- JMP will suspend normal business operations for our Winter Holiday beginning on Wednesday, Dec. 24, 2025, at 5:00 p.m. ET (2:00 p.m. ET for JMP Accounts Receivable).
Regular business hours will resume at 9:00 a.m. EST on Friday, Jan. 2, 2026. - We’re retiring the File Exchange at the end of this year. The JMP Marketplace is now your destination for add-ins and extensions.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Discussions
Solve problems, and share tips and tricks with other JMP users.- JMP User Community
- :
- Discussions
- :
- Adding a complex constrain to a Custom Design with 4 factors

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Adding a complex constrain to a Custom Design with 4 factors
Hello,
I am creating a Custom Design with 4 factors (Factors A, B, C & D).
I have a question about a constraint that has to do with factors B and D.
- Factor B is actually the number of reactions done in sequence in the same experiment. This can be 1 reaction, 2, 3 or more reactions in sequence. I set the range as 1-3 (not higher because I am not interested at the moment in >3 reactions in sequence).
- Factor D is the time I wait in between the reactions in sequence. Thus, I only define Factor D when Factor B is >1. The range is 0.1 to 10 seconds. Factor D would be 0 if Factor B is 1. In other words, when the number of reactions done in sequence (factor B) is just 1, Factor D doesn't exist because it was just 1 reaction and thus, I don't need to wait any seconds since there is no other reaction in sequence performed.
How can I define this constraint in my Custom Design model?
Thank youuuu!!
PS: I use a Mac.
{kind=link}
{kind=link}
- Tags:
- macOS
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Adding a complex constrain to a Custom Design with 4 factors
Hi @ADouyon,
Welcome to the Community !
Looking at your problem and options, here is what's recommended :
- First, define your factor B as a discrete numeric, because the number of reactions is a whole number (you can't have 1,7 reactions for example, only 1, 2 or 3 in your case study),
- Factor D should have a lower level fixed at 0 if you want to have a waiting time of 0 when there is only one reaction.
- Since Factor D (time) is in your design a continuous factor (you can have any reaction time you want in the range specified), I would recommend to add the quadratic term D*D in the model, since for (chemical) reactions, time has not often a linear relation with the yield/output.
- Depending if the response can be measured "online" without any degradation, perhaps it would make sense to record the response at several time intervals, in order to have a modelization of response vs. time (with the input factors) ?
- Last but not least, I'm not familiar with your topic, but choosing different settings for factors may also solve your problem (changing waiting time for reaction time for example).
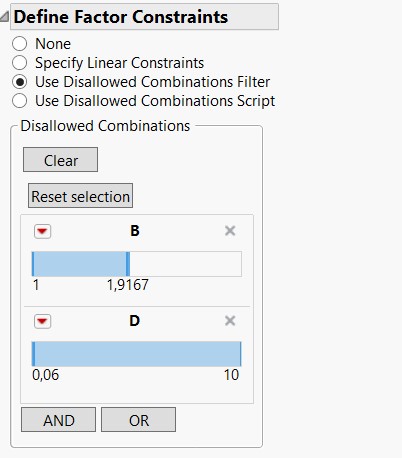
Based on your inputs, you can go into "Use Disallowed Combinations filter" ans select the range you want to exclude from your design (here, 1 =< B < 2 AND D > 0, see screenshot constraints for example). JMP should then offer you a design that adress this specific constraint (see screenshot Matrix and Experimental Space).
There may be better (and smarter) ways to do it, or more appropriate designs/factors configuration to think about this topic, but this should answer your needs and question.
I hope it will help you,
"It is not unusual for a well-designed experiment to analyze itself" (Box, Hunter and Hunter)
{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Adding a complex constrain to a Custom Design with 4 factors
Hi @ADouyon,
I'm glad this first answer helped you.
Concerning your other questions :
- On the second screenshot, it seems that the two constraints are well specified. I also forgot to do it myself in my first answer, but you can change the format of your B factor in the filter constraint by clicking on the red triangle, then "Modeling type" = Categorical/Ordinal : this is easier to create constraints and avoid using things like 0<= B < 1,99 when we simply want to have B fixed at 1 (see screenshot constraints2). Looking at your design matrix and mine, constraints seem to have been respected, so it should work fine.
- Yes, you should keep it, since JMP adds it and specifies its estimability as "If Possible" by default so it won't require more runs, but the runs will be better organized in the experimental space, so that in case you have enough degree of freedom in you model, JMP will try to estimate the quadratic term of your discrete numeric factor. And compared to a Categorical factor, having a Discrete Numeric factor means that JMP knows there is a relationship between the levels (they are ordered), compared to a pure Categorical factor (no relationships between levels, levels are nominal). There was a video explaining the difference between Discrete Numeric and Categorical: Dear Dr. DOE, isn’t Discrete Numeric just Categorical? - JMP User Community.
If you can afford more runs, I would suggest to add some replicate runs, to increase the power of your main effects (increasing the ability to detect a significant main effect if it is indeed present). You may have a severe experimental budget constraint, but comparing several design with several sample sizes can help you choose the most optimal situation for your needs.
I hope this follow-up will help you as well,
"It is not unusual for a well-designed experiment to analyze itself" (Box, Hunter and Hunter)
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Adding a complex constrain to a Custom Design with 4 factors
Hi @ADouyon !
I'm glad the answers were helpful. I don't know how common this practice may be, but I personnaly prefer to spend more time comparing different designs and sample sizes than going to the lab and do the experiments quickly, to finally see that I may have forgotten a constraint, or that my design is not well suited enough for my needs.
--> To illustrate this, I really like this quote of Ronald Fisher : "To consult the statistician after an experiment is finished is often merely to ask him to conduct a post mortem examination. He can perhaps say what the experiment died of."
Different designs may lead to different interpretations of the results, depending on which terms are in the different models. For example, screening designs with main effects only may help filter relevant factors for the follow-up of a study, but may clearly lack precision and response(s) predictivity in presence of 2 factors interactions and/or quadratic effects (possible lack of fit).
You have several options to generate different designs and compare them:
- Change (add/remove) the terms in the model (2 factors interactions, quadratic effects, ...) or their estimability (you can switch the estimability from "Necessary" to "If Possible" for 2FI and Quadratic effects).
- Vary the sample sizes (number of experiments) in the design by adding replicate runs : are the extra runs relevant and useful enough to have a gain on estimates precision or relative variance prediction over the experimental space ?
- Change the optimality criterion (depending on your target : D-optimality for screening, I-optimality for good response prediction precision, Alias-optimality to improve the aliasing between terms in the model...)
- Change the type of design (if possible !)...
For the moment, to compare different DoEs you have to create them in JMP and then go to "DoE", "Design Diagnostics", and then "Compare Designs". But ... Spoiler alert ! : In JMP 17, it will be a lot easier to compare several designs (see screenshots), as a "Design Explorer" platform will be included in the DoE creation, so no need to manually create them one by one : you can create several designs in seconds, and filter them based on your objectives and decision criteria.
And finally, take advantage of "iterative designs" and don't expect or try to solve all your questions with one (big) design. It may be more powerful and efficient to start small with a screening design for example, and then use Augmentation to search for more details, like interactions and possible non-linear effects. Finally, if your goal is to optimize something, you can once again augment your design to fit a full Response Surface Model. At each step, you gather more knowledge about your system, and make sure that the next augmented design will bring even more knowledge, without wasting experiments/runs, time and ressources.
"Augment design" platform is really a powerful (and often underestimated) tool to gather more data and gain more understanding and build more accurate models without losing any previous information.
I hope this answer will help you,
"It is not unusual for a well-designed experiment to analyze itself" (Box, Hunter and Hunter)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Adding a complex constrain to a Custom Design with 4 factors
One additional comment to mention a great ressource about the sequential nature of experiments, by Prism Training & Consultancy : Article: The Sequential Nature of Classical Design of Experiments | Prism (prismtc.co.uk)
This article explains very well the process behind DoE, from creating and assessing the experimental scope for factors, to screening and then optimization. This is part of a serie of article that may have an interest for you.
Happy reading !
"It is not unusual for a well-designed experiment to analyze itself" (Box, Hunter and Hunter)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Adding a complex constrain to a Custom Design with 4 factors
Hi @ADouyon,
It seems that you can save and load constraints only if it is done through the option "Specify Linear Constraints".
What you can do in your case, is
- to generate your DoE entirely with the constraint you added, and then you'll see that a new script in your datatable called "Disallowed Combinations" (see screenshot Disallowed_Combinations-datatable-script.jpg).
- If you right click on it, then click "Edit", you can copy the JSL code of the disallowed combinations (see Disallowed_Combinations-datatable-script-Edit.jpg) and...
- Use it (paste it) in the Custom Design creation, in the "Use Disallowed Combinations Script" option (see screenshot "Use-disallowed-combinations-script.jpg).
There might be a smarter and more automatic way to do this (via JSL scripting maybe ?), but this approach work (and you don't need to manually recreate your disallowed combinations).
Hope it will help you ! :)
"It is not unusual for a well-designed experiment to analyze itself" (Box, Hunter and Hunter)
{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Adding a complex constrain to a Custom Design with 4 factors
Hello @ADouyon,
For the factors that can't take any decimal value, you have two options :
- The first and easy one may be to change the numbers without decimal values in the datatable, by changing the format to "Fixed Dec" and Dec = 0 (see screenshot). But the design may lose a little bit of its optimality, and the optimal values for these factors from the model for the prediction profiler may have decimals.
- The other way is to treat those factors as "discrete numeric", with specified levels (see my previous comments for more info about Discrete Numeric factor type). This way looks better to me, as this "constraint" is directly taken into account in the model. In your case it might not be interesting to use all the possible levels of your equipment (with an increment of 1) in the levels of the discrete numeric factor, but choosing at least 3 levels (min, medium and max) may be interesting in order to look at possible quadratic effects. In the prediction profiler, it will be treated as categorical factor, but keeping in mind the ordinality of the levels (like 2 < 5 < 7 ... see screenshot for Factor 4), so you can have a look at the trend between each levels.
There might be other options to do it, so don't hesitate to create a new post and check for other users' inputs and responses.
At the end, choose the option you're the most confortable with.
Hope it helps you,
"It is not unusual for a well-designed experiment to analyze itself" (Box, Hunter and Hunter)
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Adding a complex constrain to a Custom Design with 4 factors
Hi again @ADouyon,
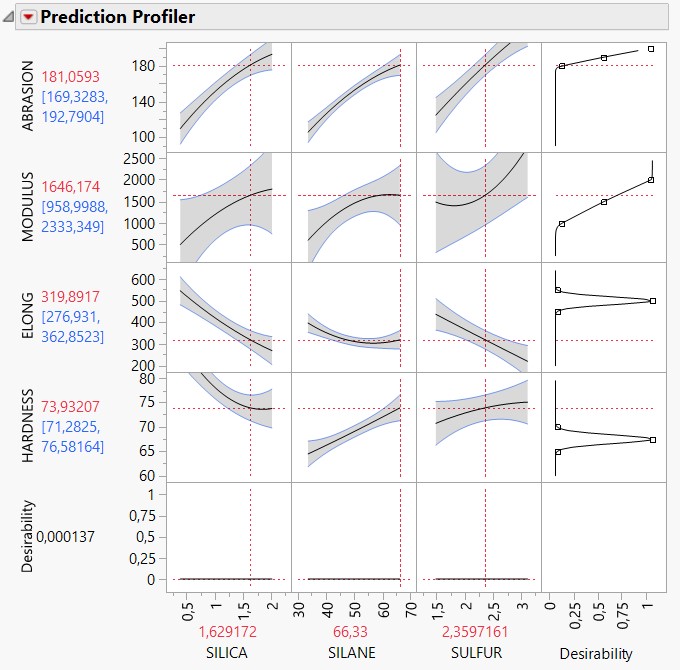
- The "lower limit" is the lowest acceptable solution for your situation (it defines a possible and acceptable range of values from your lowest limit to your highest limit), and may have an impact if you have several responses. In the case of an unique response, it doesn't matter much because JMP will either way try to optimize the response (maximize/minimize or match value), so the lower limit will be in any case avoided at all cost by finding the right factors settings (in the case of "Maximize"). The change will be in the slope of the desirability function (see screenshot Profiler-1 done with lower limit 350 and Profiler-2 done with lower limit 450 on the use case "Bounce Data" from JMP).
If you have several responses, changing the slope of one of your response desirability profile may change the optimum found, because JMP will try to maximize the overall desirability value (taking into account all responses desirabilities functions), so having a steeper slope for a response means that this response may have a bigger influence on the desirability optimization solution (because you'll reduce the range of acceptable values, see comparison of profiler optimization with screenshots Profiler-desirability-1 and Profiler-desirability-2 on the dataset Tiretread.jmp from JMP data use cases). Also take into account that the importance fixed for each of your response will also greatly influence the optimum found : the bigger the response importance, the bigger the influence of this response on the optimum situation found.
More infos on the desirability profile can be found here : The Desirability Profile (jmp.com) - The use and number of replicates is determined by your goal, power for effects, precision expected for your experiments/predictions, ... Be careful in JMP there are two options : "number of replicate runs" (in Custom Design), meaning here the number of run(s) to repeat, and "number of replicates" (in Classical Design), meaning he number times to perform each run (in addition to the original runs) : Re: Custom Design Number of Replicates - JMP User Community.
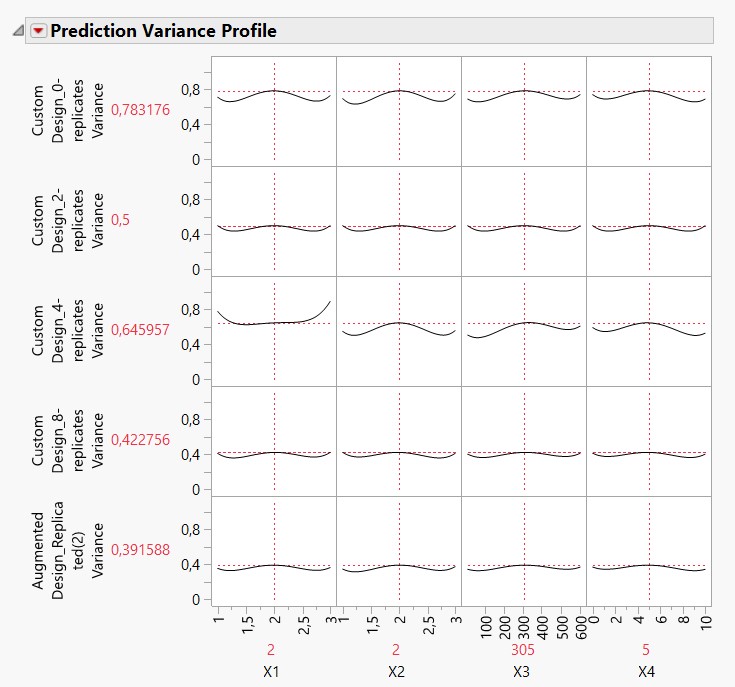
It's difficult without knowing all of this (and without domain expertise) to know what may be the more suitable choice for your case, but I would recomment to try different options (no replicate runs, 2 replicate runs, 4 replicate runs, 8 replicate runs...) and use the "Compare Designs" platform (found in DoE -> Design Diagnostics) to evaluate which number of runs would be optimal for your case (biggest impact for the lowest number of replicates). Attached you can find the different comparisons made with your DoE settings for 0, 2, 4 and 8 replicate runs for Power, Variance and Correlation comparisons, with the individual datatable created for each DoE. Here for 2 and 4 replicate runs, JMP ends up with the same default number of experiments (18) with similar properties for these designs. However, we can clearly see a gap between 0 and 2/4 replicate runs in terms of power, variance prediction profile (almost divided by a factor 2 in the case of 2 or 4 replicate runs compared to 0 replicate runs) and correlation matrix/color map (aliasing between terms in the model), so the 18 runs design (either 2 or 4 replicate runs) may be a good compromise here to have reliable results and precision without augmenting too much the experimental costs (27 experiments for a 8 replicate runs design !).
If you really want to compare with a duplicate/triplicate... design (to have replicates and not only replicate runs), you can create the original design proposed by JMP (with 9 experiments, without any replicate runs), and then augment it (in DoE -> Augment Design) by selecting the option "Replicate". JMP will then ask you the number of times to perform each run, so if you enter "2", you'll end up with your duplicate design with 18 runs. Note that in the case here, the two options (replicates and replicate runs) bring very similar design performances for the same number of runs (here tested with 18 runs in total). - I don't know precisely how to handle this. If you don't know in your experimental space which conditions will make your experiment succeed/fail, one option could be to test your experimental space first with a "Scoping design" (Scoping Designs | Prism (prismtc.co.uk)) to check if your factors conditions are possible in the lab (and then augment this design to a screening one, and perhaps after augment it to an optimization one with Response Surface models).
If you already know which factors conditions will make your experiment fail or succeed, you can perhaps include the settings and create appropriate runs in your DoE, and include or add these runs as well in your analysis, either as part of the design, or as validation points (excluded for the analysis of the design, but added at the end to check predictions of the design match your knowledge).
I hope these answers will help you (sorry for the long post),
PS: I have 9 runs in my original design with no replicate runs, this is because I didn't add the terms X1*X1 and X1*X2 in the model, but the general presentation and comparison of design may still be valid (you may have to verify to check it, if needed I can try to change the designs and provide a valid comparions and screenshots today).
"It is not unusual for a well-designed experiment to analyze itself" (Box, Hunter and Hunter)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Adding a complex constrain to a Custom Design with 4 factors
Hi @ADouyon,
With the correct designs and models, the comparisons are a bit different:
- For power, there seems to be no significant improvement between designs with no replicates runs, or 2 or 4 replicate runs. Having 8 replicate runs (for a total of 27 experimental runs) or replicate entirely the original design (for 36 experiments in total) does improve the power.
- For variance prediction, having 2 replicate runs (for the same number of total runs : 18) seems to lower more efficiently the variance over the entire space than with having 4 replicate runs (or none). Having 8 replicate runs (for 27 experiments !) does lower the prediction variance over the experimental space a little bit, but it is quite similar to what you get with 2 replicate runs. And for sure, if your replicate your original design (and double the number of experiments from 18 to 36...), your prediction variance will be divided by two.
- In terms of efficiencies and aliasing, replicating the entire design will give you the same aliasing/correlation between terms, whereas adding replicate runs can change and lower some aliasing. Efficiencies are quite similar for designs with the same number of runs, and will fore sure increase when you augment your number of experiments.
Hope this part will help you and not bring additional confusion,
"It is not unusual for a well-designed experiment to analyze itself" (Box, Hunter and Hunter)
{kind=link}
{kind=link}
{kind=link}
{kind=link}

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Adding a complex constrain to a Custom Design with 4 factors
There is a lot of information in the diagnostics outline. Some of it is more relevant at times. I am not saying that you should not look at everything, but we are generally somewhat selective in the information we use to compare the designs. Power, estimation efficiency, and correlation of estimates are more critical when I am screening factors or factor effects. On the other hand, prediction variance (profiled or integrated) is more acute when I am ready to optimize my factor settings based on model predictions.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Adding a complex constrain to a Custom Design with 4 factors
Hi @ADouyon,
Concerning this new feature in JMP 17, it should be available soon (late October - beginning November), according to the JMP website : New in JMP 17 | Statistical Discovery Software from SAS
There is already a fascinating and brilliant white paper of this new functionality (Design Explorer) available here, which promises very interesting use cases in the selection of an optimal design: Choosing the Right Design - with an Assist from JMP's Design Explorer | JMP
1- Exactly ! Sorry for not being clear, this is exactly what I meant : I prefer to create several designs on my computer with JMP, and choose the most relevant one according to the experimental budget, goal and constraints, instead of going into the lab with the first design created and figuring out later that I may have forgotten some constraints or that my experiments are not all feasible/possible.
2- Sure ! When you have created several designs and the corresponding datatables for each design, you can go to DoE -> Design Diagnostics -> Compare Designs. There, you can select all the designs tables (max 5 designs in total, so 4 selected + the design from where you have clicked on "Compare Designs") and match the factors if they have different names in the tables (if they have the same names like in your screenshot (x1 and x1, ...), JMP will figure out that they are the same, so you don't need to match each factor individually). You should then have the same view as I had. More infos here : Evaluate Design Window (jmp.com)
3- The "Design Diagnostic" informations are values that need to be compared with other designs in order to see the strengths and weaknesses of each design. Each efficiency can go from 0 to 100. Different efficiencies are mentioned:
- D-efficiency is linked to parameter estimation precision, and is very important in screening/factorial designs, to precisely estimate the significance and effect size of effects in the model,
- G-efficiency is linked to the minimization of the prediction variance over the entire experimental space, and is very important in optimization design (focussed more on predictive performance rather than in causal explanations / statistical significance),
- A-efficiency is linked to the minimization and optimization of aliasing between effects ; the highest the A-efficiency, the lower and more precise (and unbiased) will be the estimation of regression coefficients.
More infos here : Design Diagnostics (jmp.com)
4- Very good question, and I don't have a clear answer. This is presumably because of coordinate exchange algorithm (used for custom design) and random starting/generating points for the design. As the design is generated from random points in the design space, the optimal repartition of points in the experimental space may change from one design generation to another. Hence you can see some slight changes in the values when generating again the design. You can manually change these values to the closest value (here 2) without changing the optimality of your design too much, or try generate again the design, eventually by augmenting the number of random starts and/or the design search time (in the red triangle close to "Custom Design" you will find "Number of Starts" and "Design Search Time").
"It is not unusual for a well-designed experiment to analyze itself" (Box, Hunter and Hunter)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Adding a complex constrain to a Custom Design with 4 factors
Hi again @ADouyon,
As a first overview, yes you're correct : power (=probability of detecting an effect if it is really active) should be as high as possible, prediction variance and fraction of design space plot as low as possible. But as answered by @Mark_Bailey, you'll compare in priority with other designs what you need from your experimental plan (as having everything high/perfect is often not possible or at the cost of a very large number of experiments):
- If you're using a DoE to screen main effects (and perhaps interactions), you're not primarily interested in the prediction variance and fraction of design space, but rather in the detection of significant effects among your factors (and perhaps interactions). So you'll rather focus on power analysis.
- If you're using a DoE to optimize a process/formula, you would like to obtain predicted response(s) as precisely as possible, so you would like to have the lowest prediction variance. Hence, you'll compare with other designs the prediction variance over the experimental space and the fraction of design space plot.
You'll find some infos on Design Evaluation here (and in the following pages) : Design (jmp.com)
Yes, as my primary design for comparison was Custom-Design_0-replicates (with the lowest number of experiments and no replicates), most of the other designs performed better (either because they have replicate runs, so a similar or better estimation of noise/variance for the same number of experiments, or because they had a higher number of experiments (last 2 designs), hence improving all efficiencies) so the efficiencies of this simple design was worse compared to other designs (therefore the red values).
Changing the primary design in the comparison would have changed the relative efficiencies presented(and so the colors depending on the benefits (green) or drawbacks (red) of the design compared to others).
No, the constraints are saved in the design, so when you augment your design and replicate it (by selecting the right factors and response in the corresponding menu and then clicking on "OK"), your constraint(s) will be remembered and shown by JMP in the new window, with the different available options for augmenting your design (and especially for your case "Replicate"). Depending on the number of times you want to perform each run (asked by JMP after clicking on "Replicate") JMP will then create "copies" of your initial design runs.
"It is not unusual for a well-designed experiment to analyze itself" (Box, Hunter and Hunter)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Adding a complex constrain to a Custom Design with 4 factors
Hi @ADouyon,
Welcome to the Community !
Looking at your problem and options, here is what's recommended :
- First, define your factor B as a discrete numeric, because the number of reactions is a whole number (you can't have 1,7 reactions for example, only 1, 2 or 3 in your case study),
- Factor D should have a lower level fixed at 0 if you want to have a waiting time of 0 when there is only one reaction.
- Since Factor D (time) is in your design a continuous factor (you can have any reaction time you want in the range specified), I would recommend to add the quadratic term D*D in the model, since for (chemical) reactions, time has not often a linear relation with the yield/output.
- Depending if the response can be measured "online" without any degradation, perhaps it would make sense to record the response at several time intervals, in order to have a modelization of response vs. time (with the input factors) ?
- Last but not least, I'm not familiar with your topic, but choosing different settings for factors may also solve your problem (changing waiting time for reaction time for example).
Based on your inputs, you can go into "Use Disallowed Combinations filter" ans select the range you want to exclude from your design (here, 1 =< B < 2 AND D > 0, see screenshot constraints for example). JMP should then offer you a design that adress this specific constraint (see screenshot Matrix and Experimental Space).
There may be better (and smarter) ways to do it, or more appropriate designs/factors configuration to think about this topic, but this should answer your needs and question.
I hope it will help you,
"It is not unusual for a well-designed experiment to analyze itself" (Box, Hunter and Hunter)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Adding a complex constrain to a Custom Design with 4 factors
Hello @Victor_G ,
Thank you very much for your quick response! This was very helpful!
I have a couple follow up questions:
1- When Factor B (the discrete numeric factor that is the number of biological reactions) is 2 or higher (3), then the Factor D cannot be zero. How can I add this second constraint in the model?
I tried it but I am not sure I did it right (screenshots attached).
2- The model automatically added the quadratic term B*B with estimability = if possible. Do you think I should keep this term? (I am trying to make this first design not too large)
Thank you!!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Adding a complex constrain to a Custom Design with 4 factors
Hi @ADouyon,
I'm glad this first answer helped you.
Concerning your other questions :
- On the second screenshot, it seems that the two constraints are well specified. I also forgot to do it myself in my first answer, but you can change the format of your B factor in the filter constraint by clicking on the red triangle, then "Modeling type" = Categorical/Ordinal : this is easier to create constraints and avoid using things like 0<= B < 1,99 when we simply want to have B fixed at 1 (see screenshot constraints2). Looking at your design matrix and mine, constraints seem to have been respected, so it should work fine.
- Yes, you should keep it, since JMP adds it and specifies its estimability as "If Possible" by default so it won't require more runs, but the runs will be better organized in the experimental space, so that in case you have enough degree of freedom in you model, JMP will try to estimate the quadratic term of your discrete numeric factor. And compared to a Categorical factor, having a Discrete Numeric factor means that JMP knows there is a relationship between the levels (they are ordered), compared to a pure Categorical factor (no relationships between levels, levels are nominal). There was a video explaining the difference between Discrete Numeric and Categorical: Dear Dr. DOE, isn’t Discrete Numeric just Categorical? - JMP User Community.
If you can afford more runs, I would suggest to add some replicate runs, to increase the power of your main effects (increasing the ability to detect a significant main effect if it is indeed present). You may have a severe experimental budget constraint, but comparing several design with several sample sizes can help you choose the most optimal situation for your needs.
I hope this follow-up will help you as well,
"It is not unusual for a well-designed experiment to analyze itself" (Box, Hunter and Hunter)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Adding a complex constrain to a Custom Design with 4 factors
Thank you so much, @Victor_G !! Much appreciate it. Your answers are super helpful!!
I took a couple courses on JMP DOE and read that we shouldn't invest >25% of our efforts on the first experiment. For us, time is the most limited resource we have. I was wondering, is it common to generate more than one design with different sample sizes for comparison, like you mentioned? Shouldn't the designs give the same result at the end? would you mind expanding a little more on that?
Thank you!!!
Best,
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Adding a complex constrain to a Custom Design with 4 factors
Hi @ADouyon !
I'm glad the answers were helpful. I don't know how common this practice may be, but I personnaly prefer to spend more time comparing different designs and sample sizes than going to the lab and do the experiments quickly, to finally see that I may have forgotten a constraint, or that my design is not well suited enough for my needs.
--> To illustrate this, I really like this quote of Ronald Fisher : "To consult the statistician after an experiment is finished is often merely to ask him to conduct a post mortem examination. He can perhaps say what the experiment died of."
Different designs may lead to different interpretations of the results, depending on which terms are in the different models. For example, screening designs with main effects only may help filter relevant factors for the follow-up of a study, but may clearly lack precision and response(s) predictivity in presence of 2 factors interactions and/or quadratic effects (possible lack of fit).
You have several options to generate different designs and compare them:
- Change (add/remove) the terms in the model (2 factors interactions, quadratic effects, ...) or their estimability (you can switch the estimability from "Necessary" to "If Possible" for 2FI and Quadratic effects).
- Vary the sample sizes (number of experiments) in the design by adding replicate runs : are the extra runs relevant and useful enough to have a gain on estimates precision or relative variance prediction over the experimental space ?
- Change the optimality criterion (depending on your target : D-optimality for screening, I-optimality for good response prediction precision, Alias-optimality to improve the aliasing between terms in the model...)
- Change the type of design (if possible !)...
For the moment, to compare different DoEs you have to create them in JMP and then go to "DoE", "Design Diagnostics", and then "Compare Designs". But ... Spoiler alert ! : In JMP 17, it will be a lot easier to compare several designs (see screenshots), as a "Design Explorer" platform will be included in the DoE creation, so no need to manually create them one by one : you can create several designs in seconds, and filter them based on your objectives and decision criteria.
And finally, take advantage of "iterative designs" and don't expect or try to solve all your questions with one (big) design. It may be more powerful and efficient to start small with a screening design for example, and then use Augmentation to search for more details, like interactions and possible non-linear effects. Finally, if your goal is to optimize something, you can once again augment your design to fit a full Response Surface Model. At each step, you gather more knowledge about your system, and make sure that the next augmented design will bring even more knowledge, without wasting experiments/runs, time and ressources.
"Augment design" platform is really a powerful (and often underestimated) tool to gather more data and gain more understanding and build more accurate models without losing any previous information.
I hope this answer will help you,
"It is not unusual for a well-designed experiment to analyze itself" (Box, Hunter and Hunter)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Adding a complex constrain to a Custom Design with 4 factors
One additional comment to mention a great ressource about the sequential nature of experiments, by Prism Training & Consultancy : Article: The Sequential Nature of Classical Design of Experiments | Prism (prismtc.co.uk)
This article explains very well the process behind DoE, from creating and assessing the experimental scope for factors, to screening and then optimization. This is part of a serie of article that may have an interest for you.
Happy reading !
"It is not unusual for a well-designed experiment to analyze itself" (Box, Hunter and Hunter)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Adding a complex constrain to a Custom Design with 4 factors
Thanks once again, Victor! :)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Adding a complex constrain to a Custom Design with 4 factors
Thank you incredibly, @Victor_G! Very much appreciated! Your comments are extremely useful and clear, thank you!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Adding a complex constrain to a Custom Design with 4 factors
Thanks a lot for your kind comments and feedback @ADouyon !
I'm happy if my answers were helpful and clear enough ! :)
"It is not unusual for a well-designed experiment to analyze itself" (Box, Hunter and Hunter)
Recommended Articles
- © 2025 JMP Statistical Discovery LLC. All Rights Reserved.
- Terms of Use
- Privacy Statement
- Contact Us