This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
(Korean)
많은 엔지니어들이 엑셀에 저장된 데이터로 통계 분석을 수행한다. 이런 분석을 어쩌다 한 번 수행하는 것이 아니고 주 1회, 또는 매일 1회씩 반복되는 경우도 있다.
만약 주 1회 동일한 데이터 분석에 평균 60분씩 소요한다면, 이는 연간 2,400분, 40시간, 5일의 근무시간에 해당한다. = { 60분/1회 * 4주/월 * 10개월/년 }
만약 당신이 한 번 1~2시간을 투자해, 연간 40시간을 절약할 수 있다면 시도하겠는가?
여기서는 어느 회사의 엔지니어가 그의 담당 제품을 생산하는 두 개 협력 회사로부터 엑셀 파일로 데이터를 받은 후, 그 데이터를 이용해 동일한 통계 분석을 하는 과정의 자동화 방법을 보여준다. JMP 17의 Workflow Builder를 이용한다. 한 번 클릭해서 기존에 매번 1시간 정도 소요될 작업을 단 몇 초만에 끝낼 수 있다.
이런 방법을 응용해 보다 많은 엔지니어들이 업무 시간을 절약함으로써, 휴가나 휴식의 시간을 갖기를 바란다. 적어도 동일한 작업을 계속 반복함에 따른 지루함에서 벗어나 보다 재미 있는 일에 도전할 수 있지 않을까?
(English)
Many engineers perform statistical analysis on data stored in Excel. These analyzes are not performed once infrequently, but may be repeated once a week, or even once daily.
If you spend an average of 60 minutes analyzing the same data once a week, that equates to 2,400 minutes, 40 hours, and 5 days of work per year. = { 60 minutes/time * 4 weeks/month * 10 months/year }
If you could save 40 hours a year by investing an hour or two once, would you give it a try?
Here, an engineer of a company receives data in Excel files from two partner companies that produce his products, and shows an automated method of performing the same statistical analysis using the data. Use JMP 17's Workflow Builder. With a single click, tasks that would previously take an hour each time can be completed in seconds.
It is hoped that by applying this method, more engineers will have time for vacation or rest by saving work time. At least, wouldn't it be possible to get out of the boredom of repeating the same task over and over and try something more fun?
... View more
한국의 JMP사용자 그룹 회원 여러분, 새해 복 많이 받으세요!
JMP 한국 지사장 민철희입니다.
지난 5년간 한국의 JMP 사용자 수는 괄목할만큼 증가하였고 다양한 경로를 통해 서로 교류하고 있지만, 여기 "한국 JMP 사용자 모임" 포럼에서는 아직 활발한 토론이 이루어지지 않고 있습니다.
한 편, 아래 숫자들은 2022년 1월 14일 09:28 현재 (한국 시간) 각각 JMP Community 전체의 가입 회원 수, 토론 수, 파일 교환 수입니다.
35,778
399,548
1,849
여러분 JMP 사용자 간의 더 활발한 토론, 질의 응답, 정보 공유를 더 잘 돕고 싶습니다.
그렇게 하는 데 있어, 이 포럼을 더 잘 활용하기 위한 방법에 대한 여러분의 아이디어와 의견이 궁금합니다.
여러분의 의견을 이 포럼에 답변으로 남겨 주시기 바랍니다.
또는 저에게 직접 메일(chulhee.min@jmp.com)로 연락 주셔도 좋습니다.
감사합니다!
민철희
... View more
JMP를 처음 접하는 사용자를 대상으로 한 입문서가 나왔습니다. 1부에서는 JMP 소개와 데이터 전처리를, 2부에서는 그래프 분석과 통계 기초를 다룹니다. JMP 학습서를 기다리시던 분들께 많은 도움 되시기를 바랍니다. 판매 서점은 점차 확대 예정이며, 전자책 출간도 준비 중입니다.
구매링크: http://bit.ly/3qbxpYz
... View more
뉴스레터 구독자에게 발송되는 Monthly User Guide입니다. 관련 문의는 ikju.shin@jmp.com으로 부탁드립니다.
2017년 8월에 시작한 Monthly User Guide가 이제 3년 3개월이 되었고, 39호를 발행하게 되었습니다. 2020년 11월(40호)부터는 새로운 집필진과 형식으로 찾아 뵙게 될 것 같습니다. 이번 39호의 주제는 이미지 데이터를 JMP로 불러오는 방법에 대해 Local PC Data인 경우와 Internet(Web) Data인 경우로 구분하여 살펴 보겠습니다.
1. Local Data 일 경우
1) 여러분 PC의 특정한 폴더에 아래와 같은 이미지 파일이 있다고 가정하겠습니다.
2) Image 파일을 불러오기 위해서는 JMP에서 File / Import Multiple Files를 선택합니다. 여러 가지 Option이 있습니다만, 파일 이름이 포함된 Column 만을 생성하기 위하여 'Add file name columns' 만 선택하고, Import 버튼을 클릭해 보겠습니다.
3) 그러면 아래와 같이 이미지가 포함된 JMP Data Table이 만들어집니다.
2. Internet(Web) Data일 경우
1) 예를 들어 설명하겠습니다. 아래 위키피디어 링크에 들어가 보면 아시아 국가들의 휘장(emblem, armorial)에 대한 소개 내용이 있는데, 이 휘장 이미지를 JMP로 불러와 보겠습니다.
https://en.wikipedia.org/wiki/Armorial_of_Asia
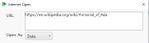
2) File / internet open / web page에 들어가서 해당 URL를 복사해서 붙여넣기합니다.
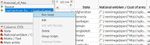
3) Import할 Table을 선택한 다음(여기서는 첫 번째 Table만) OK를 클릭합니다.
4) 왼쪽 상단 Table Panel에서 'Load pictures for...'를 실행합니다. (우측 마우스 클릭, Run Script 실행)
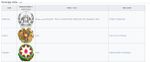
5) 그러면 아래와 같이 JMP Data Table에 해당 Web Page의 Image가 Import되어 표시됩니다.
6) 좀 더 상세한 사항은 JMP Community 내 아래 동영상(3분) 참조하세요.
https://community.jmp.com/t5/video/gallerypage/video-id/6169990206001
7) URL 주소에 한글이 포함된 경우에는 인코딩(Encoding)*등의 문제로 해당 URL이 File / internet open / web page 에서 열 수 없는 형태로 % 등이 포함된 문자로 변형될 수 있습니다. 이럴 때는 URL 주소 중 http:// (또는 https://)를 제외하고 복사, 붙여넣기한 다음 에 http:// (또는 https://) 부분을 직접 입력하면 됩니다.
아래 링크의 내용은 우리 나라 국보 목록 중 일부인 데, 이에 대해 설명드린대로 작업을 시행하면 아래와 같이 이미지 Data가 JMP Data Table에 표시됩니다.
(https://ko.wikipedia.org/wiki/대한민국의_국보_(제1호_~_제100호)#제1호_~_제100호)
* 인코딩에 대한 설명은 아래 링크 등 인터넷에서 검색해 보시면 좋겠습니다. https://opentutorials.org/course/50/191
... View more
뉴스레터 구독자에게 발송되는 Monthly User Guide입니다. 관련 문의는 ikju.shin@jmp.com으로 부탁드립니다.
많이 알려진 대로, ANOVA(분산 분석, Analysis of Variance)는 연속형 반응치(Continuous Response)에 대한 범주형 인자(categorical factor)의 유의성, 영향도를 평가하는 가장 대표적인 방법입니다. ANOVA 의 종류에는 일원 분산 분석(OneWay ANOVA), 이원 분산 분석(Two-Way ANOVA) 등이 있는 데, 이 때 일원 또는 이원의 의미는 요인의 개수를 말합니다. 예를 들어 재료 A, B 의 따른 수율의 차이를 검정한다면 요인은 재료 하나 이므로 일원 분산 분석이고, 반면 재료 A, B 및 가열 온도 100 도, 110 도에서의 수율의 차이를 검정하고자 한다면 요인은 재료 및 온도 두 가지이므로 이런 경우를 이원 분산 분석이라고 합니다. 재료 A, B 또는 온도 10 도, 110 도처럼 각 요인의 수준(Level)이 두 가지일 경우가 ANOVA 의 가장 기본적인 형태라 볼 수 있는 데, 여기서는 요인의 수준(Level)이 세 가지 이상인 경우인 다중 비교(Multiple Comparison)에 대해 살펴보겠습니다.
일반적으로 ANOVA(Analysis of Variance, 분산 분석)를 사용하여 평균치 차이 검정을 할 경우 가설은 다음과 같습니다.
1) 귀무 가설(Ho) : 모든 그룹의 평균은 같다. 2) 대립 가설(H1) : 모든 그룹의 평균이 같은 것은 아니다.
핵심은 적어도 한 그룹의 평균이 다른 그룹의 평균과 다르면 귀무 가설을 기각하는 데에 있습니다. 즉 귀무 가설을 기각한다고 해서 모든 그룹의 평균치 차이가 나는 것이 아니라는 점입니다. 이와 같이 다중 비교(Multiple Comparison)의 경우 어떤 문제가 생길 수 있는 알아보겠습니다.
예를 들어 A, B, C, D, E 다섯 Group 을 가진 X 인자를 가지고 ANOVA 방법을 활용하여 두 Group 간 평균치 차이 검정을 한다고 가정하면 모두 10 가지의 비교가 가능합니다. 이 때 유의 수준(α, 1 종 오류) 0.05 기준으로 Test 전체의 위험률은 0.401 이 됩니다. 왜냐하면 유의 수준(1 종 오류)이 0.05 일 때, 1 종 오류가 발생하지 않을 확률은 (1-0.05) = 0.95 가 되는 데, 10 가지의 비교에 대해 1 종 오류가 발생하지 않을 확률은 (0.95) 10 = 0.599 가 됩니다.
즉, 10 가지의 비교에서 적어도 하나의 비교에서 1 종 오류가 발생할 확률은 1 – 0.599 = 0.401 이 되어 유의하지 않는 데도, 유의한 차이가 있다고 해석할 가능성이 높아지게 되므로, 다중 비교의 경우에는 일반적인 ANOVA 의 경우와는 좀 다른 방법과 해석이 필요합니다.
JMP 내의 아래 Sample Data 를 가지고 살펴보겠습니다.
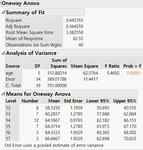
(Help / Sample Data Library / big class.jmp) 나이에 따라 키의 평균의 차이가 나는 지를 확인하기 위해 Analyze / Fit Y by X 에서 age 를 X 로, height 를 Y 로 선택하여 OK 클릭합니다. ▼Oneway ~ / Means / Anova 를 실행하면 결과는 아래와 같습니다.
위의 결과에서 P Value(0.0008) 만을 보고 나이에 따라 키 차이가 난다고 판단하면 안됩니다. 여기서는 여섯 가지 나이 Level(12 살 ~ 17 살) 중 적어도 하나 이상의 Level 간에 차이가 난다는 뜻이지 모든 나이 Level 간에 차이가 난다는 뜻이 아니므로 조심해야 합니다.
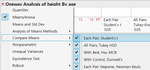
이와 같이 3 개 이상의 다중 비교일 경우에는 ▼Oneway ~ / Compare Means 아래에 있는 다섯 가지 방법 중 어느 하나를 사용해야 합니다. 여기서는 다섯 가지 방법 모두를 실행해 보겠습니다. (alt Key 를 누른 상태에서 Oneway 옆의 붉은 색 삼각형을 클릭하면 다섯 가지 방법 모두를 한꺼번에 실행할 수 있습니다.)
다섯 가지 방법에 대해 간략히 정리하면 아래와 같습니다.
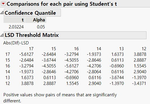
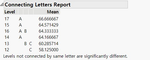
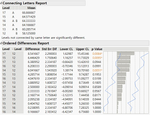
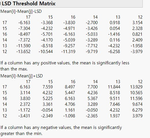
1. Each Pairs, Student's t 1) LSD Threshold Matrix 에서는 양수 값으로 포현된 Level 끼리는 유의한 차이가 있다는 뜻입니다. 2) Connecting Letters Report 에서는 같은 문자가 포함된 Level 은 유의한 차이가 없다는 뜻이 됩니다.
3) Ordered Difference Report 에서는 두 Level 간 검정 결과가 요약되어 있습니다.
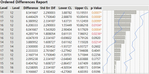
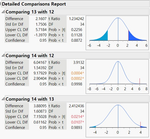
4) ▼Comparisons / Detailed Comparison Report 를 클릭하면 아래와 같이 두 Level 간 비교 결과(여기서는 비교 대상 Level 이 6 가지 이므로 모두 15 가지의 비교 결과)를 모두 확인할 수 있습니다.
2. All Pairs, Tukey HSD(Honestly Significant Difference) 위의 Student's t 검정 대비 결과가 상당히 보수적입니다. (통계적 유의성을 매우 엄격하게 해석하므로 이러한 해석이 필요한 상황에서 실무적으로 많이 활용됩니다.)
3. With Best, HSu MCB 이 방법은 최소 또는 최대 Sample Size 를 가진 Group 과 비교하므로 위의 두 방법과는 다소 다른 검정 결과를 보여줍니다.
4. With Control, Dunnett's 이 방법은 하나의 비교 그룹(여기서는 12 살을 비교 그룹으로 선택) 기준으로 검정하는 방법입니다.
5. Each Pair Stepwise Newman Keuls(SNK) 의 결과는 아래와 같습니다.
6. 종합적 해석 1) 실무적으로는 Student's T 방법과 Tukey-Kramer(Tukey HSD) 방법을 가장 많이 활용하는 것 같습니다. 2) 이 중에서도 Tukey-Kramer 방법이 보다 보수적이고 엄격합니다. 3) 상단에 있는 Circle 중의 어느 하나를 클릭하면 아래와 같이 유의차가 없는 Level 은 같은 붉은 색으로, 유의차가 있는 Level 은 검은 색으로 표시됩니다. 아래는 TurkeyKramer 방법의 13 살을 선택했을 때의 결과입니다. (마지막 방법인 Stepwise Newman Keuls(SNK)은 이러한 Circle 이 표시되지 않습니다.)
... View more