- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Discussions
Solve problems, and share tips and tricks with other JMP users.- JMP User Community
- :
- Discussions
- :
- How to represent the Y response of the decision tree as a variable?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
How to represent the Y response of the decision tree as a variable?
dear all
I want to do multiple data table files with the same code for the decision tree operation, and each file has three different Y response decision trees.
Set the Y response of each file in the first 3 columns of the table, and the number of X factor column starting from column 4 is different for each file.
The specific practice of making three decision trees for each file is: the first time is carried out with the Y response of column 1;The second time was done with the Y response of column 2;The third time is done with the Y response of column 3.
The X factor used each time starts with column 5 and ends with column 2.The second X factor to the second X factor.
How to code this decision tree code so that the same code can perform operations in different files.
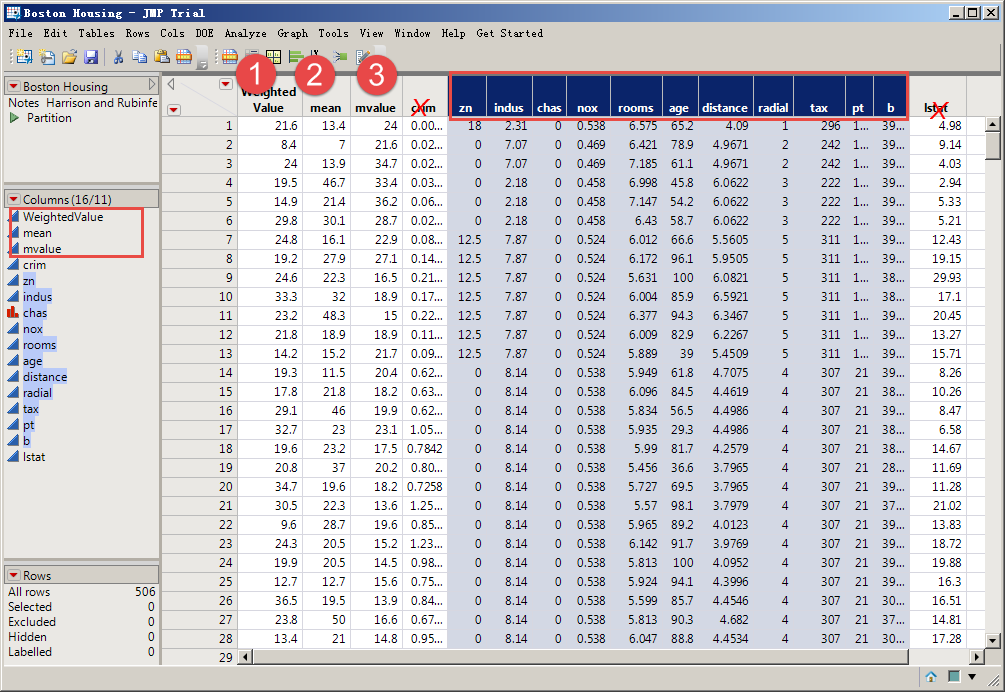
In the annex, Boston Housing.jmp adds 2 columns to the Y response so that 3 columns of the Y response are available and moved to the first 3 columns of the table.
It's complicated, thank you very much!
{kind=link}
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: How to represent the Y response of the decision tree as a variable?
Here is a simple script that will run the 3 Decision Trees once the data table is in the form of the first 3 columns being the Y responses, and the remaining columns being the X factors. I do not follow your
"The X factor used each time starts with column 5 and ends with column 2.The second X factor to the second X factor.
How to code this decision tree code so that the same code can perform operations in different files.
In the annex, Boston Housing.jmp adds 2 columns to the Y response so that 3 columns of the Y response are available and moved to the first 3 columns of the table.".
If what I have provided is not what you are seeking, please provide more specifics
Names Default To Here( 1 );
dt = Current Data Table();
// Get all of the columm names
colNamesList = dt << get column names;
// Get the Y Factor columns
yFactorList = As List( colNamesList[1 :: 3] );
// Get the X Factor columns
xFactorList = As List( colNamesList[4 :: N Items( colNamesList )] );
// Run the Partitions
Partition(
Y( Eval( yFactorList ) ),
X( Eval( xFactorList ) ),
Split Best( 3 )
);- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: How to represent the Y response of the decision tree as a variable?
Upload a data table adjusted by Boston housing.jmp, and I won't upload the code.Thanks!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: How to represent the Y response of the decision tree as a variable?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: How to represent the Y response of the decision tree as a variable?
Here is a simple script that will run the 3 Decision Trees once the data table is in the form of the first 3 columns being the Y responses, and the remaining columns being the X factors. I do not follow your
"The X factor used each time starts with column 5 and ends with column 2.The second X factor to the second X factor.
How to code this decision tree code so that the same code can perform operations in different files.
In the annex, Boston Housing.jmp adds 2 columns to the Y response so that 3 columns of the Y response are available and moved to the first 3 columns of the table.".
If what I have provided is not what you are seeking, please provide more specifics
Names Default To Here( 1 );
dt = Current Data Table();
// Get all of the columm names
colNamesList = dt << get column names;
// Get the Y Factor columns
yFactorList = As List( colNamesList[1 :: 3] );
// Get the X Factor columns
xFactorList = As List( colNamesList[4 :: N Items( colNamesList )] );
// Run the Partitions
Partition(
Y( Eval( yFactorList ) ),
X( Eval( xFactorList ) ),
Split Best( 3 )
);- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: How to represent the Y response of the decision tree as a variable?
I made a mistake in the previous statement, which should be: X factor goes from column 5 to the penultimate column 2.
Recommended Articles
- © 2025 JMP Statistical Discovery LLC. All Rights Reserved.
- Terms of Use
- Privacy Statement
- Contact Us