- New to JMP? Join us Sept. 23-24 for the Early User Edition of Discovery Summit, tailor-made for new users. Register now for free!
- Your voice matters! Tell us how you prefer to receive JMP updates, so we can tailor our communication to your needs. Take short survey.
- See how to access JMP Marketplace - and - find, create & share add-ins to extend your JMP. Watch video.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Discussions
Solve problems, and share tips and tricks with other JMP users.- JMP User Community
- :
- Discussions
- :
- Re: Using XGBoost Model to Predict on a hold-out test set

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Using XGBoost Model to Predict on a hold-out test set
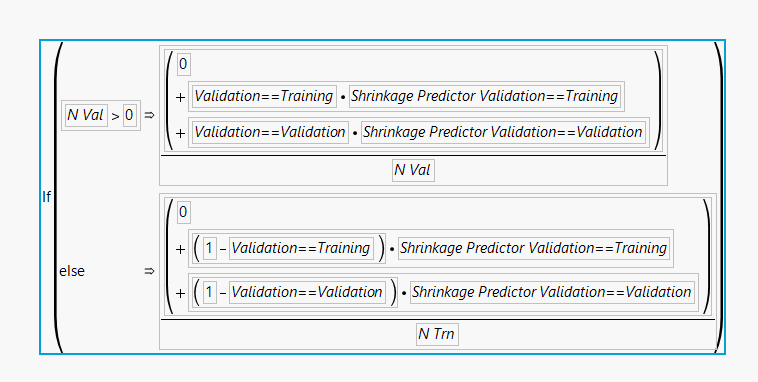
I am using JMP 16. I installed the XGBoost addin. I developed a xgbbost model using this. I saved the model in the data table using 'Save Prediction formulae'. Now, I have a separate hold-out test set on which I want to run the formulae to get the prediction. If I click the formulae (see attached figure), I found that the formulae depend on the training and validation set, which seems odd to me. This also hinders me to run the model for the hold-out test set.
{kind=link}

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Using XGBoost Model to Predict on a hold-out test set
I'm not sure I know the answer to your question, but it appears you do not have any variables in your model (the column names are validation and training and shrinkage predator validation)? So the formula is a function of those column names. Either re-write the model in terms of variables or re-name the columns of your hold out data set?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Using XGBoost Model to Predict on a hold-out test set
I added the jmp file. If you look into the XGBoost model, you can see the details. I have 17 variables.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Using XGBoost Model to Predict on a hold-out test set
Your data set is the same as the one used in the help menu for the XGBoost add-in. Did you follow the steps shown in the application of the platform?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Using XGBoost Model to Predict on a hold-out test set
Yes. I did. I was not able to still get the formulae.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Using XGBoost Model to Predict on a hold-out test set
Sorry I haven't had time to look at your data. I'm also not very experienced with the platform, but my guess is you should use the platform to find the significant factors and then re-write your model in fit model and run it and save the prediction formula...but again, I'm not experienced here. Perhaps there is an easier way to get the actual model in terms of the variables in the data table...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Using XGBoost Model to Predict on a hold-out test set
Can you show me over a webex call?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Using XGBoost Model to Predict on a hold-out test set
I suggest getting in touch with Russ: XGBoost Add-In for JMP Pro

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Using XGBoost Model to Predict on a hold-out test set
Hi @sukrit2020 ,
A recommended approach is to append your separate hold-out test set to the main data as new rows with the Y target values set to missing. Then the formula will automatically create predictions on those rows.
Also, it's important to note that XGBoost handles validation differently than other JMP platforms. If the validation column is Nominal, it will automatically do full k-fold with each of the levels. This is why the formula looks like it does. This can be confusing if your validation column has two levels, e.g. "Validation" and "Training". In this case XGBoost would actually do 2-fold, holding out each subset regardless of their values.
A better way to set up your folds is to use the Make K-Fold Columns utility, and then use those as your Validation columns. I feel repeated k-fold is a much better way to validate your model than using a single holdout set. If you really want to only do a single holdout, you must set the type of the Validation column to Continuous, with value 0 corresponding to training and 1 to validation.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Using XGBoost Model to Predict on a hold-out test set
Hi Russ,
Can we set up a webex where you can show me the procedure? I am little new to JMP and thus could not fully follow your instructions.
thanks,
sukrit
Recommended Articles
- © 2026 JMP Statistical Discovery LLC. All Rights Reserved.
- Terms of Use
- Privacy Statement
- Contact Us