- New to JMP? Join us Sept. 23-24 for the Early User Edition of Discovery Summit, tailor-made for new users. Register now for free!
- Your voice matters! Tell us how you prefer to receive JMP updates, so we can tailor our communication to your needs. Take short survey.
- See how to access JMP Marketplace - and - find, create & share add-ins to extend your JMP. Watch video.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Discussions
Solve problems, and share tips and tricks with other JMP users.- JMP User Community
- :
- Discussions
- :
- Misclassification rate, who is right?

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Misclassification rate, who is right?
Hi! JMP fans and experts
In Logistic regression, partition and Neural Network model cmparising, Misclassification rate acts as an important measure to determine which model is better or not? In my understanding, Smaller the value of misclassification rate is, better the model will be; however, I was confused by following cases. In the first case, I was told that larger one is better, but in the second case, I was told that smaller one is better.
JMP fans and experts, who can walk me through this problem? And give me more interpretation on that scenario.
1. First case
2. The second case
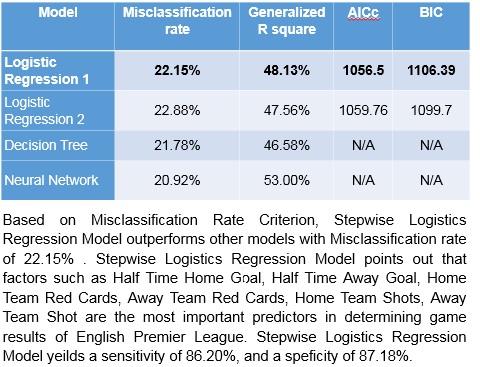{kind=link}
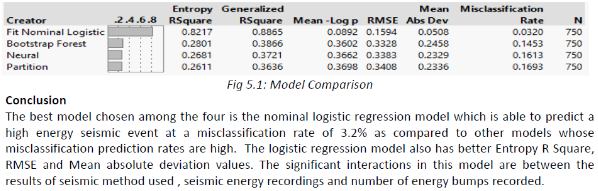{kind=link}
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Misclassification rate, who is right?
Are you using some sort of 'expert' system to produce the narratives associated with each table? The second case is obviously JMP related output from the JMP Pro Model Comparison platform. It's not clear to me what analytics package produced the picture of case #1.
Having asked this though, my guess is at least in case one, the definitive criteria that is being used to determine the 'best' model is the AICc statistic and not the misclassification rate. The AICc statistic is one of those 'lower is better' regression diagnostics...so since that model has the lowest AICc...the system is picking that model as the 'best'.
A bit of a general regression/modeling diagnostics interpretation tutorial follows. I scream from the rooftops whenever I can to NEVER use ONE single regression diagnostic measure, plot, or estimate to determine a 'best' model. At the end of every modeling problem I encourage decision makers to always determine your 'best' model with, "What model helps me solve my practical problem best?" That's the model you should pick...not the model with the highest R**2, F-ratio, AICc, or most attractive looking residual plot...or any other mathematical/graphical construct.
Especially in classification type problems...there are often very different practical consequences for the different categories of misclassification...the misclassification rate is the sum of ALL misclassifications. Think cancer diagnostics as one example...much different consequences for false negatives or false positives. So I might pick a 'best' model that minimizes the PRACTICAL consequences of one of the misclassification categories...at the expense of a higher rate in the other.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Misclassification rate, who is right?
Are you using some sort of 'expert' system to produce the narratives associated with each table? The second case is obviously JMP related output from the JMP Pro Model Comparison platform. It's not clear to me what analytics package produced the picture of case #1.
Having asked this though, my guess is at least in case one, the definitive criteria that is being used to determine the 'best' model is the AICc statistic and not the misclassification rate. The AICc statistic is one of those 'lower is better' regression diagnostics...so since that model has the lowest AICc...the system is picking that model as the 'best'.
A bit of a general regression/modeling diagnostics interpretation tutorial follows. I scream from the rooftops whenever I can to NEVER use ONE single regression diagnostic measure, plot, or estimate to determine a 'best' model. At the end of every modeling problem I encourage decision makers to always determine your 'best' model with, "What model helps me solve my practical problem best?" That's the model you should pick...not the model with the highest R**2, F-ratio, AICc, or most attractive looking residual plot...or any other mathematical/graphical construct.
Especially in classification type problems...there are often very different practical consequences for the different categories of misclassification...the misclassification rate is the sum of ALL misclassifications. Think cancer diagnostics as one example...much different consequences for false negatives or false positives. So I might pick a 'best' model that minimizes the PRACTICAL consequences of one of the misclassification categories...at the expense of a higher rate in the other.
Recommended Articles
- © 2026 JMP Statistical Discovery LLC. All Rights Reserved.
- Terms of Use
- Privacy Statement
- Contact Us