- New to JMP? Join us Sept. 23-24 for the Early User Edition of Discovery Summit, tailor-made for new users. Register now for free!
- Use World Cup data to build models, explore spatial relationships, and create informative visualizations in JMP. Register. July 17, 2 pm US Eastern Time.
- Your voice matters! Tell us how you prefer to receive JMP updates, so we can tailor our communication to your needs. Take short survey.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Discussions
Solve problems, and share tips and tricks with other JMP users.- JMP User Community
- :
- Discussions
- :
- How to save residuals from logistic regression?

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
How to save residuals from logistic regression?
I did logistic regression in the Fit Model platform, but could not find a place to save residuals. Any ideas? Thank you very much!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: How to save residuals from logistic regression?
Logistic model: Y = categorical variable. Typically one thinks of a residual as the difference between the predicted and observed value when you have a continuous (numeric) response. For the logistic model you can save the prediction model and one of the columns added to your table will be a "most likely outcome" column. You can then compare that to your observed responses to get a "residual" or agreement in categories. However, note that the most likely outcome is based on setting a cut-off for each outcome at the 0.5 probability score. For evaluating logistic models the ROC curve is often used. I like to plot my observed outcome as the Y and the probability score from my model on the X to see if there is a cut-off value in my score that differentiates my observed groups.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: How to save residuals from logistic regression?
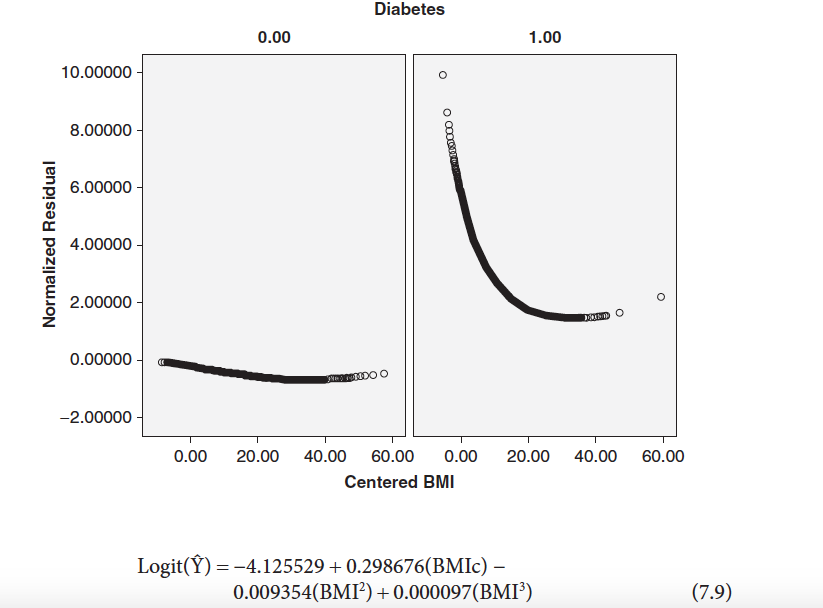
Thank you very much for your answer. This is the residual plot my professor has from SPSS. Is there a way to get this?
{kind=link}

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: How to save residuals from logistic regression?
I know nothing about how SPSS works, but it sure looks like you fit a good old fashioned ordinary least squares regression model with 0 and 1 as continuous responses, saved the studentized residuals and then did a scatter plot of each set of residuals by the levels of the response. If you set up a data table in JMP you can replicate the same erroneous way to model a categorical response. Far be it from me to tell you your professor was wrong...but...
I strongly recommend you follow the advice of Karen's earlier response. If you are going to use JMP you should define the response in the JMP data table as a character data type, 0 and 1 are acceptable, but make sure you articulate the data type as character, and the JMP modeling type as nominal. An alternative way to characterize the response is to use some phrase that may have more practical meaning than 0's and 1's. Maybe use JMP's Column Recode capability to recode the 0 to something like 'negative' and the 1 to something like 'positive'. I have found this technique useful when communicating results because then you never have to remember what the 0 and 1 stand for from a practical point of view.
Then JMP will guide you to make sure in the Fit Model platform when you choose Nominal Logistic Regression as the modeling personality. Essentially if you define the column properties correctly in JMP...JMP mistake proofs you away from executing an OLS model for this problem.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: How to save residuals from logistic regression?
The analysis was either done as Peter described or the residuals were calculated as the differences between what I will call the probability score from the logistic model and the 0/1s as continuous responses (not what I would consider a standard method). I think that this warrants a classroom discussion as to what model is being used, how is the response being treated (continuous vs. categorical) and how the residuals are being calculated. Then comes the questions as to why. What are you trying to model? Why? How are you trying to measure "model goodness"? and so on. Good luck!
Recommended Articles
- © 2026 JMP Statistical Discovery LLC. All Rights Reserved.
- Terms of Use
- Privacy Statement
- Contact Us