- New to JMP? Join us Sept. 23-24 for the Early User Edition of Discovery Summit, tailor-made for new users. Register now for free!
- Your voice matters! Tell us how you prefer to receive JMP updates, so we can tailor our communication to your needs. Take short survey.
- See how to access JMP Marketplace - and - find, create & share add-ins to extend your JMP. Watch video.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Discussions
Solve problems, and share tips and tricks with other JMP users.- JMP User Community
- :
- Discussions
- :
- Re: Too Few DOF Part 2

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Too Few DOF Part 2
All,
I have taken into account your previous suggestions from my last thread about too few DOFs. As @statman pointed out, I was trying to see effects from factors and interactions that didn't have enough DOF.
I have since changed my methodology and discovered that I first need to use a screening array - an L16 in my case - to see which factors and two-way interactions are significant, and then move on to a smaller array to analyze interactions and factors at more levels (in my case, 3 levels instead of the 2 in the L16).
My line of thinking for calculating DOF
1. The degrees of freedom are inherent to the array itself, and not the number of trials you complete for a certain treatment. For example, if you have an L16 array and you complete three trials per treatment, your DOF total is 15 and not 47.
2. DOF of A = 1, DOF of B = 1, DOF of C = 1, DOF of D = 1; DOF of AxB = 1, DOF of AxC = 1, DOF of BxC = 1, DOF of BxD = 1, DOF of AxD = 1, DOF of CxD =1 --> DOF_total = 15, DOF_sum of all factors and interactions = 10, DOF_error = 5
Based on my calculations, it seems like I should have at least 5 extra degrees of freedom to use. However, when I run Fit Model on my experimental design, and look under Effect Tests, I still get the error message of too few DOF. Why is this happening?
I saw Pete's suggestion in the last thread to complete the SAS course; I appreciate the suggestion, but am a bit pressed for time and don't have the time to spend 30 hours on a course at the moment. I will definitely look into this course over the summer, however.
Attached is my file for your reference.
Thank you in advance for your help!

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Too Few DOF Part 2
I have to admit I am biased. I'm not sure why you are running an L16? You have 4 factors at 2 levels in 16 treatments...that is a full factorial (2^4). With that design the model effects you can estimate are:
A+B+C+D+AB+AC+AD+BC+BD+CD+ABC+ABD+ACD+BCD+ABCD
Now, many would suggest you pool the higher order terms to estimate the MSE.
If you want to get what some would call unbiased estimates of the random errors over your design space, you will need to run replicates.
Regarding your design, there is a problem with it. Look at the pattern column and the last column is alternating -, + but your D column is not. Not sure how you created this, but do not run this design. I have attached a corrected design.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Too Few DOF Part 2
Hi @statman .
I chose the L16 as a screening array, with the intention to see which main factors and interactions are significant, and test those factors and interactions in another design with all levels (3 in the new design, instead of two levels in the L16).
I see what you mean in terms of the pattern not alternating the in the last column.
The reason that this design was chosen was to avoid confounding main factors with interactions, as per this interaction table, by leaving some columns "blank": https://support.minitab.com/en-us/minitab/18/help-and-how-to/modeling-statistics/doe/supporting-topi...
My understanding is that you have to leave specific columns blank to avoid confounding main factors with two-way interactions. Is this wrong? Should I have instead just copied down the first four columns like and left all the rest blank? If so, how can you guarantee there will be no confounding in this case?
Is this what is throwing off my Fit Model/Effect Tests so I can only see the effects of the main factors?
Thank you!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Too Few DOF Part 2
I'm so sorry, I'm not sure what to say. I think you need some fundamental understanding of experimentation. There are some JMP on-line tools and webinars that might be beneficial. Please don't take this as a show of disrespect. I'm sure you are measurably more versed in your field.
You might disregard the following commentary.
I by no means want to disparage any methodology and I have been particularly inspired by Dr. Taguchi and learned much from him. I will say the L arrays and subsequent "need" for interaction plots to determine the aliasing...well let's just say there are other ways to create designs and subsequent aliasing. That being said, two of the most important lessons I was taught by Taguchi was;1. to consider the response variables diligently and 2., to focus on understanding and becoming robust to noise.
I sent you a data table that is a full resolution design for your 4 factors in the identical number of treatments as the L16. There is no aliasing of any effect. However, there is also no strategy to understand noise or robustness of your model.

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Too Few DOF Part 2
Taguchi designs have their place. They are a special application or method of DOE. They work best when interactions are nil. They are not intended to support modeling. They were devised for a situation in which 'pick the winner' is of utmost importance and the person picking needs the simplest criterion.
If your situation fits the case of a screening experiment (see key principles below), then you might consider a definitive screening design instead of the L16.
- Sparsity of effects: there are many factors and many potential effects of those factors (linear, non-linear, interaction) but only a few are active
- Hierarchy of effects: the magnitude or contribution of the effects deceases with the order of the term. The first-order terms contribute the most, the second-order terms contribute less, and so on. Terms of order three and higher are generally non-existent or negligible, and ignored. This is a principle, not a law, but it often holds.
- Heredity of effects: The interaction and non-linear effects generally involve the factors with important first-order effects. This principle is often used to guide both the design of the experiment and the analysis of the data. This is a principle, not a law, but it often holds.
- Projection: The principle of sparsity of effects means that the design for all the suspected factors is much larger than what is needed to collect data for the active effects of the active factors. The process of model selection will usually reduce the full model of the design to something that is much smaller, but the design did not change, so now there is plenty of data, both in the number of runs and in the number of treatments. The design matrix 'projects' into a smaller model matrix.
These principles are at the heart of all methods of designing and analyzing an experiment to screening factors.

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Too Few DOF Part 2
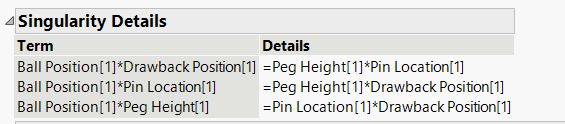
Technically with 16 runs and 4 factors, yes you should have enough degrees of freedom. Below you mentioned placing the variables in certain columns of the L16, and that is where you made the mistake. It is critical that you put them in right columns to be able to estimate the interactions, and you didn't do that. So the Ball Position * Drawback Position is confounded with the Peg Height* Pin Location interaction. And 2 other interactions are also confounded. The Linear graphs with Taguchi designs help you know which columns you can assign variables to get specific interactions.
Did you see the report called Singularity Details in your Fit Model output? It is telling you what is confounded with what. So all 6 interactions are confounded with each other, preventing you from estimating any of them.
These variable names remind me of many catapult experiments I did years ago, and I used Taguchi methods with them. But that was before I had JMP to design a better experiment and do amazing graphs with the analysis.
I'm afraid you need to collect more data, and make sure the columns are not confounded. One way to do that is to use a full factorial with 4 factors and 16 runs.
{kind=link}
Recommended Articles
- © 2026 JMP Statistical Discovery LLC. All Rights Reserved.
- Terms of Use
- Privacy Statement
- Contact Us