Stan Koprowski's Blog
- JMP User Community
- :
- Blogs
- :
- Stan Koprowski
- :
- Using JMP's Query Builder to access Proficy* Historian Databases
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content

Accessing an Object Linking and Embedding, database or OLEDB from JMP's Query Builder (QB). I often get asked by customers is it possible to access our Proficy Historian database from JMP? So I thought I would share some options to answer the question of How do I access data that was built around the COM-based interface such as Historian?
JMP’s scripting language or JSL provides just the resources needed to access any type of data that might be required that is not already available directly from within the file open dialog. JMP provides a plethora of prebuilt data connectors that can read directly data from many flat file data sources such as, Triple-S XML, CSV, SAS, and SPSS. I won’t focus on this type of file in this blog post but will instead focus your attention on accessing data from relational databases such as, Oracle, PostgreSQL, and SQLite or from other OLEDB sources such as Historian.
Accessing relational databases is done using the JMP Query Builder interface. QB can be accessed by going to the File menu and selecting Database and then Query Builder.
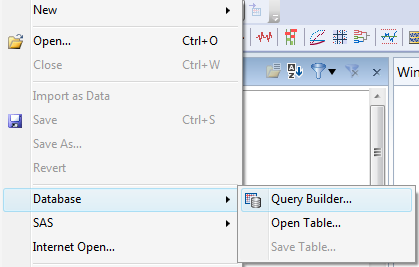
As this approach is familiar to existing JMP users I decided this would be a good preliminary step for accessing data from non-ODBC data stores such as the Historian database.
Here I present two approaches and the details for each of the respective solutions. Additionally, I provide some thoughts as to the benefits and constraints for each of the solutions. The first is via a custom query and the second is via a conversion or snapshot of the OLEDB to a form more easily consumed by JMP Query Builder.
The first approach coincidentally is the straightest forward approach to accessing the Historian OLEDB using JMP’s Query Builder. It simply makes use of a custom query. The only database configuration required was to create a database link from SQL server to the Historian OLEDB.
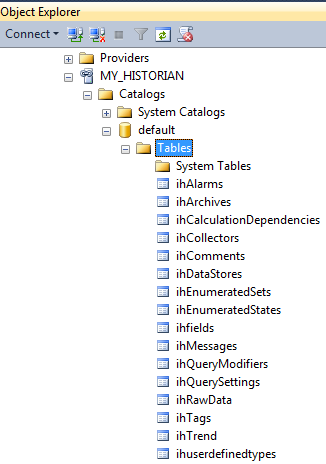
Establish a connection to the database using the linked server as shown below (in my case the linked server name was called "MY_HISTORIAN").
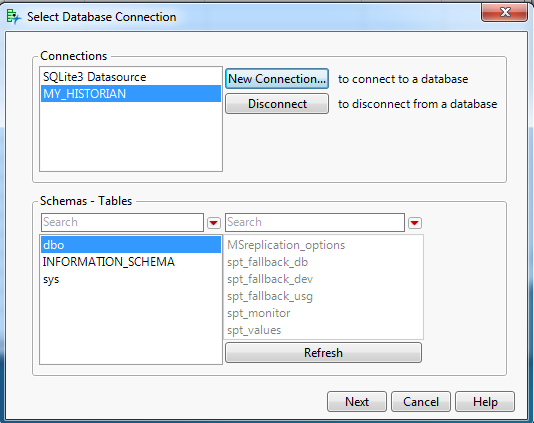
Click next to bring up the query builder dialog. The dialog will allow you to select schemas and tables from within a schema to be used for building the query. Select any of the schemas and a table from the SQL server connection (any table will work as we are not actually using directly). I chose the sys schema and the all_columns table as my primary data table.
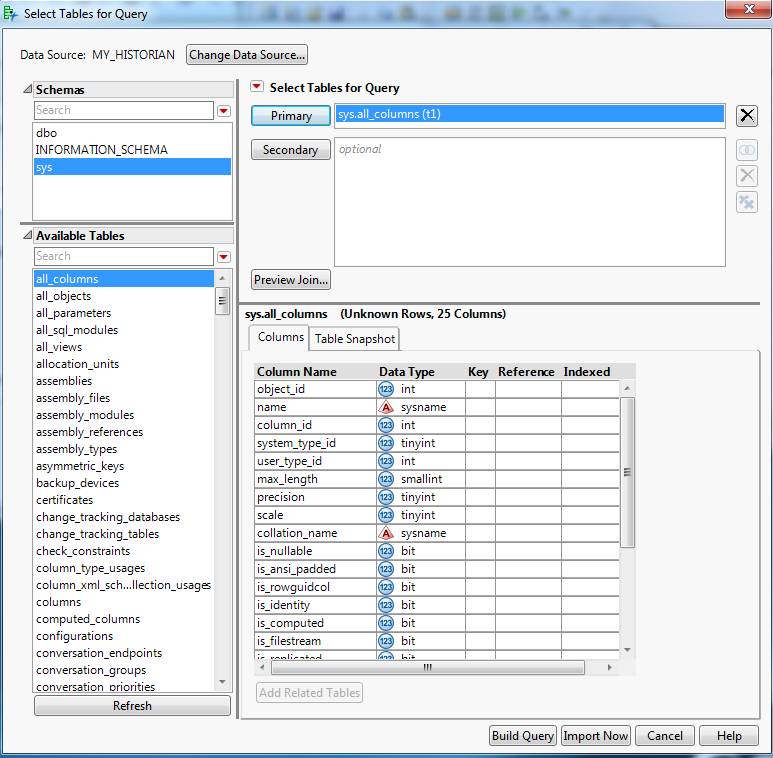
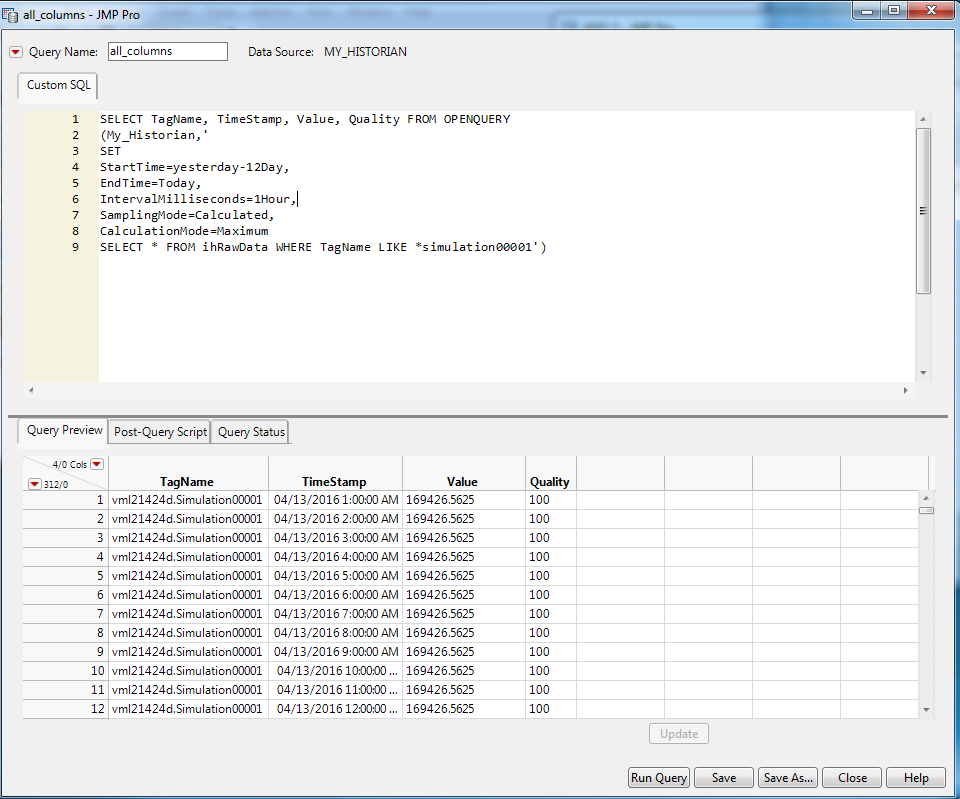
SELECT TagName, TimeStamp, Value, Quality FROM OPENQUERY (iHist,' SET StartTime=yesterday-12Day, EndTime=Today, IntervalMilliseconds=1Hour, SamplingMode=Calculated, CalculationMode=Maximum SELECT * FROM ihRawData WHERE TagName LIKE *simulation00001')
For those not familiar to the use of JMP's Query Builder I have provided a link to some additional resources including a Advanced Mastering JMP session presented by chris.kirchberg.
The second approach does not require any database configuration changes. However, it does require the installation of Python and an additional Python library (win32com.client). Simply install the OLE Database Tools addin and follow the prompts. The addin executes a Python script (thanks for the help on writing the Python script from bryan.boone) that in turn creates a snapshot of the OLEDB and saves it out as a SQLite DB. The SQLite DB can then be directly accessed from QB as shown. External programs such as Python can be executed by using the JMP scripting language or JSL. JSL has a function called Run Program. An excellent paper was presented at our recent Discovery Summit Europe on this very topic from hecht@jmp entitled "Run Program - The JMP® Link To Other Programs" which provides several detailed examples on how to use this function.
The Python script runs some command line options that are passed to it from the user interface (UI). The UI was built entirely with JSL and made deployable to any analyst by packaging it up as a JMP addin. To install the addin the analyst simply double-clicks. The addin is now available to use from the addins menu.
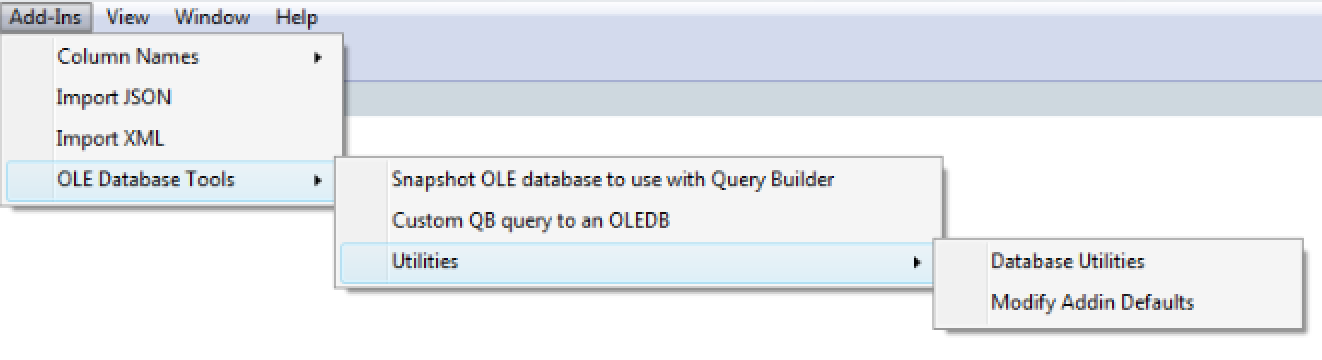
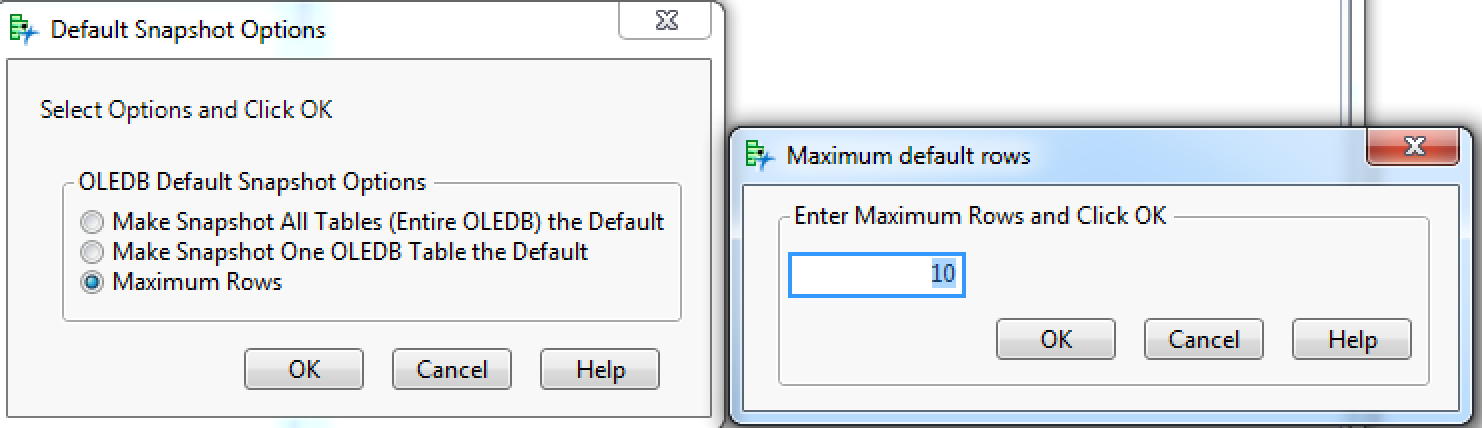
Three menu options are available for selection. The menus are entitled Snapshot OLE database to use with Query Builder, Custom QB query to an OLEDB and Utilities. The first option converts an OLE database or a single OLE database table to a SQLite database format. The custom QB query option submits a query built with JMP Query Builder (QB) to an OLE database for processing. The last options under the Utilities menu allow for removal of a table or all the data from the SQLite database and options for modifying the default choices in the addin. With the last option under the utilities menu I provide a mechanism to update the default settings for the addin. If the number of observations is large use the option to set the maximum number of rows to retrieve from the OLE database. Below I show how to set the maximum number of records to return to 10. Setting the maximum records to -1 will retrieve all rows for each table in the OLE database.
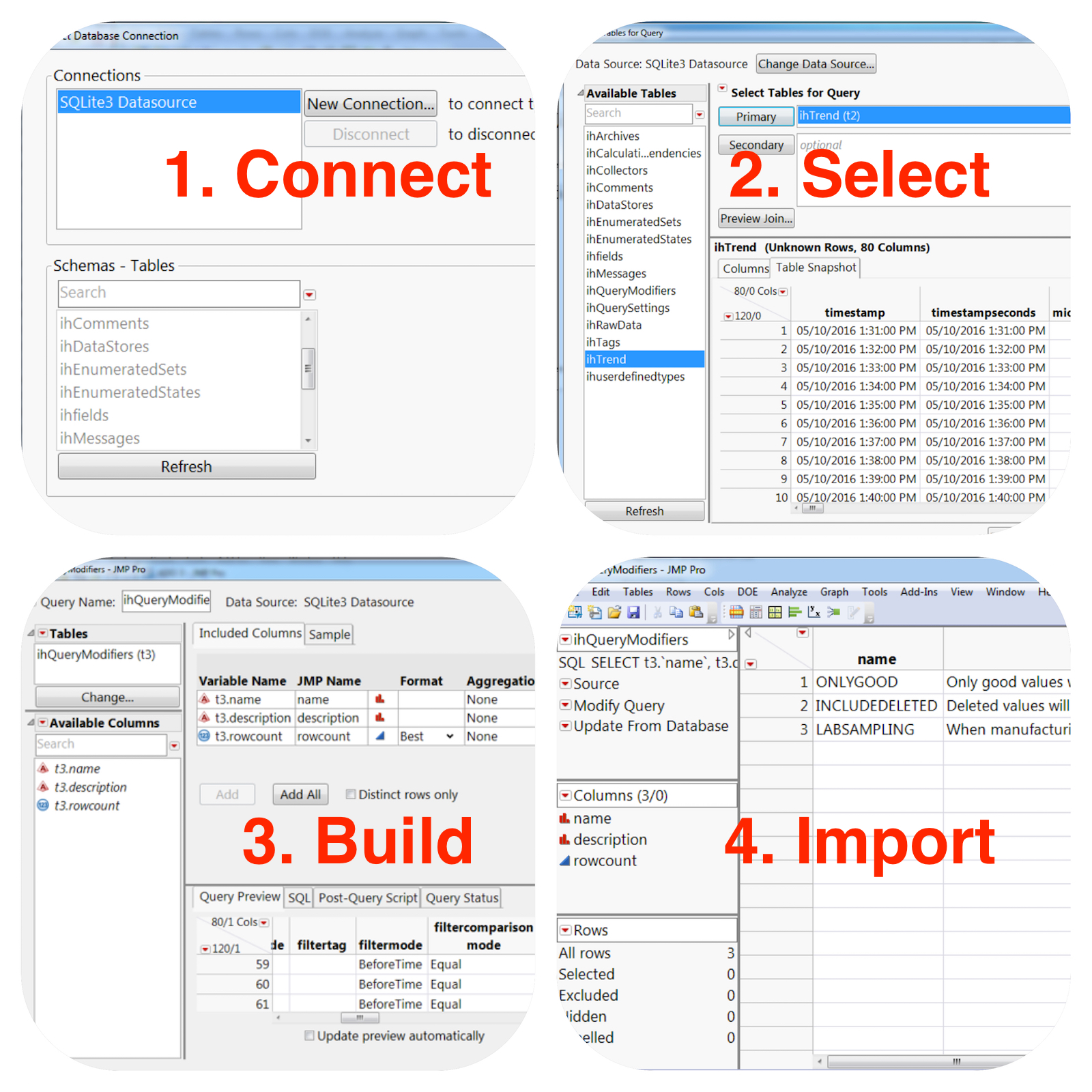
Connect. Select. Build. Import.
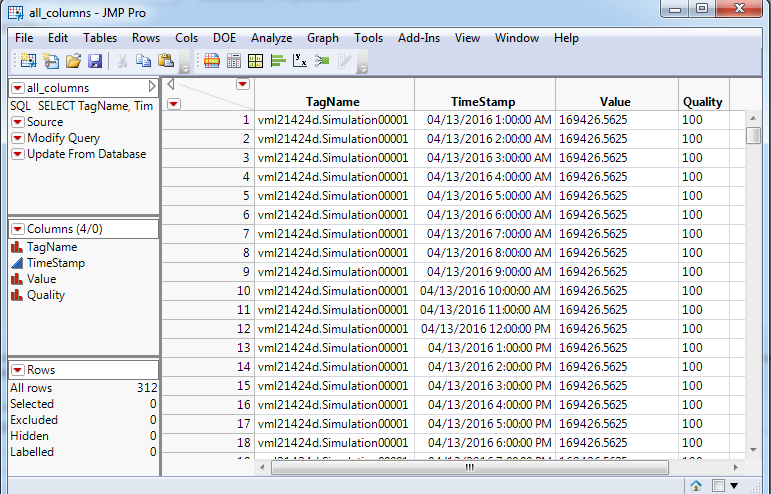
Use QB to establish a connection to the SQLite database that was just created. Now you can use the same interface to begin building your queries. Once you have built a query you like run the "Custom QB query to an OLEDB" option to copy the query to be executed by the Python script a second time. This time when the query executes it will return all the rows that match the where clause of the query. Now with the table available in JMP you have the full access to JMP visualization and modeling capabilities.
What data sources do you connect to routinely? Were you aware of the Run Program function within JSL?
Leave me a comment with any data sources you routinely connect to or other ways that you have used Run Program in your own scripts.
Until next time...Happy Coding!
*GE Intelligent Platforms, Inc is a wholly-owned subsidiary of the General Electric Company. The GE brand and logo are trademarks of the General Electric Company.
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
- © 2026 JMP Statistical Discovery LLC. All Rights Reserved.
- Terms of Use
- Privacy Statement
- Contact Us