- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Count occurence between 2 other occurences based on time period
🙋
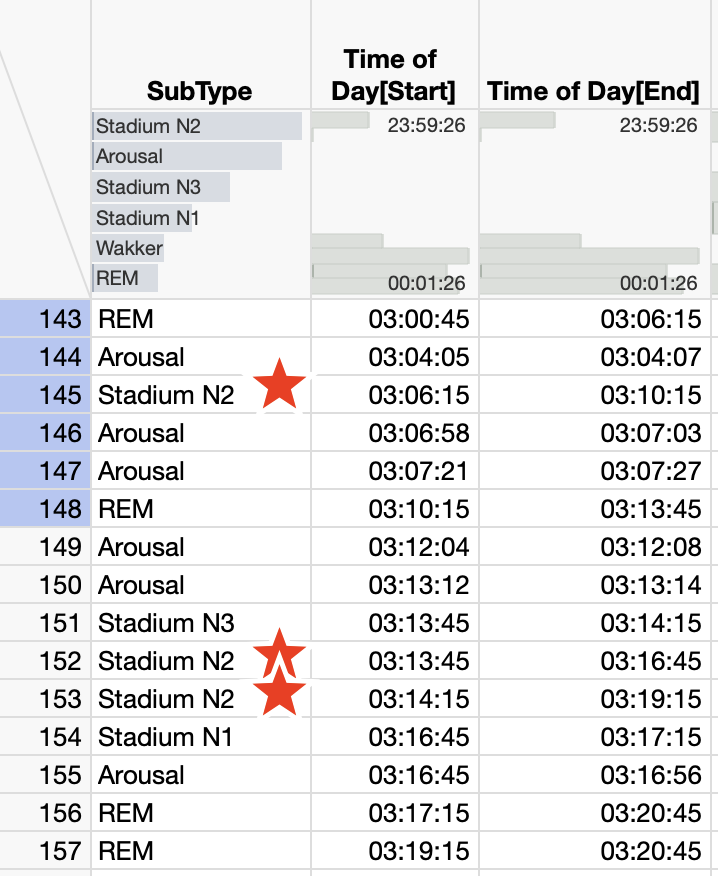
Within the column "Subtype", I need to count the number of times "Stadium N2" appears between 2 occurences of the word "REM", only when the time in column "Start" of the second REM occurence is within 15 minutes of the time in column "End" of the first REM occurence.
See stars in screenshot: in this case, the count would be 3
What is the formula to do so?
Thx
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Count occurence between 2 other occurences based on time period
How should the data be ordered for that? For example here we have first REM ending before next ends?

Or is the data already correctly ordered (I just changed the format here to be date time)? We are missing date information so how can be differentiate when day is changing or should we guess it based on the timestamps?

{kind=link}
Edit: Going with the original order of data and only caring about checking end and next start
Names Default To Here(1);
dt = Open("$DOWNLOADS/example(1).jmp");
m_sub = dt[0, "SubType"];
rem_rows = Loc(m_sub, "REM");
rem_ends = dt[rem_rows, "Time of Day[End]"];
rem_starts = dt[rem_rows, "Time of Day[Start]"];
Remove From(rem_ends, N Items(rem_starts));
Remove From(rem_starts, 1);
rem_durs = (rem_starts - rem_ends);
new_col = dt << New Column("Counts", Numeric, Continuous);
For Each({rem_dur, idx}, rem_durs,
If(rem_dur < In Minutes(15) & rem_dur >= 0,
row_start = rem_rows[idx];
row_end = rem_rows[idx + 1];
ntwos = Loc(m_sub[row_start::row_end], "Stadium N2");
ntwo_count = N Items(ntwos);
dt[row_start::row_end, "Counts"] = ntwo_count;
);
);
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Count occurence between 2 other occurences based on time period
Could you provide example data to make testing easier?

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Count occurence between 2 other occurences based on time period
Here you are!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Count occurence between 2 other occurences based on time period
One more question, is cumulative value fine? So on first Stadium N2 between two REMs it would be 1 and second 2 and so on?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Count occurence between 2 other occurences based on time period
This is definitely not the only option, but depending on the amount of data you have, something like this might work where you add two columns to your table
Names Default To Here(1);
Current Data Table() << New Column("R", Numeric, Continuous, Formula(
Col Cumulative Sum(If(:SubType == "REM", 1, .))
));
Current Data Table() << New Column("c_n2", Numeric, Continuous, Formula(
If(!IsMissing(:R),
Col Sum(If(:SubType == "Stadium N2", 1, 0), :R);
,
.
);
));
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Count occurence between 2 other occurences based on time period
Thank you for the suggestion, this indeed identifies all N2 intermittent to REM
I however need to count only those that are in between 2 REM which are maximum 15 minutes apart (most of the REM End times and following REM start times are > 15 minutes apart).
How would you integrate this time filter?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Count occurence between 2 other occurences based on time period
How should the data be ordered for that? For example here we have first REM ending before next ends?
Or is the data already correctly ordered (I just changed the format here to be date time)? We are missing date information so how can be differentiate when day is changing or should we guess it based on the timestamps?
Edit: Going with the original order of data and only caring about checking end and next start
Names Default To Here(1);
dt = Open("$DOWNLOADS/example(1).jmp");
m_sub = dt[0, "SubType"];
rem_rows = Loc(m_sub, "REM");
rem_ends = dt[rem_rows, "Time of Day[End]"];
rem_starts = dt[rem_rows, "Time of Day[Start]"];
Remove From(rem_ends, N Items(rem_starts));
Remove From(rem_starts, 1);
rem_durs = (rem_starts - rem_ends);
new_col = dt << New Column("Counts", Numeric, Continuous);
For Each({rem_dur, idx}, rem_durs,
If(rem_dur < In Minutes(15) & rem_dur >= 0,
row_start = rem_rows[idx];
row_end = rem_rows[idx + 1];
ntwos = Loc(m_sub[row_start::row_end], "Stadium N2");
ntwo_count = N Items(ntwos);
dt[row_start::row_end, "Counts"] = ntwo_count;
);
);
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Count occurence between 2 other occurences based on time period
THank you! Values were indeed already ordered by Start.
Small add-on question: I need to verify manually for correctness but can only do this after grouping by other columns :ID, :Validated, :Subtype
where and how would I fit in the grouping by?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Count occurence between 2 other occurences based on time period
Adding grouping variables would require quite a lot of changes to the script. Easiest option would most likely be to add create subset for each group, run the calculation for those and then join those back to original data table (might be necessary to add some sort of unique identifier column). Other fairly easy option would be to create single GROUP column and then loop over the different options using that BUT one must be careful with the indices.