- We’re retiring the File Exchange at the end of this year. The JMP Marketplace is now your destination for add-ins and extensions.
- JMP 19 is here! Learn more about the new features.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Discussions
Solve problems, and share tips and tricks with other JMP users.- JMP User Community
- :
- Discussions
- :
- Re: I can't understand my data

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
I can't understand my data
I need to calculate the prevalence of a group of ectoparasites in birds, and test the hypotheses about the effects of host and parasite life-history parameters on the prevalence of these ectoparasites. I've been told to use GLMM, and I started using it on jmp, but I can't understand the output of the program. I believe the input data is wrong and I can't figure out why...
My response variable is presence vs absence (0/1), my random effect is the suborder of the ectoparasites (A/B), and my fixed effects are their diet (blood/feather), ecomorph (A, B, C, D), and dispersal (0/1/2).
For the samples that the parasite is absent, the fixed and random effects rows have an N/A.
I would like to understand if the model that I'm trying to build is correct.
Thanks!

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: I can't understand my data
First of all, this community is for JMP, not Microsoft, so you should provide your example in JMP, not Excel.
What distribution did you use with the GLMM? What link function did you use?
I do not see that the sub-order is a random effect. Do you have a term in the model for the subject, sample, or block? it is likely the random effect in the response.
Can you show the results as a picture of the JMP platform?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: I can't understand my data
Sorry, I'm new to the platform. I apologize for my mistake.
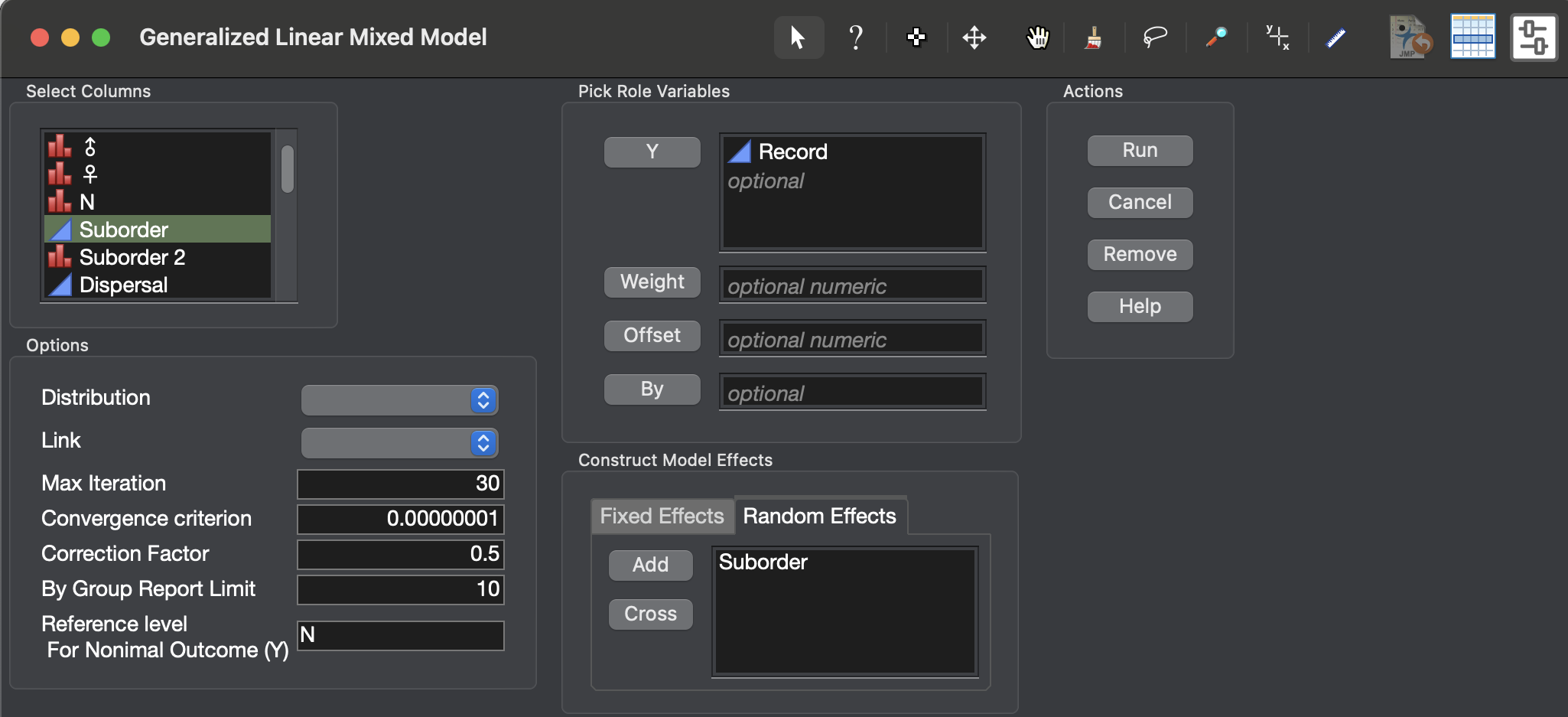
I thought that the suborders would be the random effect because the fixed effect depends on it. Depending on the suborder, the diet, the dispersal, and the ecomorph are dictated. I attached the screenshots of my model and the output I got from the program.
On the effect summary, the effects don't have any value. Would that mean that they don't have any effect on the prevalence?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: I can't understand my data
You say, "suborders would be the random effect because the fixed effect depends on it." Are you talking about nested levels. For example, in this case

{kind=link}
{kind=link}
{kind=link}
{kind=link}
If the levels of Factor B are such that level 1 in the first row is the first and level 1 in the third row is first, but they are not the same level, then Factor B is nested in Factor A. Think of a case where two parts are test at both levels of Factor A, but they are not the same parts. There are then actually 4 parts tested. On the other hand, if Factor B = 1 is the same for Factor A = 1 or 2, then Factor A and Factor B are crossed. Using the same example, there are only two parts that are each tested under both conditions of Factor A.
I need to know which case (crossed or nested) to be sure that you specified the fixed effects correctly.
I would still try to include Sub-order as one of the fixed effects. If that works, then you do not need GLMM. You can use GLM personality instead.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: I can't understand my data
Yes, they are nested factors! Each suborder occurs in combination with different levels of variables.
Specifically, suborder A will feed only on blood, and suborder B will feed only on feathers. Then suborder A doesn't can't disperse or has an ecomorph, while suborder B can disperse or not and have a set of four different ecomorphs.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: I can't understand my data
So you do not need any random effects. You indicate the nesting by adding the top and bottom factors to the effects first. Then select the top factor in the column list and the bottom (nested) factor in the effects list, and click Nest.
Please reply with your result.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: I can't understand my data
Ok, thanks!
Both the dispersal and ecomorph were not significant, and the diet and suborder don't have a value, so this means that none of them are affecting the prevalence?
Recommended Articles
- © 2025 JMP Statistical Discovery LLC. All Rights Reserved.
- Terms of Use
- Privacy Statement
- Contact Us