- New to JMP? Join us Sept. 23-24 for the Early User Edition of Discovery Summit, tailor-made for new users. Register now for free!
- Your voice matters! Tell us how you prefer to receive JMP updates, so we can tailor our communication to your needs. Take short survey.
- See how to access JMP Marketplace - and - find, create & share add-ins to extend your JMP. Watch video.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Discussions
Solve problems, and share tips and tricks with other JMP users.- JMP User Community
- :
- Discussions
- :
- Partial Least Squares VIP coefficients in JMP pro

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Partial Least Squares VIP coefficients in JMP pro
Hello,
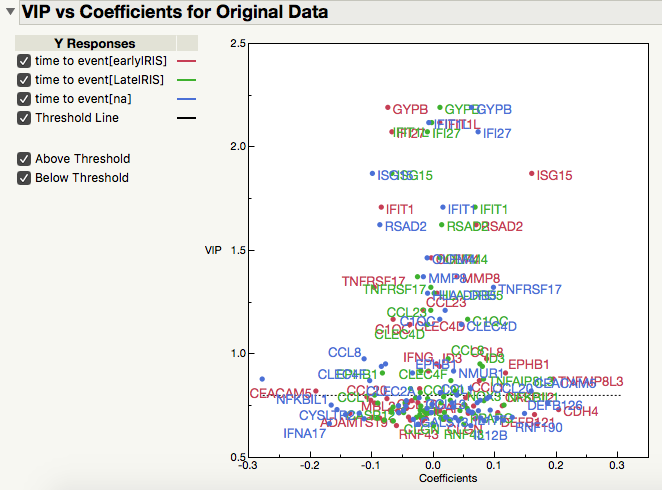
I am struggling to understand the difference between NIPALS and SIMPLS, and why those two give me such a low VIP coefficients for my Y with same set of Xs (I have 1000 of them). I have 3 levels within X: I expected different correlation coefficients for all 3, but they are very closed to each other. Am I using PLS correctly?
{kind=link}

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Partial Least Squares VIP coefficients in JMP pro
Here you are predicting all Y variables at the same time so I believe the VIP is related to the importance of predicting any and all X and Y variables. If you run the analysis three times with one Y variable each time you will see different VIP values for each X variable.

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: Partial Least Squares VIP coefficients in JMP pro
Of course you will get different predictor variable results by using PLS in series, once for each response all by itself, compared to using PLS incorporating all the responses simultaneously. One of the unique and valuable characteristics of the PLS approach is to leverage correlation/covariance strutures among BOTH the x and y variables for those situations where using other regression based methods are problematic. One of the basic attractions of PLS is dimensionality reduction hence the idea of leveraging the latent structures that can be found using these methods. A great reference for PLS is:
Recommended Articles
- © 2026 JMP Statistical Discovery LLC. All Rights Reserved.
- Terms of Use
- Privacy Statement
- Contact Us