Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
- New to JMP? Join us Sept. 23-24 for the Early User Edition of Discovery Summit, tailor-made for new users. Register now for free!
- Your voice matters! Tell us how you prefer to receive JMP updates, so we can tailor our communication to your needs. Take short survey.
- See how to access JMP Marketplace - and - find, create & share add-ins to extend your JMP. Watch video.
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Discussions
Solve problems, and share tips and tricks with other JMP users.- JMP User Community
- :
- Discussions
- :
- Re: DTI analysis - what do rate and prob actually mean

Level III
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
DTI analysis - what do rate and prob actually mean
Created:
Nov 22, 2022 09:14 AM
| Last Modified: Jun 8, 2023 5:57 PM
(3464 views)
Hello,
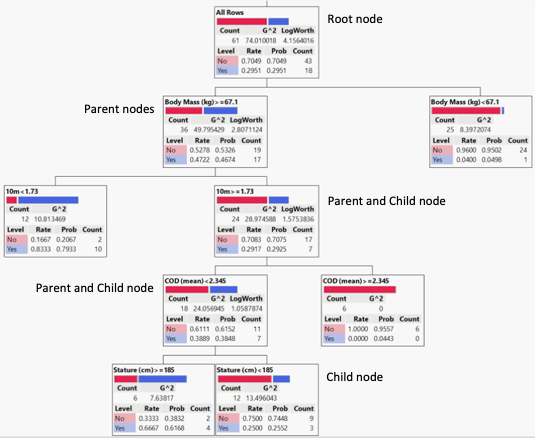
Could someone please explain or show me where I could find what rate and prob mean in this DTI, please?
I have attached a screenshot of the DTI.
Thanks in advance
1 ACCEPTED SOLUTION
Accepted Solutions
Level III
Solution
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: DTI analysis - what do rate and prob actually mean
2 REPLIES 2

Staff
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: DTI analysis - what do rate and prob actually mean
Partition actually has two rates; one used for training that is the usual ratio of count to total, and another that is slightly biased away from zero. By never having attributed probabilities of zero, this allows logs of probabilities to be calculated on validation or excluded sets of data, used in Entropy R-Square.
In the Partition platform, for categorical responses, Rate is the same as "Prob" in the Distribution Platform, and "Prob" is a slightly biased weight.

{kind=link}
This is definately confusing.
JMP Systems Engineer, Health and Life Sciences (Pharma)
Level III
Solution
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: DTI analysis - what do rate and prob actually mean
Byron_JMP,
Thanks very much for your reply!
BW,
S
Recommended Articles
- © 2026 JMP Statistical Discovery LLC. All Rights Reserved.
- Terms of Use
- Privacy Statement
- Contact Us