- New to JMP? Join us Sept. 23-24 for the Early User Edition of Discovery Summit, tailor-made for new users. Register now for free!
- Use World Cup data to build models, explore spatial relationships, and create informative visualizations in JMP. Register. July 17, 2 pm US Eastern Time.
- Your voice matters! Tell us how you prefer to receive JMP updates, so we can tailor our communication to your needs. Take short survey.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Discussions
Solve problems, and share tips and tricks with other JMP users.- JMP User Community
- :
- Discussions
- :
- Re: Adding a complex constrain to a Custom Design with 4 factors

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Adding a complex constrain to a Custom Design with 4 factors
Hello,
I am creating a Custom Design with 4 factors (Factors A, B, C & D).
I have a question about a constraint that has to do with factors B and D.
- Factor B is actually the number of reactions done in sequence in the same experiment. This can be 1 reaction, 2, 3 or more reactions in sequence. I set the range as 1-3 (not higher because I am not interested at the moment in >3 reactions in sequence).
- Factor D is the time I wait in between the reactions in sequence. Thus, I only define Factor D when Factor B is >1. The range is 0.1 to 10 seconds. Factor D would be 0 if Factor B is 1. In other words, when the number of reactions done in sequence (factor B) is just 1, Factor D doesn't exist because it was just 1 reaction and thus, I don't need to wait any seconds since there is no other reaction in sequence performed.
How can I define this constraint in my Custom Design model?
Thank youuuu!!
PS: I use a Mac.
{kind=link}
{kind=link}
- Tags:
- macOS

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Adding a complex constrain to a Custom Design with 4 factors
Hi again @ADouyon,
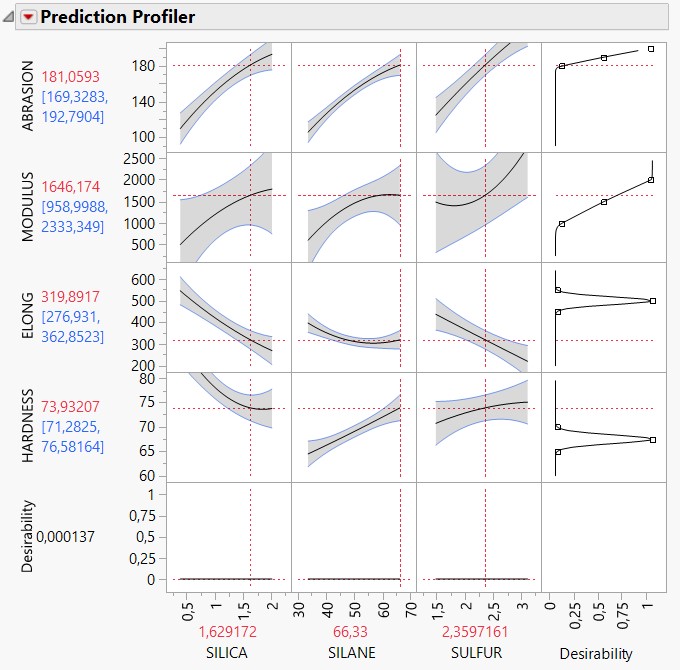
- The "lower limit" is the lowest acceptable solution for your situation (it defines a possible and acceptable range of values from your lowest limit to your highest limit), and may have an impact if you have several responses. In the case of an unique response, it doesn't matter much because JMP will either way try to optimize the response (maximize/minimize or match value), so the lower limit will be in any case avoided at all cost by finding the right factors settings (in the case of "Maximize"). The change will be in the slope of the desirability function (see screenshot Profiler-1 done with lower limit 350 and Profiler-2 done with lower limit 450 on the use case "Bounce Data" from JMP).
If you have several responses, changing the slope of one of your response desirability profile may change the optimum found, because JMP will try to maximize the overall desirability value (taking into account all responses desirabilities functions), so having a steeper slope for a response means that this response may have a bigger influence on the desirability optimization solution (because you'll reduce the range of acceptable values, see comparison of profiler optimization with screenshots Profiler-desirability-1 and Profiler-desirability-2 on the dataset Tiretread.jmp from JMP data use cases). Also take into account that the importance fixed for each of your response will also greatly influence the optimum found : the bigger the response importance, the bigger the influence of this response on the optimum situation found.
More infos on the desirability profile can be found here : The Desirability Profile (jmp.com) - The use and number of replicates is determined by your goal, power for effects, precision expected for your experiments/predictions, ... Be careful in JMP there are two options : "number of replicate runs" (in Custom Design), meaning here the number of run(s) to repeat, and "number of replicates" (in Classical Design), meaning he number times to perform each run (in addition to the original runs) : Re: Custom Design Number of Replicates - JMP User Community.
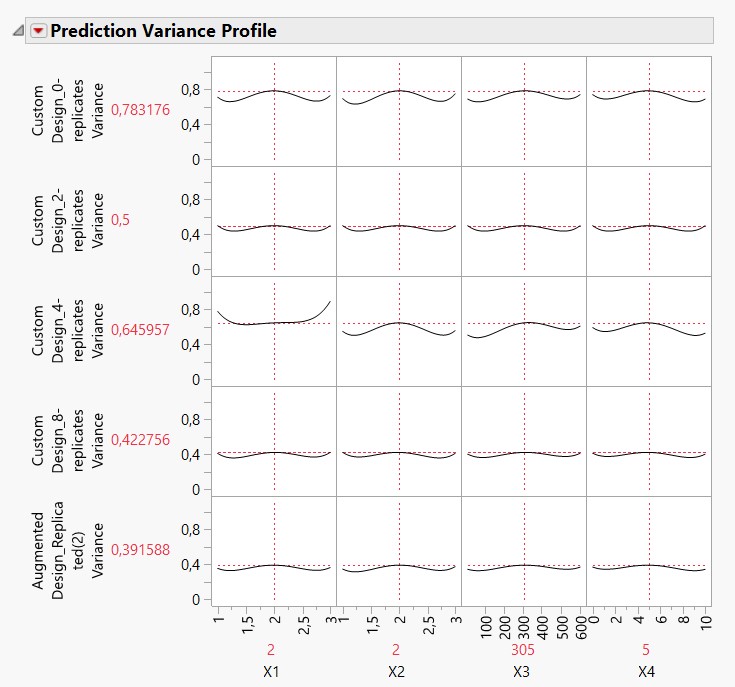
It's difficult without knowing all of this (and without domain expertise) to know what may be the more suitable choice for your case, but I would recomment to try different options (no replicate runs, 2 replicate runs, 4 replicate runs, 8 replicate runs...) and use the "Compare Designs" platform (found in DoE -> Design Diagnostics) to evaluate which number of runs would be optimal for your case (biggest impact for the lowest number of replicates). Attached you can find the different comparisons made with your DoE settings for 0, 2, 4 and 8 replicate runs for Power, Variance and Correlation comparisons, with the individual datatable created for each DoE. Here for 2 and 4 replicate runs, JMP ends up with the same default number of experiments (18) with similar properties for these designs. However, we can clearly see a gap between 0 and 2/4 replicate runs in terms of power, variance prediction profile (almost divided by a factor 2 in the case of 2 or 4 replicate runs compared to 0 replicate runs) and correlation matrix/color map (aliasing between terms in the model), so the 18 runs design (either 2 or 4 replicate runs) may be a good compromise here to have reliable results and precision without augmenting too much the experimental costs (27 experiments for a 8 replicate runs design !).
If you really want to compare with a duplicate/triplicate... design (to have replicates and not only replicate runs), you can create the original design proposed by JMP (with 9 experiments, without any replicate runs), and then augment it (in DoE -> Augment Design) by selecting the option "Replicate". JMP will then ask you the number of times to perform each run, so if you enter "2", you'll end up with your duplicate design with 18 runs. Note that in the case here, the two options (replicates and replicate runs) bring very similar design performances for the same number of runs (here tested with 18 runs in total). - I don't know precisely how to handle this. If you don't know in your experimental space which conditions will make your experiment succeed/fail, one option could be to test your experimental space first with a "Scoping design" (Scoping Designs | Prism (prismtc.co.uk)) to check if your factors conditions are possible in the lab (and then augment this design to a screening one, and perhaps after augment it to an optimization one with Response Surface models).
If you already know which factors conditions will make your experiment fail or succeed, you can perhaps include the settings and create appropriate runs in your DoE, and include or add these runs as well in your analysis, either as part of the design, or as validation points (excluded for the analysis of the design, but added at the end to check predictions of the design match your knowledge).
I hope these answers will help you (sorry for the long post),
PS: I have 9 runs in my original design with no replicate runs, this is because I didn't add the terms X1*X1 and X1*X2 in the model, but the general presentation and comparison of design may still be valid (you may have to verify to check it, if needed I can try to change the designs and provide a valid comparions and screenshots today).
"It is not unusual for a well-designed experiment to analyze itself" (Box, Hunter and Hunter)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Adding a complex constrain to a Custom Design with 4 factors
Hi @ADouyon,
With the correct designs and models, the comparisons are a bit different:
- For power, there seems to be no significant improvement between designs with no replicates runs, or 2 or 4 replicate runs. Having 8 replicate runs (for a total of 27 experimental runs) or replicate entirely the original design (for 36 experiments in total) does improve the power.
- For variance prediction, having 2 replicate runs (for the same number of total runs : 18) seems to lower more efficiently the variance over the entire space than with having 4 replicate runs (or none). Having 8 replicate runs (for 27 experiments !) does lower the prediction variance over the experimental space a little bit, but it is quite similar to what you get with 2 replicate runs. And for sure, if your replicate your original design (and double the number of experiments from 18 to 36...), your prediction variance will be divided by two.
- In terms of efficiencies and aliasing, replicating the entire design will give you the same aliasing/correlation between terms, whereas adding replicate runs can change and lower some aliasing. Efficiencies are quite similar for designs with the same number of runs, and will fore sure increase when you augment your number of experiments.
Hope this part will help you and not bring additional confusion,
"It is not unusual for a well-designed experiment to analyze itself" (Box, Hunter and Hunter)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Adding a complex constrain to a Custom Design with 4 factors
Thank you @Victor_G for elucidating everything in such depth! Very much appreciated!!
So, when comparing designs, I understand that we want to 'Prediction Variance' of the 'Fraction of Design Space Plot' to be low ideally, while we want the 'Power' of the 'Power Analysis Plant' to be high (close to ~1). Is this correct?
I wonder if you could expand on the interpretation of the Design Diagnostics efficiency values (shown in your screenshot of the "color-map+efficiency_comparison"? it shows that red is bad, however, there are more red values in the last comparison (0 replicates vs augmented design).
Also, when augmenting the design with the replicates like you suggested, do I have to define the constraints again?
Thank you @Victor_G in advance!!
Best,
{kind=link}
{kind=link}
{kind=link}

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Adding a complex constrain to a Custom Design with 4 factors
There is a lot of information in the diagnostics outline. Some of it is more relevant at times. I am not saying that you should not look at everything, but we are generally somewhat selective in the information we use to compare the designs. Power, estimation efficiency, and correlation of estimates are more critical when I am screening factors or factor effects. On the other hand, prediction variance (profiled or integrated) is more acute when I am ready to optimize my factor settings based on model predictions.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Adding a complex constrain to a Custom Design with 4 factors
Hi again @ADouyon,
As a first overview, yes you're correct : power (=probability of detecting an effect if it is really active) should be as high as possible, prediction variance and fraction of design space plot as low as possible. But as answered by @Mark_Bailey, you'll compare in priority with other designs what you need from your experimental plan (as having everything high/perfect is often not possible or at the cost of a very large number of experiments):
- If you're using a DoE to screen main effects (and perhaps interactions), you're not primarily interested in the prediction variance and fraction of design space, but rather in the detection of significant effects among your factors (and perhaps interactions). So you'll rather focus on power analysis.
- If you're using a DoE to optimize a process/formula, you would like to obtain predicted response(s) as precisely as possible, so you would like to have the lowest prediction variance. Hence, you'll compare with other designs the prediction variance over the experimental space and the fraction of design space plot.
You'll find some infos on Design Evaluation here (and in the following pages) : Design (jmp.com)
Yes, as my primary design for comparison was Custom-Design_0-replicates (with the lowest number of experiments and no replicates), most of the other designs performed better (either because they have replicate runs, so a similar or better estimation of noise/variance for the same number of experiments, or because they had a higher number of experiments (last 2 designs), hence improving all efficiencies) so the efficiencies of this simple design was worse compared to other designs (therefore the red values).
Changing the primary design in the comparison would have changed the relative efficiencies presented(and so the colors depending on the benefits (green) or drawbacks (red) of the design compared to others).
No, the constraints are saved in the design, so when you augment your design and replicate it (by selecting the right factors and response in the corresponding menu and then clicking on "OK"), your constraint(s) will be remembered and shown by JMP in the new window, with the different available options for augmenting your design (and especially for your case "Replicate"). Depending on the number of times you want to perform each run (asked by JMP after clicking on "Replicate") JMP will then create "copies" of your initial design runs.
"It is not unusual for a well-designed experiment to analyze itself" (Box, Hunter and Hunter)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Adding a complex constrain to a Custom Design with 4 factors
Thank you for the insight, @Mark_Bailey and @Victor_G !!
- « Previous
- Next »
Recommended Articles
- © 2026 JMP Statistical Discovery LLC. All Rights Reserved.
- Terms of Use
- Privacy Statement
- Contact Us