Hello,
I have a time series (five time steps) of samples from a population of the same ~60 individuals, each sample being a haphazardly chosen (i.e. not completely random) subset of the 60. The sample sizes each time ranges from about 15 to up to 50, and the measurement I do for each individual in a sample is a continous variable that goes from 0 to 1.
Since the sample sizes are different each time, are NOT paired (the same individual may have been measured more than once, but that's not tracked), have unequal variances, and does not conform to a normal distribution, I opted to use the Kruskal-Wallis test in JMP version 9 as a non-parametric test for the existence of differences between samples. And there are differences (p < 0.01).
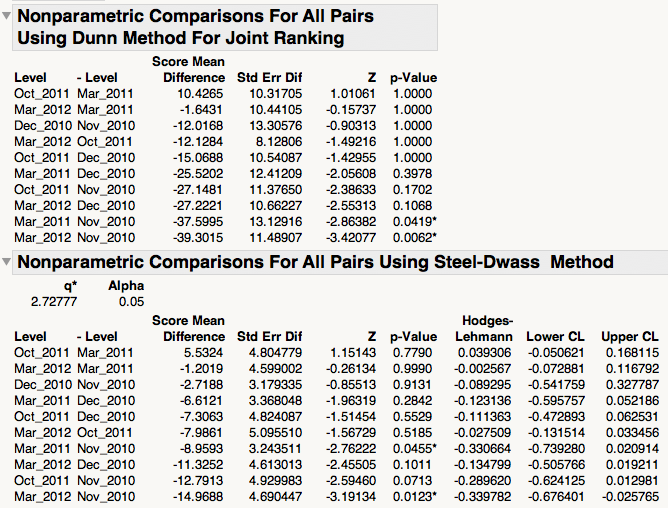
As far as I can tell, JMP provides me with two possible post-hoc tests to find where the differences are: "Steel-Dwass All Pairs", and "Dunn All Paris for Joint Ranks".
According to the JMP documentation, Steel-Dwass All Pairs "performs the Steel-Dwass test on each pair. This is the nonparametric version of the All Pairs, Tukey HSD", while Dunn All Pairs for Joint Ranks "performs a comparison of each pair, similar to the Steel-Dwass All Pairs option. The Dunn method is different in that it computes ranks on all the data, not just the pair being compared".
My questions are: (1) was I right in running the Kruskal-Wallis test to begin with? (2) What are the differences between the two post-hoc tests I am presented with, and how should I choose between them?
Thank you so much for your help! Please let me know if there is any other information I should provide.
P.S. I have attached the results from running both tests, do I inteprete them correctly that the cases with p < 0.05 are the statistically significant differences? (my alpha = 0.05)
P.S.S. The question is also here.

{kind=link}