- New to JMP? Join us Sept. 23-24 for the Early User Edition of Discovery Summit, tailor-made for new users. Register now for free!
- Your voice matters! Tell us how you prefer to receive JMP updates, so we can tailor our communication to your needs. Take short survey.
- See how to access JMP Marketplace - and - find, create & share add-ins to extend your JMP. Watch video.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Discussions
Solve problems, and share tips and tricks with other JMP users.- JMP User Community
- :
- Discussions
- :
- How to analyze unbalanced data which three of independent factors are unbalanced...

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
How to analyze unbalanced data which three of independent factors are unbalanced levels?
Hello,
I have a data set which has four predictors: three of the predictors including time, distance, and power are unbalanced and one balance predictor. Do you have any idea what is the best way to analyze such data? And how I can analyze them? I do appreciate any help.

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: How to analyze unbalanced data which three of independent factors are unbalanced levels?
Every analysis 'how to' question should start with an articulation of the practical problem you are trying to answer. You haven't shared that with the Community. Please do.
Then a thorough evaluation of the means by which the data was collected. A designed experiment? Happenstance data? Historical data in time series? And what do you know about the measurement system and it's variability?
Are there are any issues associated with that process which make subsequent analysis problematic. Missingness, outliers, nonsense values. What about correlation of predictor variables? Then embark on analysis...at the highest level I have three thoughts for you:
1. Plot the data.
2. Plot The Data.
3. PLOT THE DATA...and this is where JMP shines.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: How to analyze unbalanced data which three of independent factors are unbalanced levels?
Hi Peter,
Thanks for your prompt response. Here is the problem articulation:
The experiment is a designed experiment. The objectives of this study were to determine the suitable combinations of IR heating duration, Gap distance, and intensity, followed by tempering treatments to maximize inactivation mold spores. I did plot the data and since it is not a balanced design there are some missing values. When I did the full factorial analysis the effect summary is not showing any values.
I was reading the same issue stated from other people: I found that I need to analyze using mixed model but I am not sure which variables should be considered as fixed and which as random?
BTW, how I can share my questions with the community now?
{kind=link}

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: How to analyze unbalanced data which three of independent factors are unbalanced levels?
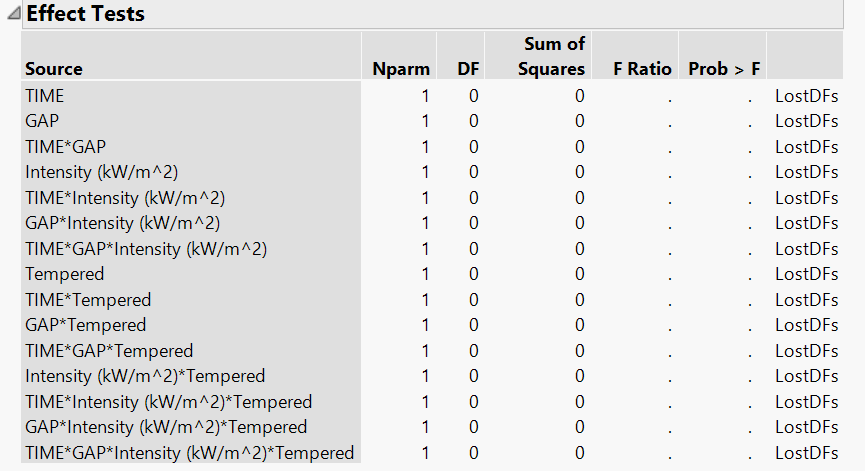
Thanks for the screen shot @Shad,
Based on the image, you have 15 terms in the model. IF it is a DOE with 4 effects and a full factorial design, then that would mean you have 16 runs. Is that correct? If so, you would not have enough degrees of freedom to estimate any of the effects/terms in the model (not enough data). You might want to start with stepwise regression to add terms in a forward stepwise fashion. Otherwise, remove terms that are most likely not going to have an impact (4th degree polynomial for example).
Hope that helps.
Chris
Data Scientist, Life Sciences - Global Technical Enablement
JMP Statistical Discovery, LLC. - Denver, CO
Tel: +1-919-531-9927 ▪ Mobile: +1-303-378-7419 ▪ E-mail: [email protected]
www.jmp.com

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: How to analyze unbalanced data which three of independent factors are unbalanced levels?
Another possible approach rather than going forward is to specify a model with only main effects and two-way interactions. Remove the three-way and four-way interactions.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: How to analyze unbalanced data which three of independent factors are unbalanced levels?
Thank you, Chris.
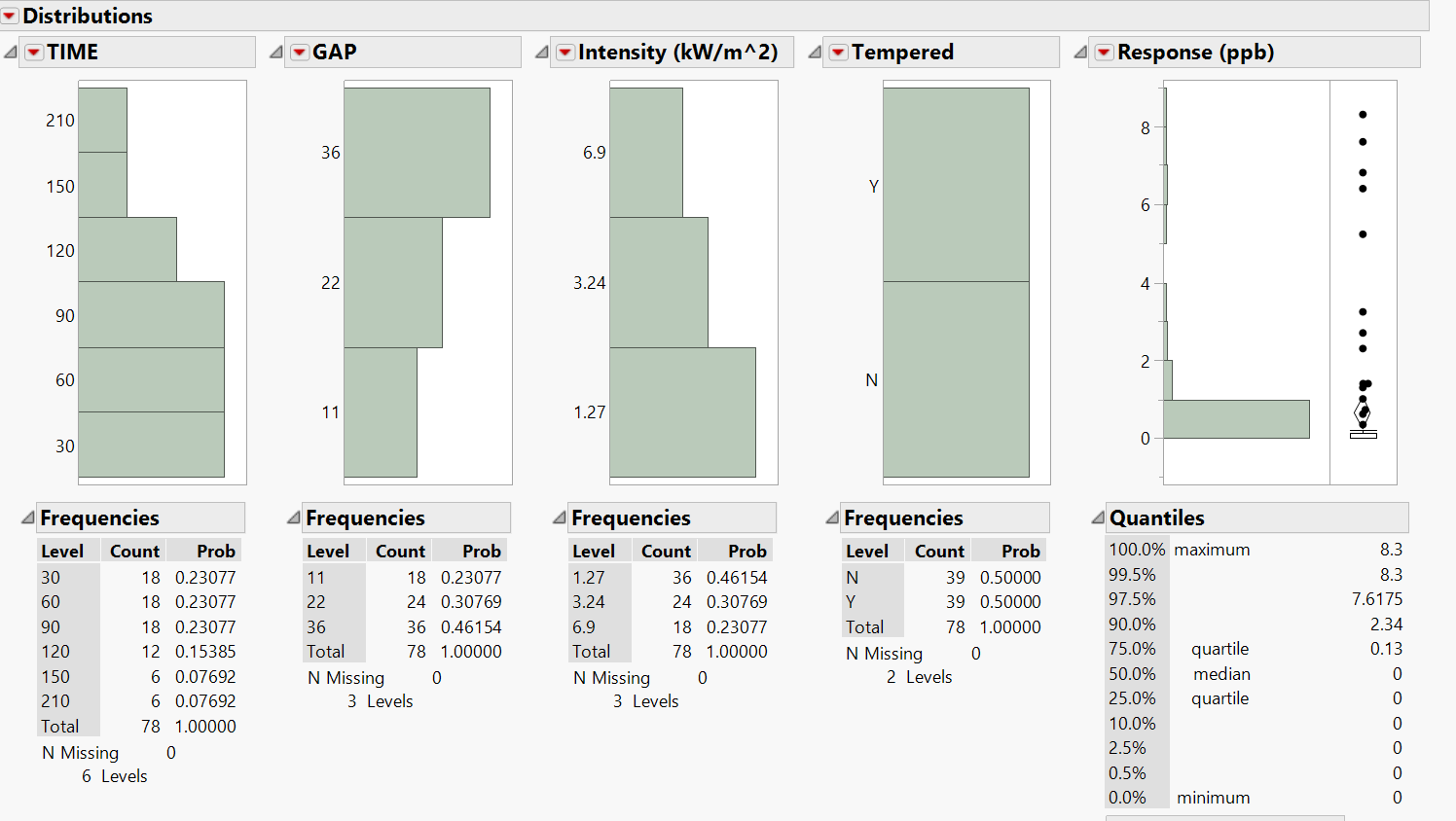
I have 4 main effects in total but each effect has different levels. For example, the time has 6 levels, Gap has 3 levels and so on. I attached a screen of my distribution analysis. Another thing is that when I did multiple regression, some variables are correlated. And also by doing full factorial, VIF showed high values. I am wondering are these VIF value true since I am not sure the full factorial is right? As I said some of the parameter estimates are missing.
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: How to analyze unbalanced data which three of independent factors are unbalanced levels?
Thanks @Shad,
It looks like you have 78 runs total according to image. Full Factoral DOE would need 108 runs for 4 categorical factors each with the levels you have specified (6x3x3x2).
I would follow @Dan_Obermiller advice and only analyze the main effects and two way interactions at this time. Otherwise you will not get any values for parameter estimates (not enought data to fit the model you are trying to fit due to all factors being categorical).
Chris
Data Scientist, Life Sciences - Global Technical Enablement
JMP Statistical Discovery, LLC. - Denver, CO
Tel: +1-919-531-9927 ▪ Mobile: +1-303-378-7419 ▪ E-mail: [email protected]
www.jmp.com
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: How to analyze unbalanced data which three of independent factors are unbalanced levels?
Dear Chris,
Thanks for the help and sorry for my delayed response. I had issues with my account access.
if I just consider the main effects and two ways interactions, I still have some missing values. For example if you notice to my data distribution, not all levels of my predictors have the same data numbers. Because it was not possible to apply all the predictors combinition to my experiment. How about if I do mixed model, put the predictors with uneven values under random effects? Do you have any idea?
Best,
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: How to analyze unbalanced data which three of independent factors are unbalanced levels?
Hi @Shad,
Ah, yes, some interactions will not work becuase there is no data. Another post had a simillar issues:
Mixed Model is not needed, One would have to exclude those interactions that do not have data like what was done with the above post. Looking at Distribution like you have to figure out which combinations do not have data should help wiht chosing which interactions to include in mixed model.
Does that help?
Chris
Data Scientist, Life Sciences - Global Technical Enablement
JMP Statistical Discovery, LLC. - Denver, CO
Tel: +1-919-531-9927 ▪ Mobile: +1-303-378-7419 ▪ E-mail: [email protected]
www.jmp.com
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: How to analyze unbalanced data which three of independent factors are unbalanced levels?
Thank you very much for the link.
In case if I remove the interactions that have missing values, I would have to remove most of interactions. Could you please suggest the best way of analysis if I am interested in knowing the interactions of "intensity by time", "intensity by Gap" and "time by Gap"?
Appreciated again all your help.
Recommended Articles
- © 2026 JMP Statistical Discovery LLC. All Rights Reserved.
- Terms of Use
- Privacy Statement
- Contact Us