- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Discussions
Solve problems, and share tips and tricks with other JMP users.- JMP User Community
- :
- Discussions
- :
- GLM Interpretation

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
GLM Interpretation
I did a survey-experiment for my master's thesis. My supervisor has recommended that I use GLM due to design having mixed components (the treatments are fixed but the participants and the pictures included on the survey are random) but I am finding it hard to interpret the results.
On the survey the participants randomly got into one out of 3 conditions. Then they saw 10 pictures and had to answer 6 questions for each picture. Depending on the treatment the picture either included a sign type 1, type 2 or no sign. They answered the questions on a five-point likert scale.
For this model I used the average for the 10 pictures that each participant answered for a specific question, this was recommended to me but also this model shows a lower AIC than the others I have tried.
The variables used are:
NN vs N - NN is represented by 0 and it means that the picture picture or treatment did not include a sign. N represents it had a sign.
Treatment - 0 represents it did not include a sign. 1 that it included a sign type 1 and 2 that it included a sign type 2.
I would really appreciate it if somebody could help me understand the results.
{kind=link}
{kind=link}

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: GLM Interpretation
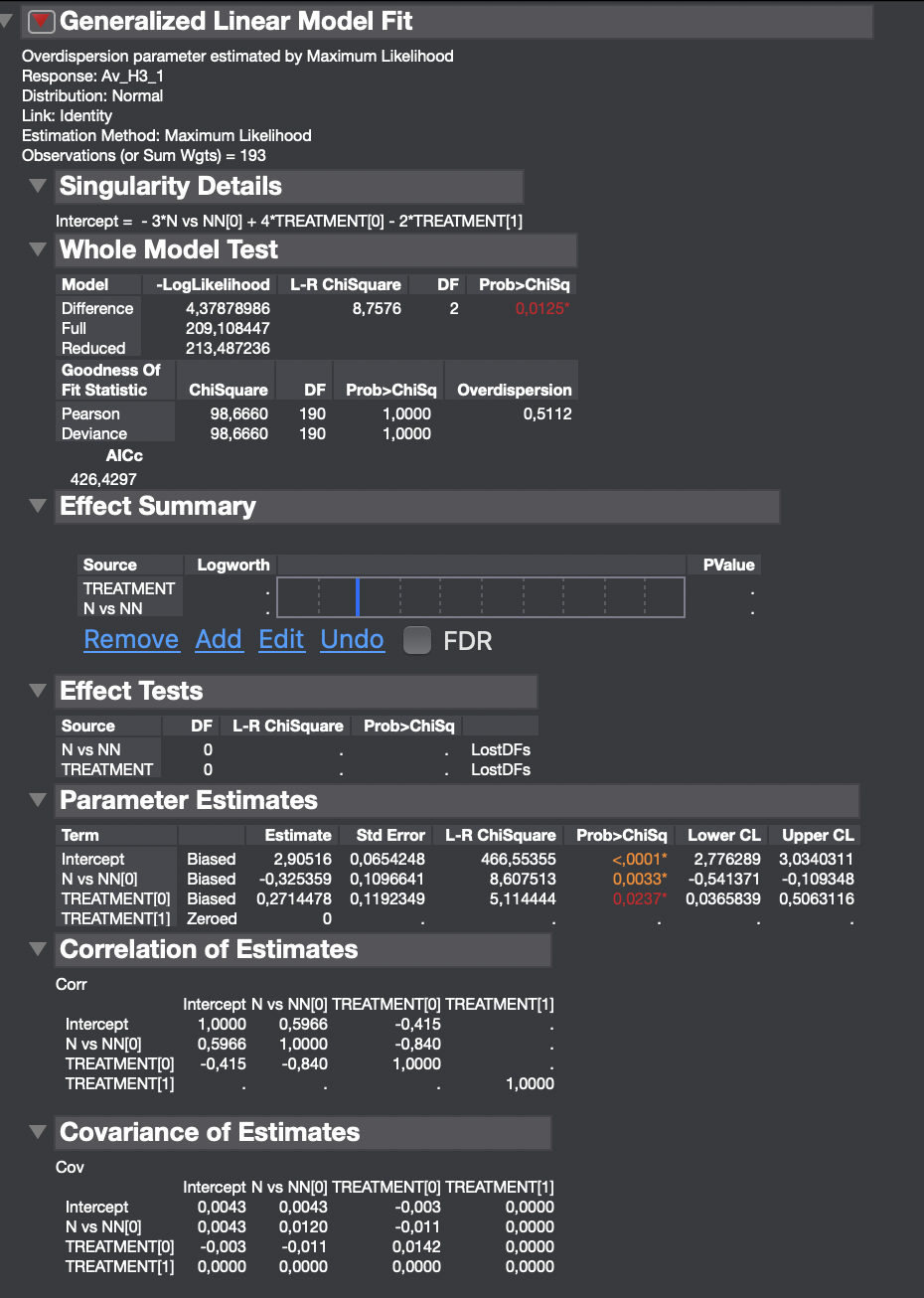
Hello and welcome. So I understand the data: If Treatment =0, then NN vs N = 0. and, if Treatment = 1 or 2, then NN vs N = N. is this correct? If so, it is no wonder you have singularity issues, lost dfs, and zeroed parameter estimates. This can happen when your factors are correlated with each other. If I have this correct, then "NN vs N" is a function of "Treatment"...and that is why these problems have come up.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: GLM Interpretation
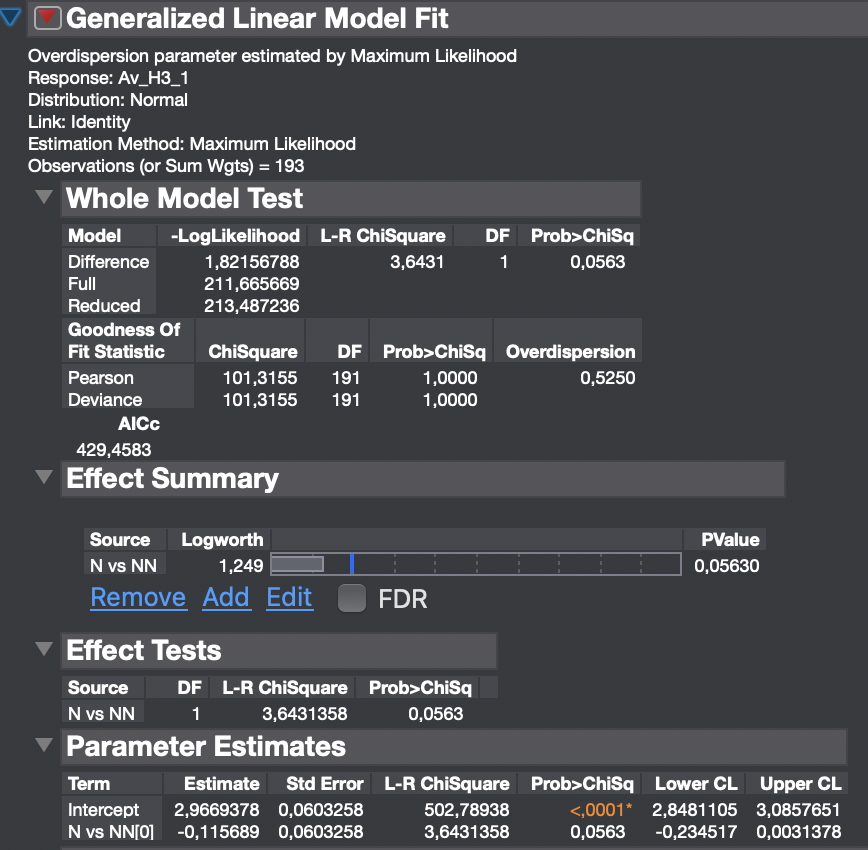
Hi! Yes, the factors are correlated with each other. I have used the same model but done only one factor at a time, if that would solve the issue you mentioned. Still I do not really understand the output, do you think you could help me with that? Maybe telling what you see in the data?
I guess I should use the model by treatment since it has a lower AIC? even though what I am mostly interested is in testing N vs NN the different types of signs are additional information for my research but not the main point.
Thanks in advance
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: GLM Interpretation
@PoissonOpossum3 My first thought: If you have a GLM with distribution=normal and link=identity, then it'd be simpler and perhaps more informative to use Standard Least Squares in the Fit Model platform since with those GLM options, the model is the same as in the Standard Least Squares option (and I'd use emphasis = effect screening). And since the Least Squares results will have more options to assess/interpret your results, I'd start there (using one factor or the other).

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: GLM Interpretation
Using one factor or predictor at a time avoids the singularity in the analysis. Still, the issue remains: you cannot attribute any effect exclusively to either one of these factors based on this data. The factors are confounded. We sometimes say that one factor is an alias of the other. We require data in which they are not correlated to uniquely assign an effect to each. You should consider the model and analysis when designing the study. You should use an established method to design the experiment. The established methods require you to specify the model you intend to analyze.
On the other hand, Treatment might be the only real factor, and the analysis using this factor solely might be valid.
GLM is primarily for non-normally distributed responses. You mention random effects but you did not include them in the model. That omission might be valid because they represent the residual error. If so, you do not need a 'mixed effects model' or a 'generalized linear mixed model.'
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: GLM Interpretation
Thanks Mark, I will look into working with another model. Nevertheless, in order to compare the results I got from the GLM could you help me with the following question?
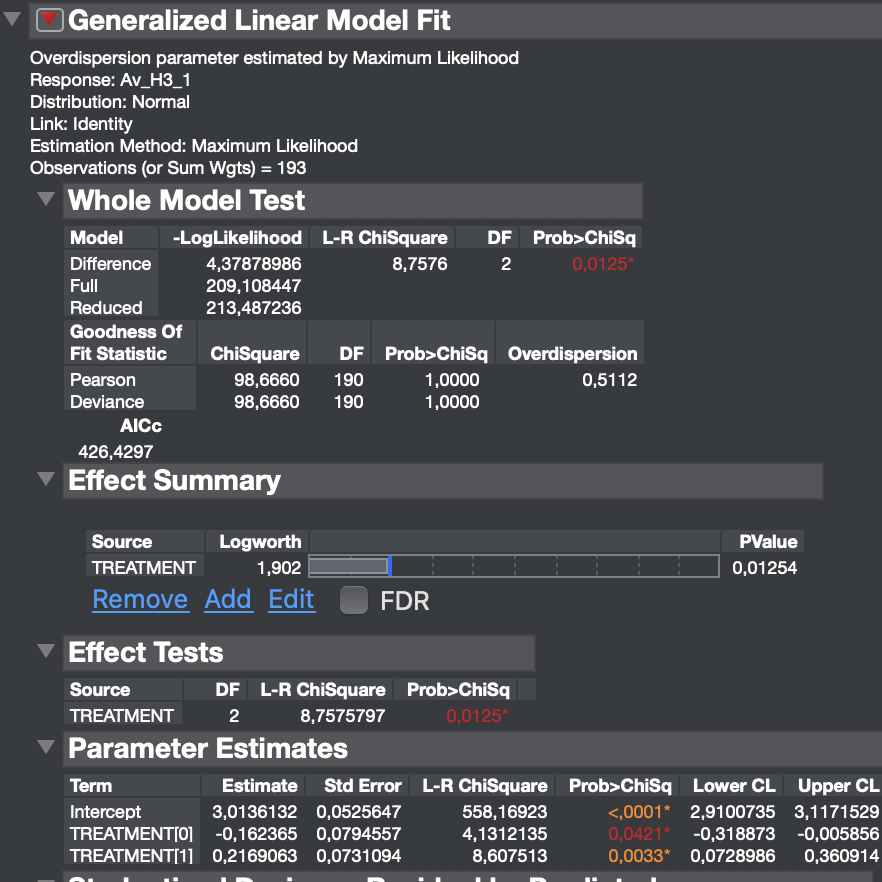
On the parameters estimates it shows the intercept and then Treatment 1 and treatment 0, but the variable treatment has 3 levels (0, 1 and 2). Would this mean that JMP categorised Treatment 2 as the Intercept? (this can be seen on one of the latest screenshots I provided).
Thanks in advance :)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: GLM Interpretation
No, JMP parameterizes the terms using Effects Coding. Essentially, the parameter estimates sum to zero. So if the estimate for Treatment 1 is 5 and Treatment 0 is 10, the estimate for Treatment 2 = -15. This coding ensures that the intercept is interpreted as the mean response at the center of the predictor space.
Recommended Articles
- © 2026 JMP Statistical Discovery LLC. All Rights Reserved.
- Terms of Use
- Privacy Statement
- Contact Us