- Instantly extract effect sizes, F-ratios, and FDR-adjusted p-values from your models with the Calculate Effects Sizes extension, available now in the JMP Marketplace!
- New to JMP? Join us Sept. 23-24 for the Early User Edition of Discovery Summit, tailor-made for new users. Register now for free!
- Your voice matters! Tell us how you prefer to receive JMP updates, so we can tailor our communication to your needs. Take short survey.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Discussions
Solve problems, and share tips and tricks with other JMP users.- JMP User Community
- :
- Discussions
- :
- Summary of multiple CSV files

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Summary of multiple CSV files
How do I direct JMP to a file folder on my desktop that have about 400 CSV files like a database, create a bunch of columns and create a summary table with 1 row per file? I can do this individually, but it takes forever and I was hoping I could develop a script to automate.
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Summary of multiple CSV files
Here is my take on the script that is needed. It is pretty simple and gets all numeric columns summarized, and brings along the Excel Sheet name as a new column
Below is edited based upon the issues found in the next reply
Names Default To Here( 1 );
dir = Pick Directory();
files = Files In Directory( dir );
dt = New Table( "concat", New Column( "File", character ) );
For( i = 1, i <= N Items( files ), i++,
If( Ends With( files[i], "csv" ), //just a check to make sure it's a csv
// Open the file
dt1 = Open( dir || files[i], private );
//Get all of the numeric columns from the just opened file
thecolumns = dt1 << get column names( numeric );
// Create an output table of one row that contains the summary
// As many stats as desired can be added to the below to get all of the
// ones that are needed
dt2 = dt1 << Summary( Mean( Eval( thecolumns ) ), Freq( "None" ), Weight( "None" ) );
// Add the summary table to the summary table
dt << concatenate( dt2, append to first table );
// Since what is wanted is the ID, not the file name, and the ID is
// the Sheeet name in the Excel spreadsheet, one has to get that value
// the the name of the data table, since that is where JMP 13 places the
// sheet name
dt:File[N Rows( dt ) ] = dt1 << Get Name;
// Close the no longer needed raw data table
Close( dt1, no save );Close( dt2, no save );
)
);

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Summary of multiple CSV files
So I'm making a few assumptions about this. I could be off.
All csv files have the same columns.
you want to create an aggregate summary (mean for example) of each column for each file.
Names Default to here(1);
dir = pick directory();
files = files in directory(dir);
dt = New Table("concat", New Column("File", character));
for(i=1, i<=nitems(files), i++,
if(endswith(files[i], "csv"), //just a check to make sure it's a csv
//break();
dt1 = open(dir||files[i], private);
dt1 << New Column("File", character, set each value(files[i]));
dt<<concatenate(dt1, append to first table);
close(dt1, no save);
)
);
dt_Sum = dt << Summary( //you'll have to put which statistics you want for your column names here
Group( :File ),
Mean( :ColumnA ),
Mean( :ColumnB ),
Mean( :ColumnC ),
Mean( :ColumnD ),
Freq( "None" ),
Weight( "None" )
);

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Summary of multiple CSV files
(Ignore this answer; Vince has a much better approach.)
A variation on Vince's answer, if you want per-file statistics. I also imagine the columns are consistent...
path = "$desktop/csvFiles/";
files = Files In Directory( path );
answers = New Table( "Summary",
New Column( "N Rows", Numeric, "Continuous", Format( "Fixed Dec", 12, 0 ), Set Values( [] ) ),
New Column( "Mean(x)", Numeric, "Continuous", Format( "Best", 12 ), Set Values( [] ) ),
New Column( "Mean(y)", Numeric, "Continuous", Format( "Best", 12 ), Set Values( [] ) ),
New Column( "Mean(z)", Numeric, "Continuous", Format( "Best", 12 ), Set Values( [] ) ),
New Column( "sourceFile", character )
);
For( iFile = 1, iFile <= N Items( files ), iFile += 1,
file = path || files[iFile];
dt = Open( file, "text" );
dt2 = dt << Summary( Mean( :x ), Mean( :y ), Mean( :z ), Freq( "None" ), Weight( "None" ) );
answers << addrows( 1 );
answers:sourceFile = file || " " || Format( Creation Date( file ), "m/d/y h:m:s" );
answers:N Rows = dt2:N Rows[1];
answers:name( "Mean(x)" ) = dt2:name( "Mean(x)" )[1];
answers:name( "Mean(y)" ) = dt2:name( "Mean(y)" )[1];
answers:name( "Mean(z)" ) = dt2:name( "Mean(z)" )[1];
Close( dt, nosave ); // linked table closes too
);my files looked like this
x,y,z
1,2,3
4,5,6
I used the table script from a file I made by hand to get the Summary script. There might be a better way to copy the variables; in JMP 13 you could use the ideas here to assign a whole row in one statement.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Summary of multiple CSV files
Sorry for the delay. Was on service and having to take care of patients. Now just getting back to this.
No they don't always have the same column (A, B, C, etc.) but they do have the same name.
Brian
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Summary of multiple CSV files
can you give a screenshot of two fake tables and what you want the end result to look like? I can't figure out what you're asking.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Summary of multiple CSV files
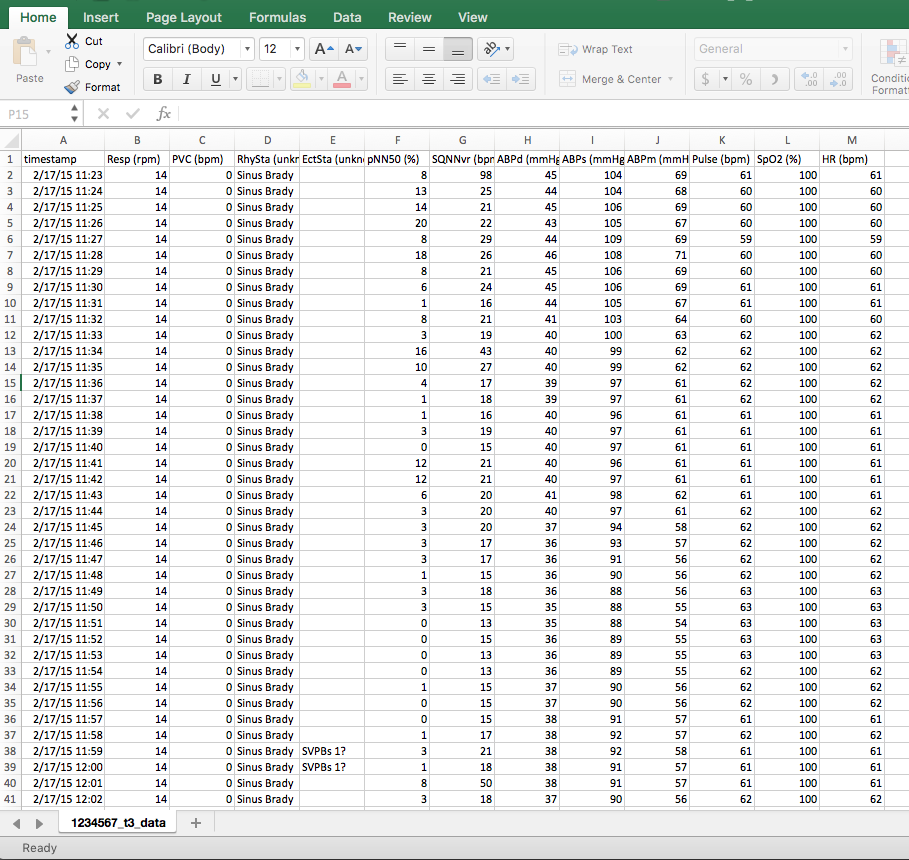
Here is what the data looks like within a CSV file. The file name is also the patient identifier. How can I get it to summarize by column heading and create a table of the summarized data with the file identifier in a column? You can see what the file name looks like at the bottom on the screen shot.
I could convert all the CSVs to JMP files? Just not sure it would help.
Does anyone know if the Data Table Tools add-in would work for this case?
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Summary of multiple CSV files
Summarized how?

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Summary of multiple CSV files
Here is a variation on Vince's response; this allows different column names in each file.
Names Default to here(1);
dir = pick directory();
files = files in directory(dir);
//table to hold summary data
dts = New Table("Summary", New Column("filename", character));
for(i=1, i<=nitems(files), i++, //for each filename
if(endswith(files[i], "csv"), //if file is a csv
//open the file
dt1 = open( dir||files[i], private );
//add a row to the summary table
dts << Add Rows(1);
//save the filename to the data table
Column( dts, "filename" )[i] = files[i];
//get list of columns
cols = dt1 << Get Column Names();
//for each column
for ( c=1, c <= N Items(cols), c++,
//add mean column to summary table if it isn't already there
if ( Contains( dts << Get Column Names(); , Parse( Char( cols[c] ) || "_mean" ) ) < 1,
dts << New Column( Char( cols[c] ) || "_mean" );
);
//find the mean and write it to summary table
Column( dts, Char( cols[c] ) || "_mean" )[i] = ColMean( Column( dt1, cols[c] ) );
//add max column to summary table if it isn't already there
if ( Contains( dts << Get Column Names(); , Parse( Char( cols[c] ) || "_max" ) ) < 1,
dts << New Column( Char( cols[c] ) || "_max" );
);
//find the max and write it to summary table
Column( dts, Char( cols[c] ) || "_max" )[i] = ColMax( Column( dt1, cols[c] ) );
); //end loop each column
//close file
close(dt1, no save);
); //end check for csv
); //end loop for each file
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Summary of multiple CSV files
Here is my take on the script that is needed. It is pretty simple and gets all numeric columns summarized, and brings along the Excel Sheet name as a new column
Below is edited based upon the issues found in the next reply
Names Default To Here( 1 );
dir = Pick Directory();
files = Files In Directory( dir );
dt = New Table( "concat", New Column( "File", character ) );
For( i = 1, i <= N Items( files ), i++,
If( Ends With( files[i], "csv" ), //just a check to make sure it's a csv
// Open the file
dt1 = Open( dir || files[i], private );
//Get all of the numeric columns from the just opened file
thecolumns = dt1 << get column names( numeric );
// Create an output table of one row that contains the summary
// As many stats as desired can be added to the below to get all of the
// ones that are needed
dt2 = dt1 << Summary( Mean( Eval( thecolumns ) ), Freq( "None" ), Weight( "None" ) );
// Add the summary table to the summary table
dt << concatenate( dt2, append to first table );
// Since what is wanted is the ID, not the file name, and the ID is
// the Sheeet name in the Excel spreadsheet, one has to get that value
// the the name of the data table, since that is where JMP 13 places the
// sheet name
dt:File[N Rows( dt ) ] = dt1 << Get Name;
// Close the no longer needed raw data table
Close( dt1, no save );Close( dt2, no save );
)
);
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Summary of multiple CSV files
I think you meant to append the summary tables instead of the data tables?
Names Default To Here( 1 );
dir = Pick Directory();
files = Files In Directory( dir );
dt = New Table( "concat", New Column( "File", character ) );
For( i = 1, i <= N Items( files ), i++,
If( Ends With( files[i], "csv" ), //just a check to make sure it's a csv
// Open the file
dt1 = Open( dir || files[i] );
//Get all of the numeric columns from the just opened file
thecolumns = dt1 << get column names( numeric );
// Create an output table of one row that contains the summary
// As many stats as desired can be added to the below to get all of the
// ones that are needed
dt1 << Summary( Mean( Eval( thecolumns ) ), Freq( "None" ), Weight( "None" ), output table name("tmpdt"));
// Add the summary table to the summary table
dt << concatenate( Data Table("tmpdt"), append to first table );
// Since what is wanted is the ID, not the file name, and the ID is
// the Sheeet name in the Excel spreadsheet, one has to get that value
// the the name of the data table, since that is where JMP 13 places the
// sheet name
dt:File[N Rows( dt ) ] = dt1 << Get Name;
// Close the no longer needed raw data table
Close( dt1, no save );
)
);Recommended Articles
- © 2026 JMP Statistical Discovery LLC. All Rights Reserved.
- Terms of Use
- Privacy Statement
- Contact Us