- Instantly extract effect sizes, F-ratios, and FDR-adjusted p-values from your models with the Calculate Effects Sizes extension, available now in the JMP Marketplace!
- New to JMP? Join us Sept. 23-24 for the Early User Edition of Discovery Summit, tailor-made for new users. Register now for free!
- Your voice matters! Tell us how you prefer to receive JMP updates, so we can tailor our communication to your needs. Take short survey.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Discussions
Solve problems, and share tips and tricks with other JMP users.- JMP User Community
- :
- Discussions
- :
- Re: How to add multiple measurements of a sample into my experimental design?

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
How to add multiple measurements of a sample into my experimental design?
Hello JMP users,
I am new to JMP and am currently writing my master's thesis. For this I am planning a Central Composite Design - Rotatable with 6 central points. I have 5 factors and 8 responses. The aim is to develop an optimal formulation for a product.
For each response I will measure each sample/pattern in five replications. Later, when I want to enter the results for the responses, I have the following questions:
1. For each pattern there is only one row for entering the measured results for each response. Do I have to enter the mean value of the samples I measured five times or is it possible to enter all five measured results of each sample individually so that the design takes this into account? Is it possible to add manually 4 more rows for each pattern into the design to enter the five measurements (that would be a total of 160 measurement results)?
2) What does "replicate" mean when creating the Central Composite Design? Does this mean multiple measurements of a sample or is each sample produced separately?
I have attached a section of my design as a picture.
Thank you in advance for help.
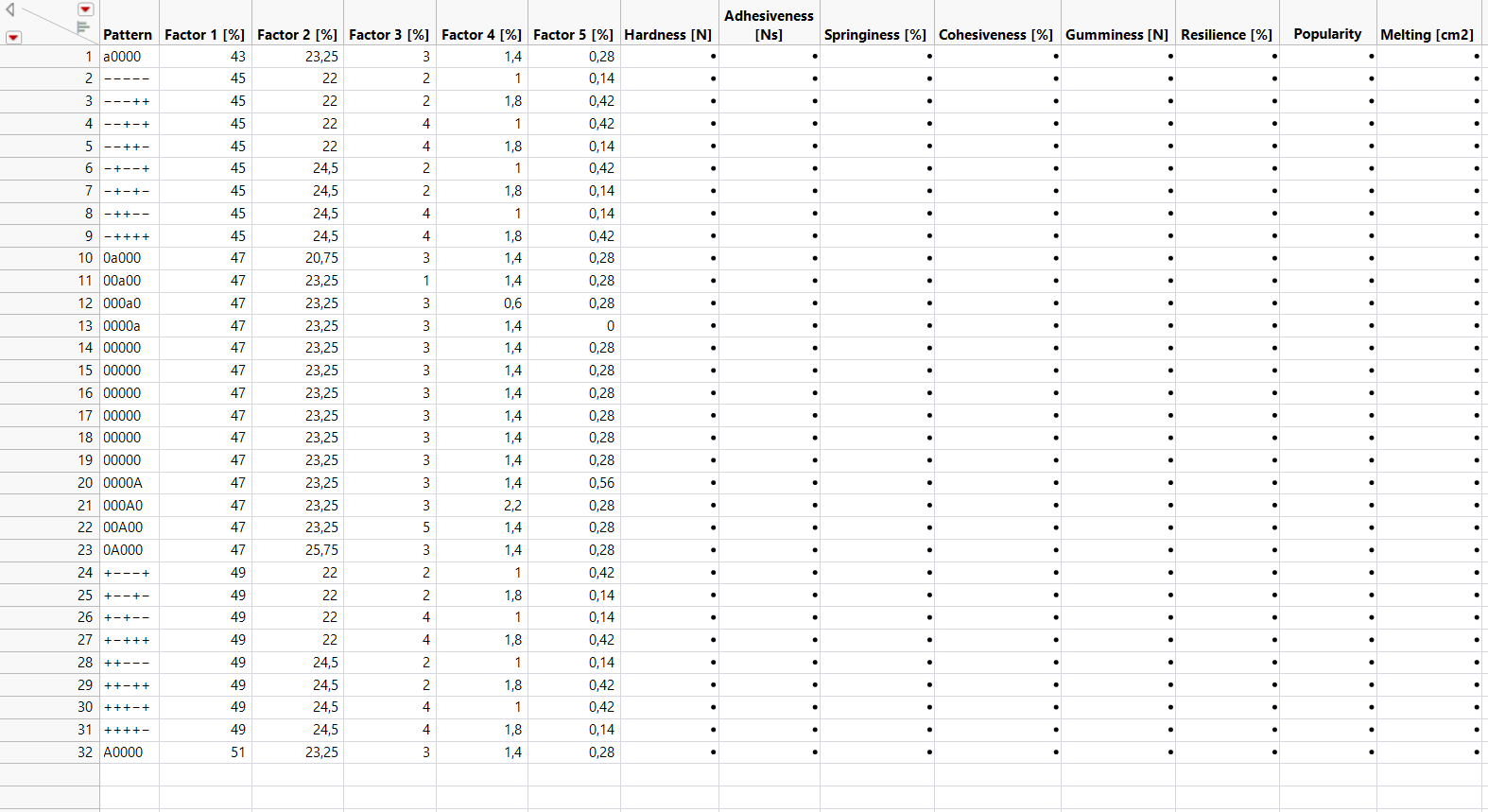{kind=link}
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: How to add multiple measurements of a sample into my experimental design?
Hello @Tamara_We,
Welcome in the Community !
Here are some first answers to your questions :
- Difference between repetition and replication : Repetition is about making multiple response(s) measurements on the same experimental run (same sample), while replication is making multiple experimental runs (multiple samples) for each treatment combination.
- Replications are used in order to estimate more precisely pure error and parameters estimates more accurately.
- Repetitions may be used to lower the measurement variance and increase measurement precision/accuracy.
- Replicates vs. Replicate runs : You may face different words depending on the DoE platform used :
- For Classical Design (like Central Composite Design), you can specify "replicates", which is the number of times all experiments will be realized independently in the DoE,
- For Custom (optimal) Design, you can specify "replicate runs", which is the independent repetition of one experiment in the design.
- Use Case : In your use case, if you can measure several times (5 times) each experimental run from the design, this is a case of repetition, not replication. So it is not advised to add new rows in the datatable to bring these measurement values, as the rows/experiments added are not independent from each others (the measurements are done on one sample only, not several ones that are independent). What you can do is enter the mean of these 5 repeated measurements for each response, as well as an information on the variance of the measurement (variance, standard deviation, etc...) and use both responses' informations (mean and stddev for example) in the modeling. Using these informations can help you find optimal settings for your factors, as well as increasing as much as possible the robustness of the settings (by lowering the "variance response" for each response).
If you have lower and/or upper specifications limit for your responses, the Design Space Profiler (jmp.com) may also be a great tool to explore the experimental area in which you have optimal and robust responses.
I hope these answers will help you,
"It is not unusual for a well-designed experiment to analyze itself" (Box, Hunter and Hunter)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: How to add multiple measurements of a sample into my experimental design?
Hello @Tamara_We,
Welcome in the Community !
Here are some first answers to your questions :
- Difference between repetition and replication : Repetition is about making multiple response(s) measurements on the same experimental run (same sample), while replication is making multiple experimental runs (multiple samples) for each treatment combination.
- Replications are used in order to estimate more precisely pure error and parameters estimates more accurately.
- Repetitions may be used to lower the measurement variance and increase measurement precision/accuracy.
- Replicates vs. Replicate runs : You may face different words depending on the DoE platform used :
- For Classical Design (like Central Composite Design), you can specify "replicates", which is the number of times all experiments will be realized independently in the DoE,
- For Custom (optimal) Design, you can specify "replicate runs", which is the independent repetition of one experiment in the design.
- Use Case : In your use case, if you can measure several times (5 times) each experimental run from the design, this is a case of repetition, not replication. So it is not advised to add new rows in the datatable to bring these measurement values, as the rows/experiments added are not independent from each others (the measurements are done on one sample only, not several ones that are independent). What you can do is enter the mean of these 5 repeated measurements for each response, as well as an information on the variance of the measurement (variance, standard deviation, etc...) and use both responses' informations (mean and stddev for example) in the modeling. Using these informations can help you find optimal settings for your factors, as well as increasing as much as possible the robustness of the settings (by lowering the "variance response" for each response).
If you have lower and/or upper specifications limit for your responses, the Design Space Profiler (jmp.com) may also be a great tool to explore the experimental area in which you have optimal and robust responses.
I hope these answers will help you,
"It is not unusual for a well-designed experiment to analyze itself" (Box, Hunter and Hunter)

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: How to add multiple measurements of a sample into my experimental design?
In addition to Victor's explanations, I have the following questions/thoughts/clarifications (and perhaps some semantics):
1. You suggest you want to "develop an optimal formulation". Are you sure you don't want a mixture design? Will there be any constraints on the factors in the experiment (for example, if you change the level of one factor, does it impact levels for the other factor(s)?)? If so, you should read here:
https://www.jmp.com/support/help/en/17.0/?os=mac&source=application#page/jmp/mixture-designs.shtml
2. Victor is correct, in your situation the 5 "measures" are not independent of the treatments, so they are repeats. You have 1 experimental unit which is measured multiple times. I use the term experimental unit to describe the independent output of a treatment combination (or perhaps what the treatment is applied to). Typically, we use the word treatment or Treatment combination to describe the "patterns" in the experiment (terminology dates back to original work of Sir Ronald Fisher). Although I recognize there is a column called "pattern" in the JMP table. This terminology seeks to prevent misunderstanding of how the data should be used. How those measures are taken can affect the analysis. If those repeat measures are of the identical sample, the variation in those measurements would be indicative of measurement error. It would likely be best to look at that variation to assess measurement errors and if appropriate summarize those measures to reduce the measurement errors. If they are measures of different sample of the same experimental unit, that would be indicative of within unit variation (e.g., if the experimental unit is a batch, then the measures would be indicative of within batch and measurement error). What I would suggest is to add these data as separate columns (e.g., Y1-Y5). Adding rows would add degrees of freedom to the experiment and since these are not independent events, there should not be additional degrees of freedom as a result of repeated measures. Once the data is entered, you can stack those columns (Tables>Stack) to assess the variation and determine the appropriate summary statistics (Tables>Summary) (e.g., mean and/or variance) to be used for analysis of your experiment.
3. As Victor explains, replicates are used, hopefully, to quantify/estimate experimental error over the design space. This is usually the basis for statistical tests. (ANOVA). There are multiple ways to run replicates, but I'll leave that for another discussion (e.g., blocks).
Recommended Articles
- © 2026 JMP Statistical Discovery LLC. All Rights Reserved.
- Terms of Use
- Privacy Statement
- Contact Us