Our students/coworkers typically find themselves with specific needs related to the graphical depiction of the STRUCTURE of data. We would like JMP to either improve or modify the existing capability for Ishikawa / Fishbone diagrams to enable the creation of "trees" depicting a data collection, or to ignore the Diagram platform to provide a new way to take a list of variables in a data collection, and display the structure of the data easily in tree format.
A) Depiction of the data present in existing files/DBs, including the presence of confounding in that data - independent variables that are NOT tracked or present in the existing data, but are confounded with fields that are (Example: Age and Height might not be tracked in a database that DOES have a field for WEIGHT) - so the tree might show that we have five patients, and each has a WEIGHT in the database, but we each also has an Age and Height NOT present in the data. We show this because in the analysis we want to indicate where an effect might be INCORRECTLY attributed to a variable present, when in fact it could be due in part or total to some other variable we did not collect.
B) Depiction of NEW data collected passively (sampling plans). The need here is essentially the same as A, but is listed separately as this data would not exist at the time the plan is created.
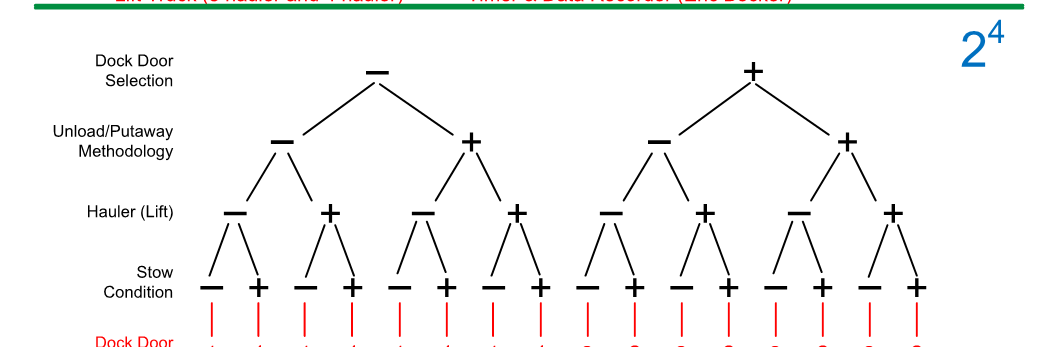
C) Factor Relationship Diagrams (FRDs). Essentially the depiction of a DOE created by JMP, with design structure based on the chosen design parameters, but then also the capability of placing within each combination a tree for the unmanipulated variables (unit structure)..For example, for the combination - + + - we would also want to know / show that within this combination, there were two machines examined, and within each we took two material samples. Ideally Design Structure would be BLACK, and Unit Structure RED.
To attempt to do this via the Diagram platform is awkward, and we are in particular interested in C, as JMP is typically where we choose our design, so it would be nice to have it just translate that into a diagram. Later enhancements would increase flexibility of unit structure capability, including the ability to add CONDITIONS at the top of any diagram (noises/variables constant throughout).
{kind=link}