurments. Could I also try building a model with some other method than Standard least squares, for example Loglinear variance? Could I improve my model with doing some more experiments and if yes, how can I choose the factor values that the model will improve the most (if that is even possible)? Is there any other way to improve the model?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Choosing factors in model building with forward stepwise regression
Many times response tests (measurements) are run a number of times (3) and the resulting response is averaged to reduce the error contributed by the measurement system.
You may also want to check out JMP Help for information on Model transformation
Fitting Linear Models > Standard Least Squares Report and Options > Factor Profiling > Box Cox Y Transformation
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Choosing factors in model building with forward stepwise regression
Yes, I did that for my every measurment. I also did transformations when it was appropriate (better data fit and better residual analysis). What do yout think about my other proposals for improving the model?
Recommended Articles
- © 2026 JMP Statistical Discovery LLC. All Rights Reserved.
- Terms of Use
- Privacy Statement
- Contact Us