- New to JMP? Let the Data Analysis Director guide you through selecting an analysis task, an analysis goal, and a data type. Available now in the JMP Marketplace!
- See how to install JMP Marketplace extensions to customize and enhance JMP.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Discussions
Solve problems, and share tips and tricks with other JMP users.- JMP User Community
- :
- Discussions
- :
- Re: Comparing DoEs- Why D/G/A/I- efficiencies are all the SAME and terribly LOW?

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Comparing DoEs- Why D/G/A/I- efficiencies are all the SAME and terribly LOW?
Hi,
I am working on Custom DoE (JMP16). I have 4 factors (1 continuous and 3 discrete num, with constraints). I have 1 response. I know these 4 factors are important and have interactions. My goal is to optimize the response to find the optimal factor levels that result in the highest efficiency possible. I included all quadratic and interaction effects.
I am using the I-optimality since this is not a screening design.
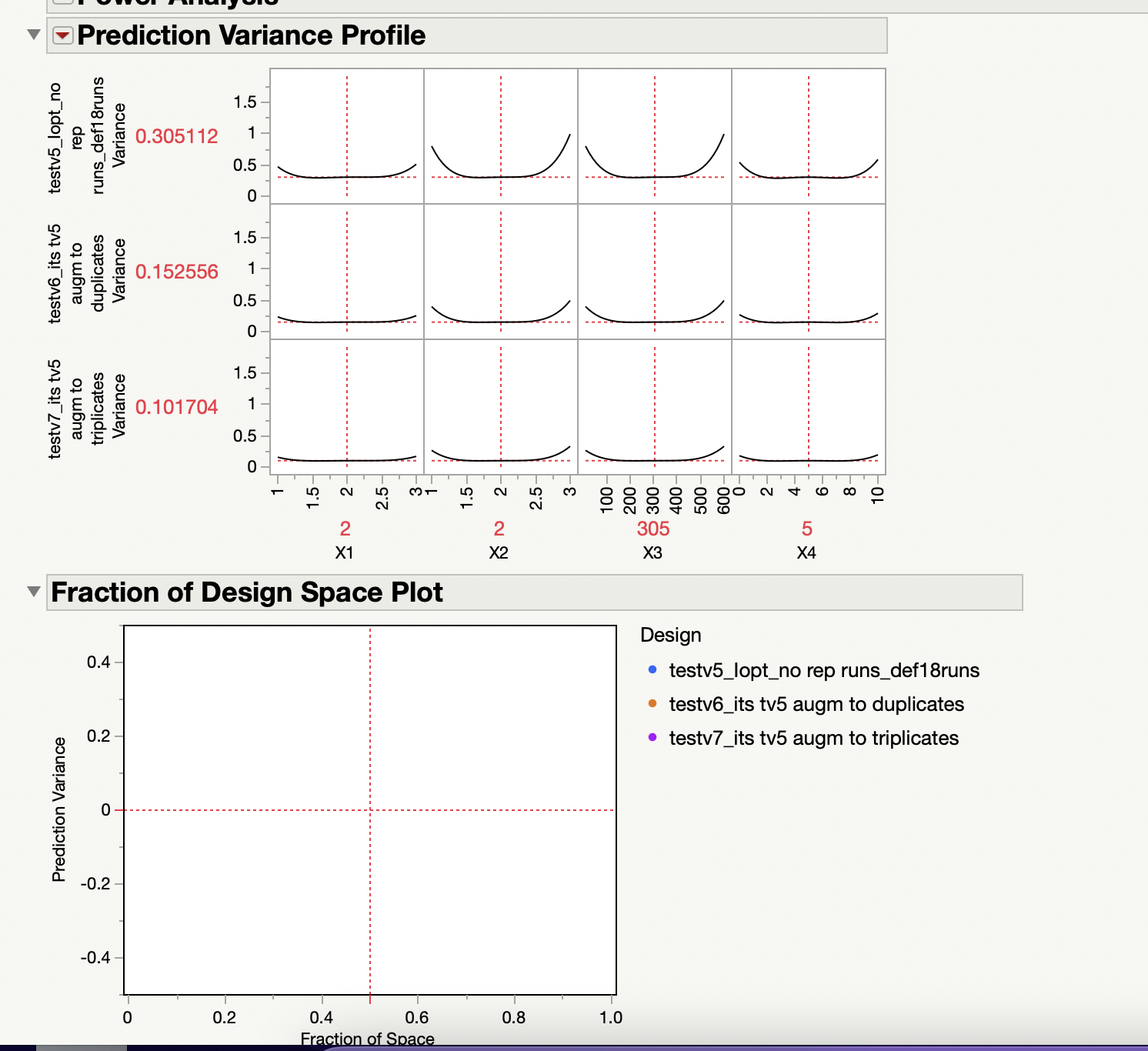
- The first design (v5) has no replicates. It has 18 runs total.
- The second design (v6) has duplicates. It has a total of 36 runs (I augmented it).
- The third design (v7) has triplicates. It has a total of 54 runs (I augmented it).
For this experiment that I plan to do, it is easier for me to add duplicates or triplicates (of the same conditions) once in the lab. That's why I don't mind if I have more runs, as long as these are of the same conditions (duplicates or triplicates), because I am able to run them all together as long as these are replicates of the same initial 18 runs.
[If instead I was to simply use the "add replicate runs" feature, then JMP adds way too many more runs with too many different conditions for me to test (resources limitation). For example, when adding just 4 replicate runs, JMP generates a design with a default total of runs =27, which is too many different conditions to test...That's why I decided to replicate my entire design instead using the augment feature.]
- I am comparing designs v5, v6 and v7 (attached). However, my "Fraction of Design Space" plot is blank. Why is it blank? or is the data very small that I can't see it?
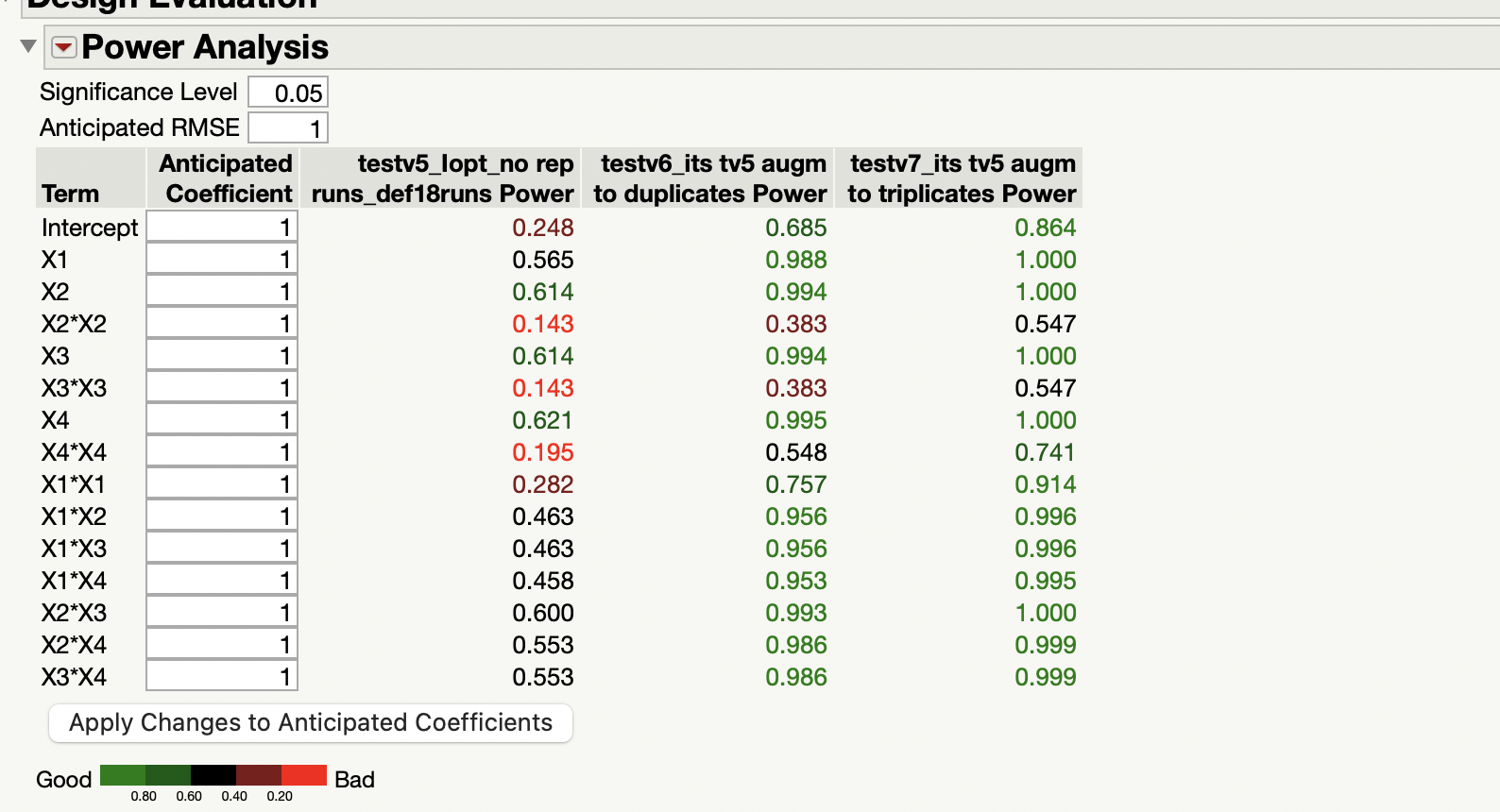
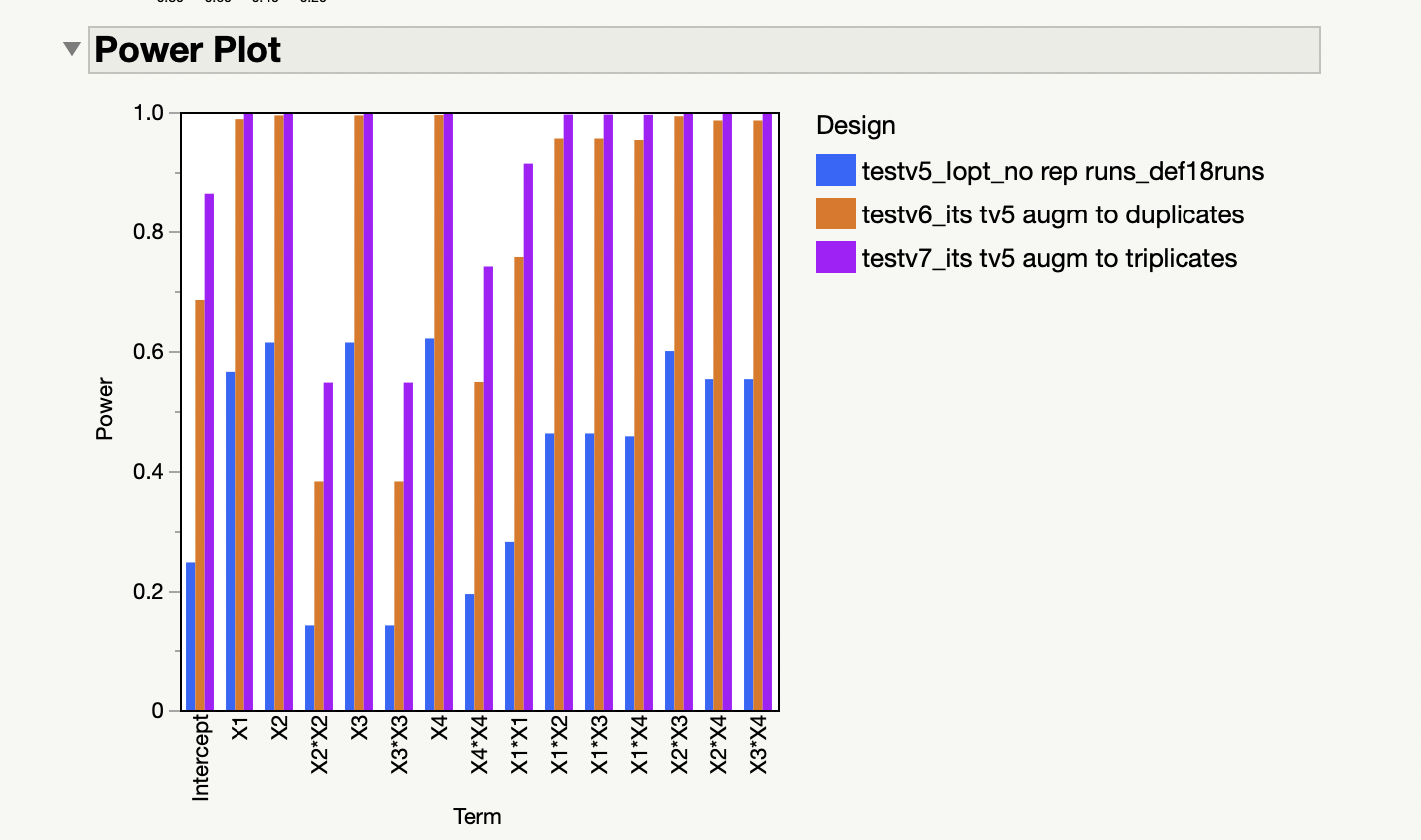
- The "Power Analysis" and "Power Plot" look pretty good for v6 and v7. But, I am interested in optimizing the response anyway (not in the main effects).
- However, the D/G/A/I- efficiencies are terribly POOR and all are the SAME. Are these all the same because design v6 is a duplicate of design v5, and design v7 is a triplicate of design v5? and why are these values so LOW (0.5 and 0.3)? Are my designs bad?
I tried to look this up but, all I found on the DOE guide is:
"Relative efficiency values that exceed 1 indicate that the reference design is preferable for the given measure. Values less than 1 indicate that the design being compared to the reference design is preferable. The 16-run design has lower efficiency than the other two designs across all metrics, indicating that the larger designs are preferable."
But, this didn't help me much.
Thank you in advance!!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Tags:
- macOS

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Comparing DoEs- Why D/G/A/I- efficiencies are all the SAME and terribly LOW?
Hi @ADouyon,
Concerning your first question about your G-efficiency lower than your D-efficiency, it's quite hard to compare different efficiencies metrics only on one design. Remember that efficiencies metrics are aggregated measures/statistics of optimality criteria, so they can provide a good overview when comparing designs, but they are not sufficient to take a decision.
- If you are concerned about the precision of your predicted responses, I think the "Prediction Variance Profile" is much more informative, as you can explore and determine in which area of your experimental space your relative variance prediction is the highest. In your latest design, you will have a relative variance prediction quite high when X2 is at the lowest level (1) and X4 at the highest (10), which is normal because due to the disallowed combinations, no points will be in this area (see screenshot "Experimental-space-X4-X2"). This may also explain why the aggregated measure for G-optimality, G-efficiency, is low (because of the restricted experimental area, increasing the relative prediction variance).
So you can gain a good understanding visualizing your experimental points/space and looking at the "Prediction Variance profile". See Prediction Variance Profile (jmp.com) for more details and for calculating actual variance of prediction.
Concerning your second question, these anticipated response values are not a prediction of the response, because if they were, that suppose you already know what are the exact value of the coefficients in your regression model, so you probably won't do an experimental design if you knew it already.
It's more a guide/help that you may use in two different ways :
- To know, based on the model your create and the model coefficients that you can freely choose/change, which values you could expect from the experimental responses (don't forget to change the coefficient of your intercept to have response values in the range of what you would expect, and not centered around 0/1, depending on the other coefficients).
- To assess, with the help of Power column, what would be the lowest difference detectable (or the probability to detect and effect) with your design, for a specific significance level and RMSE.
I hope this response will be helpful,
"It is not unusual for a well-designed experiment to analyze itself" (Box, Hunter and Hunter)
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Comparing DoEs- Why D/G/A/I- efficiencies are all the SAME and terribly LOW?
Hello @Victor_G !
Thank you so much for your reply, super helpful!!
To follow up on that, how low does the prediction variance need to be? what would be the cut off value?
In the JMP help page, it says "Low prediction variance is desired."
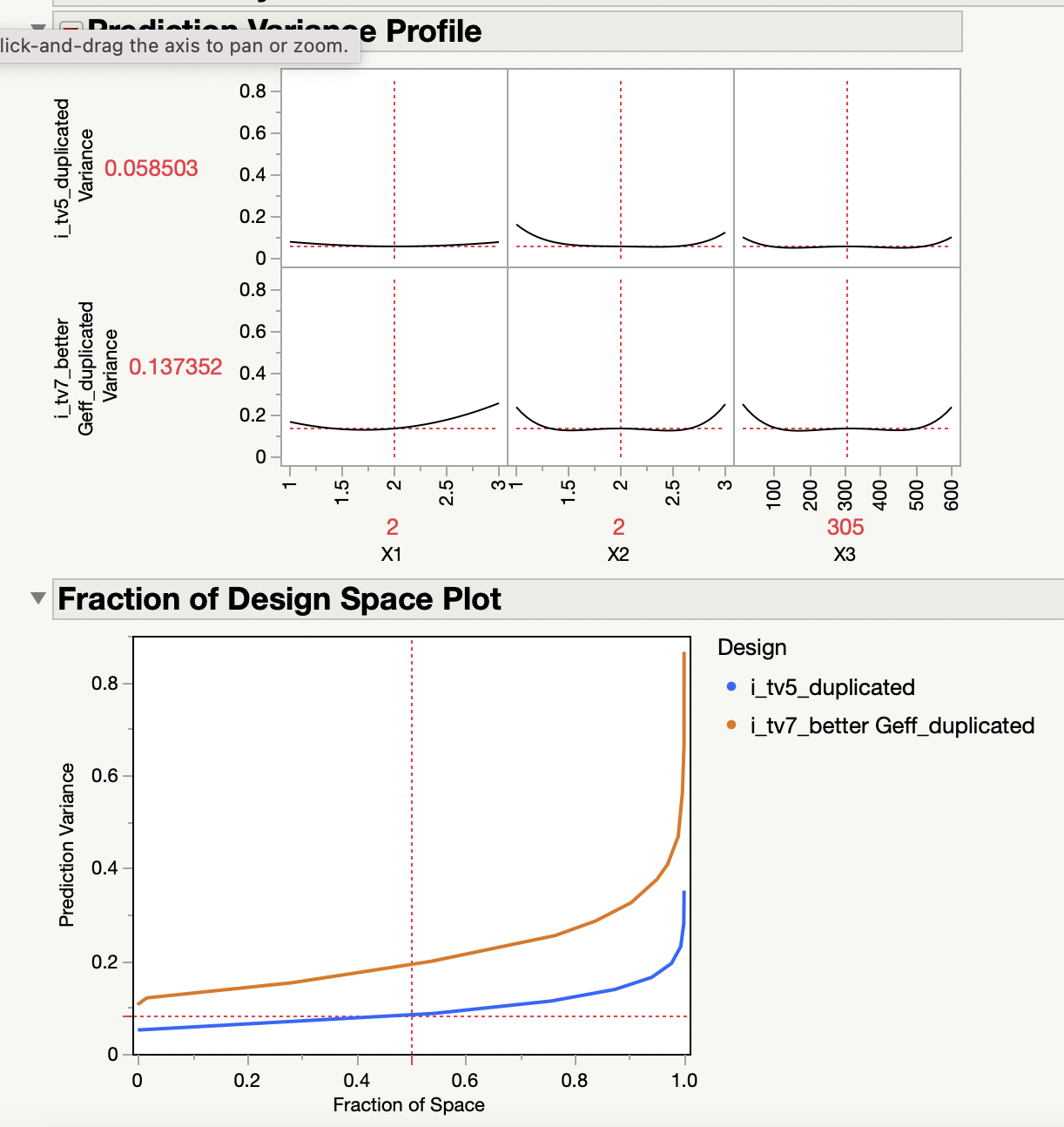
I am in between two DOE designs, 'tv5' (24 treatments, 48 runs because duplicated) and 'tv7' (12 treatments, 24 runs because duplicated), both attached. In terms of predicted variance, the design 'tv5' has better (lower) predicted variance.
But, 'tv5' has double the number of treatments of 'tv7' (24 vs 12), which means I can do the experiments much faster with 'design tv7'. Design 'tv7' only has 3 factors; I dropped 'X4' to try to reduce the number of experiments needed. I'd like this first experiment to be just a proof of concept, to show what we can accomplish with JMP, so I prefer not too have too many treatments/runs in my first design, but I am worried that the predicted variance is too high for tv7, is it?
Thanks a lot, @Victor_G !!
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Comparing DoEs- Why D/G/A/I- efficiencies are all the SAME and terribly LOW?
Hello @ADouyon,
There is no "hard rule" or "cut off value" on how low the (relative ?) prediction variance should be, as this requirement may differ depending on the topic, domain and business value. In some domains and specific applications (like pharmaceutical), there are norms about the required precision of the models, in some others this value is left at the discretion of the scientists/experimenters. There should be a compromise between an adequate precision according to the possible experimental budget and constraints of the design/experimental space.
I'm not suprised by the comparison and results you have between the two designs, as increasing the number of runs will decrease the prediction variance (you'll have more degrees of freedom, and consequently a better estimation of errors/noise and of effects).
If you're in a "proof of concept" phase and not entirely sure which factors to enter in your model and design, I find quite dangerous to remove a factor if you're not entirely sure that this factor has no effect on the response(s).
To stay safe, I would prefer start with a design that has an higher variance of prediction (but more factors evaluated), in order to be sure not to miss an effect. Once this screening is done (on main effects and interactions), you can always augment your design to decrease prediction variance (predictive model) and/or enter new terms in the model (like quadratic effects for optimization of the model).
Your choice will depend on which stage you're in for the design (screening, optimisation, prediction ?) and the knowledge you already have about your process/product/formulation/...
"It is not unusual for a well-designed experiment to analyze itself" (Box, Hunter and Hunter)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Comparing DoEs- Why D/G/A/I- efficiencies are all the SAME and terribly LOW?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Comparing DoEs- Why D/G/A/I- efficiencies are all the SAME and terribly LOW?
Hello @ADouyon,
Yes, generally you don't do only one design, but you keep augmenting it several times as your knowledge of the process/system/formulation increases.
You can start by only screening main effects (depending on the number of factors and required number of runs you may add interaction terms directly in this phase), then interactions to optimize the knowledge about the system, and then quadratic effects to build a robust predictive model.
Depending on the number and type of factors, there might be better alternatives : for example, for a high number of factors (>5, and only continuous or 2-levels categorical factors), Definitive Screening Designs (DSD) might be a good choice for screening main effects in an unbiased way, and have the possibility to detect some interaction and quadratic terms.
Hope this answer will help you,
"It is not unusual for a well-designed experiment to analyze itself" (Box, Hunter and Hunter)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Comparing DoEs- Why D/G/A/I- efficiencies are all the SAME and terribly LOW?
Thanks @Victor_G for the quick reply and for clear response!!
- So, but if one of my factors is time, then would you directly add the quadratic effects/terms in this first 'Proof of Concept' design, or would you still wait to add it later (in the next iteration) when augmenting?
I remember that in my very first post you warned me that if I have a factor that is time and is a continuous variable, I should have quadratic effects (https://docs.google.com/presentation/d/1BOYJfa54Kt2MnH5TrSpSOOr6-GLIwlJKUhZPFK8gxXM/edit?usp=sharing). Although, my time factor is a discrete numeric (due to I can't accept decimals) factor with 3 levels, does this make a difference?
- In JMP DOE, it seems that we really separate things into buckets depending on the purpose; 1) screening, 2) optimization, 3) predicting.
But, do people always have such a clear separation in their work/design?
My design has 4 factors, of which 3 I know for sure have a significant main effect. There is only 1 factor (X4) that I am not sure if it will be very significant in the design (I suspect, it won't be as significant as the other 3, but I have no proof). I suspect that the interaction effects will be significant with most of the interaction terms (probably all those except the ones interacting with X4, which again I don't think will be as significant, but I have no proof). [And, I suspect I will have quadratic effects also...]
Thus, it seems that my design is like a mixture of screening (because I have one factor I don't know anything about) + optimization (because I have 3 factors that I am 99.999..% sure have a real significant effect). Would that make any sense? Could you clarify this @Victor_G since this affects the optimality criterion chosen to start with (I am confused if I should choose D- or I-optimality)?
Thanks a million @Victor_G!!!
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Comparing DoEs- Why D/G/A/I- efficiencies are all the SAME and terribly LOW?
Hi @ADouyon,
- You're right, since you add few factors to screen, I recommended you to add quadratic effect for time, since chemical or biological process are rarely linearly dependent over time, so it may be best to have this quadratic term directly in the model. And since you had "constraints" with this time factor (for decimals), you choose a discrete numeric type with 3 levels for this factor, which automatically adds the quadratic terms in the model with the estimability "if possible", so you should be ok with these settings.
- These buckets are not entirely separated from each others, it's more a help and to guide you during your DoE creation process, to self-assess at which stage you are. Depending on your experimental budget, it can be tempting to do only one big DoE, but it may be a lack of ressources, as most of the effects won't probably be significant or have a big influence on the response. This is why I tend to describe the use of DoE during a study with these 3 steps : screening, optimization and prediction, as it helps to figure out what you already know about the system, and what you would like to know to further understand and predict your system. I used in previous DoE trainings the figure I have inserted as a screenshot here. But as you say, depending on the situation it may look a bit over-simplistic and all studies using DoE don't go through these 3 stages, as previous knowledge, domain experience or historical data can help have a fair understanding of the system.
In your case, your number of factors is quite low, but you're unsure about the significance of some effects (X4 and interactions/quadratic effect involving X4). So I would choose a D-optimality criterion in order to assess parameters estimates as precisely as possible, and have the possibility to sort significant effects from non-significant ones.
Your design does make sense, and the 24-runs DoE ("i_tv5_Iopt_changedEst_remov2_24runs") done before replication looks like a good compromise between runs size and screening of effects. And due to the presence of 5 replicate runs, you should be able to estimate noise in your response and lack-of-fit.
It may not be already a predictive model (depending on the precision you want to have), but it's a first good step in assessing which terms are significant, and from there, you can augment the design to improve the prediction precision.
I hope this answer will help you,
"It is not unusual for a well-designed experiment to analyze itself" (Box, Hunter and Hunter)
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Comparing DoEs- Why D/G/A/I- efficiencies are all the SAME and terribly LOW?
Hello @Victor_G , thank you VERY much for the clarification and quick response, as always!!
I polished my design now to include all 4 factors (not ignoring X4 since the effect of this factor is still completely unknown) and all interactions with estimability set to 'necessary', as well as the quadratic effect of my time variable (X3) also set to 'necessary'. I kept the other quadratic effects of the other 3 variables (X1, X2, X3) with estimability set to 'if possible' as I presume there will be curvature, so I'd like to augment the design in the future.
[I expect significant effects from the interaction terms with most factors, except interactions with variable X4, which factor I don't have any information in advance. That's why, I kept all the interactions to estimability set to 'necessary' in this polished design].
In my pervious design, "i_tv5_Iopt_changedEst_remov2_24runs", I had removed the terms 'X1*X1' and 'X2*X4', but since I don't have any evidence of these not being significant, (and based on the various clarifications you helped me with) I decided to keep them in the new polished design ('X1*X1' with estimability set to 'if-possible', and 'X2*X4' set to 'necessary').
The polished design named "tv6_Dopt_24rns_QTermsIfPoss_ExceptX3X3_110322" is attached.
The variance seems to have increased now, but from what you've explained me, I understand this is okay since I plan to augment this design in the future.
Now, I was wondering, how important is the "blocking" variable?
My experiments can be run in a (reaction) container that can specifically test for up to 12 different conditions (treatments) at a time. Since, this design has 24 different treatments (24 runs), I will have to run 12 treatments first and complete that experiment. Then, separately, once I am done with this first batch of 12 treatments, I will do another experiment with the rest of the 12 treatments. Should I add the "blocking" variable, then?
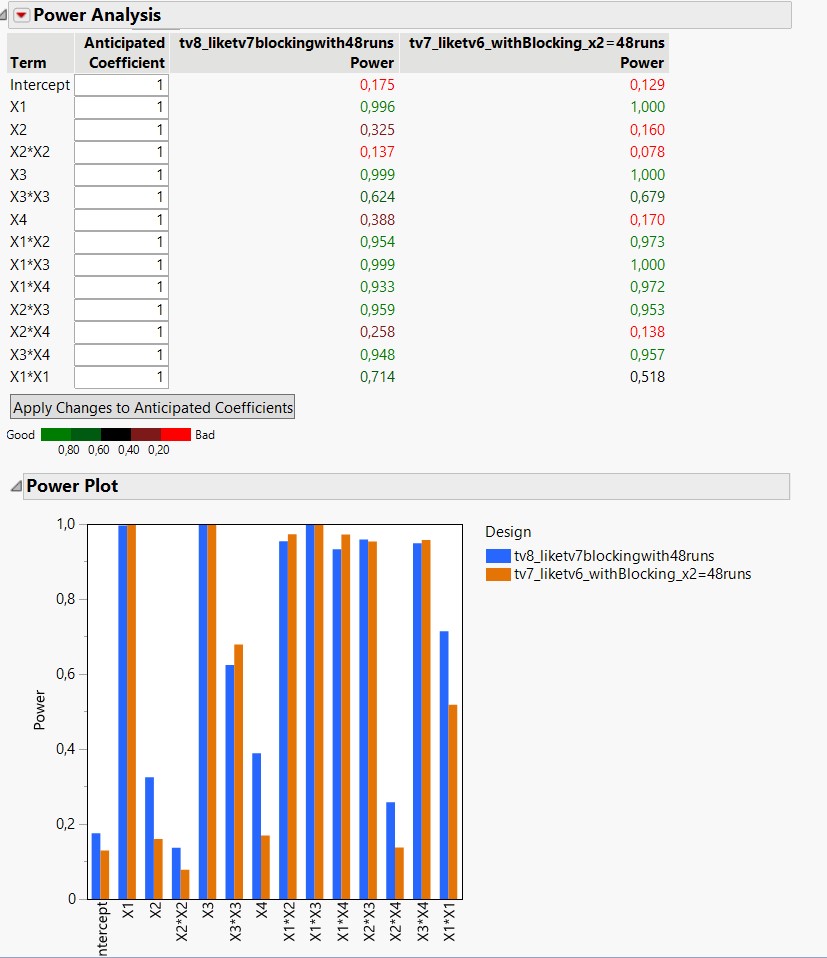
I tried adding this "blocking" variable by inputting the number '12' where it says "Group runs into random blocks of size" (= 12) (design attached, named "tv7_liketv6_withBlocking"). I noticed that this increased my variance slightly (see screenshot, color orange for this tv7 design.
1- Did I do this part correctly @Victor_G ?
2- And, since I have room in the container for duplicates, I can also now augment the design to duplicate it, right? What do I do with the "random block" variable when duplicating the design? See the 1st screenshot attached, should I also add it into the 'X, factor' box?
Thanks a lot @Victor_G !!
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Comparing DoEs- Why D/G/A/I- efficiencies are all the SAME and terribly LOW?
Hi @ADouyon,
Great, I think it makes more sense to first be sure about main effects and interactions, and then augment the design to optimize variance prediction.
1- If you can run your experiments by batch of 12 runs, it is safer and recommended to use blocking. In your case, a random block like you did seems a good choice, as you're not particularly interested in knowing the difference between the two runs, but more on the variability in the two runs.
2- The problem with the "Augment Design" platform is that you will probably lose your random blocking (because even if you put it in the factors before launching the platform, it won't be taken into consideration after, and you'll only have access to "Augment" option, not the "Replicate" one). Two options to be able to augment your design and replicate it :
- You just copy your first 24 rows, paste it after, and change the random block levels (1 becomes 3, 2 becomes 4).
- You directly generate a 48 runs design, by specifying in the design generation that you want 24 replicate runs, by group of 12 experiments. You'll end up with design tv8 (attached), and from there, you can directly run the 48 experiments of this design if you have enough experimental budget.
The two approaches are similar, even if the second one (tv8 compared to augmented tv7 by copy/paste) is more efficient (better repartition of experimental runs in the different blocks, see screenshots).
"It is not unusual for a well-designed experiment to analyze itself" (Box, Hunter and Hunter)
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Comparing DoEs- Why D/G/A/I- efficiencies are all the SAME and terribly LOW?
Thank you so much, @Victor_G, for your invaluable assistance in refining this design! I sincerely appreciate it!!!
I now feel more comfortable and confident in testing this design in the lab =)
Thank you for all your super helpful clarifications and for always answering so fast!
Have a great weekend, @Victor_G!!
Recommended Articles
- © 2026 JMP Statistical Discovery LLC. All Rights Reserved.
- Terms of Use
- Privacy Statement
- Contact Us