JMP is Pythonic! Enhanced Python Integration in JMP 18
JMP 18 has a new way to integrate with Python. The JMP 18 installation comes with an independent Python environment designed to be used with JMP. In addition, JMP now has a native Python editor and P...
 SamGardner
SamGardner
1452 views
|
3 replies
 KristenBradford
KristenBradford
 Paul_Nelson
Paul_Nelson
 Di_Michelson
Di_Michelson
 LauraCS
LauraCS
 chris_gotwalt1
chris_gotwalt1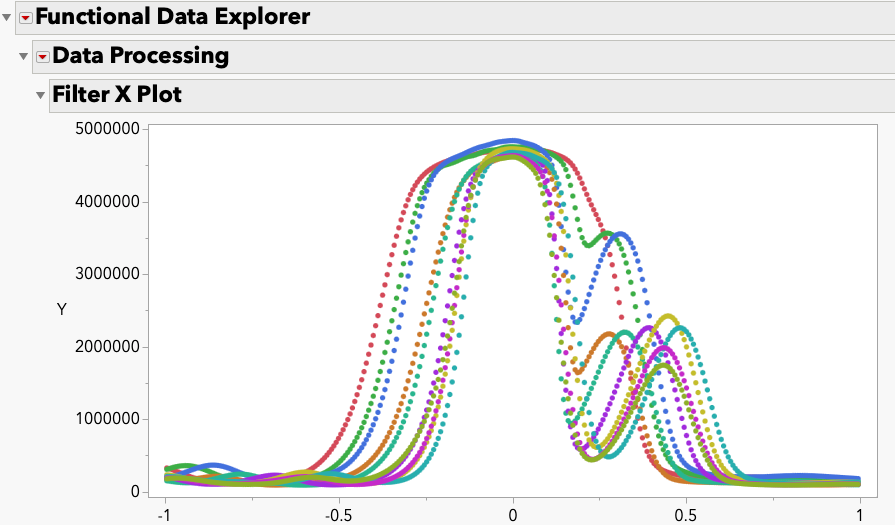
 gail_massari
gail_massari Valerie_Nedbal
Valerie_Nedbal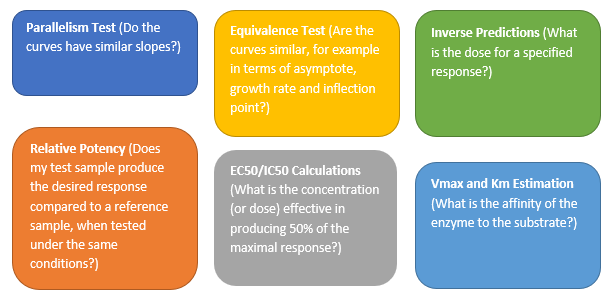
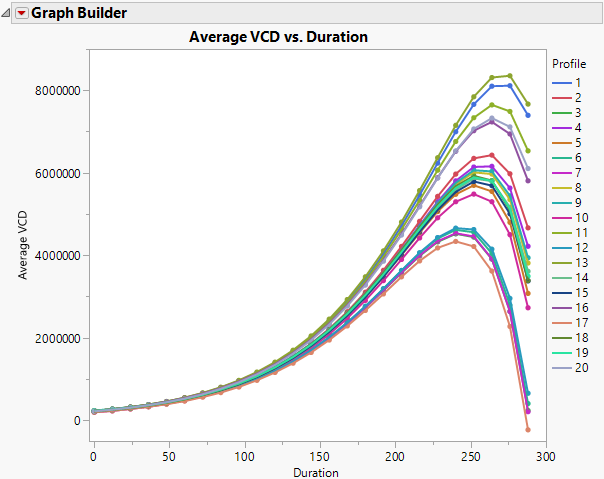
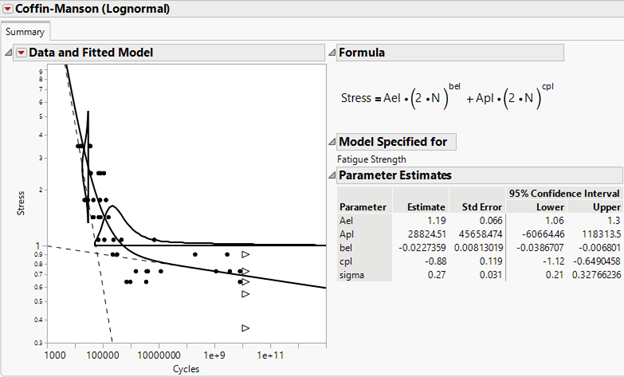
 julian
julian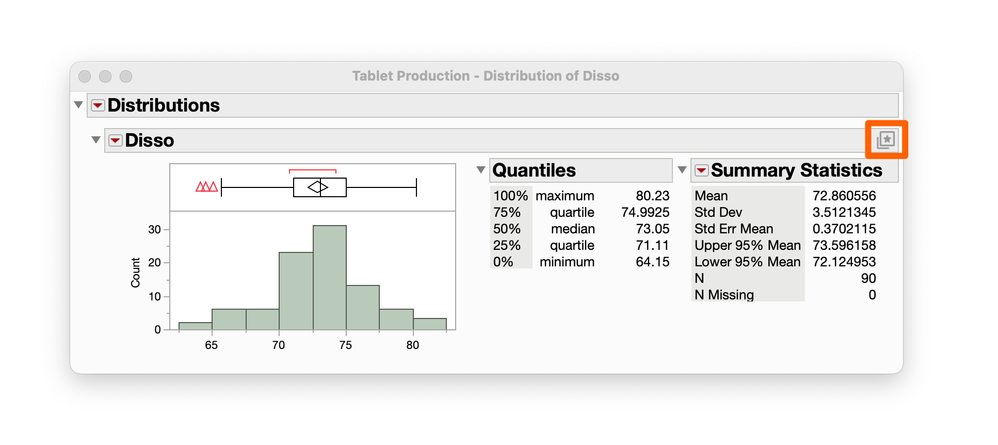
 mia_stephens
mia_stephens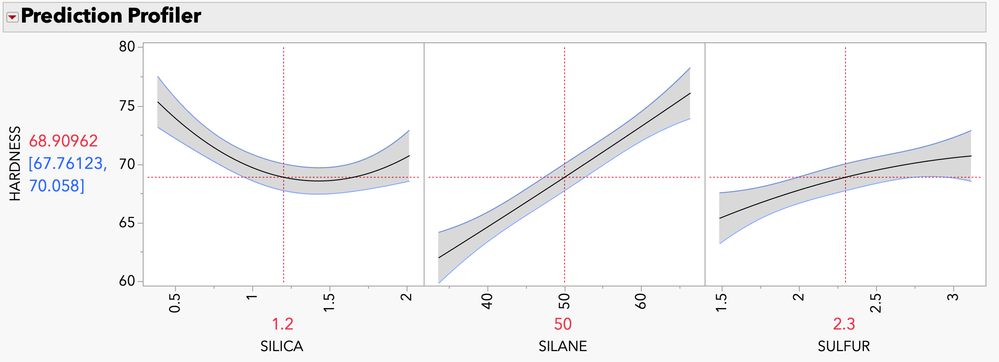
 dieter_pisot
dieter_pisot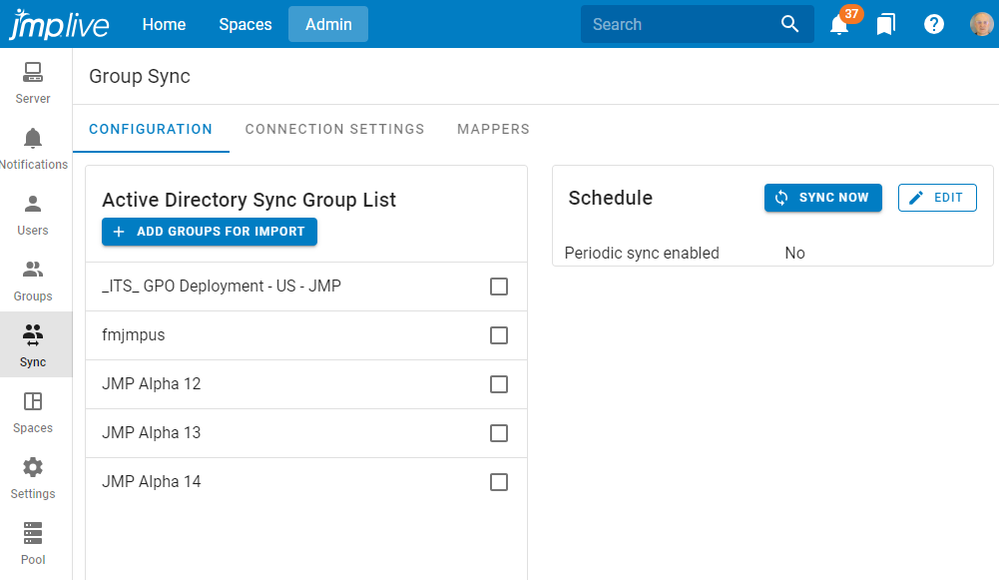
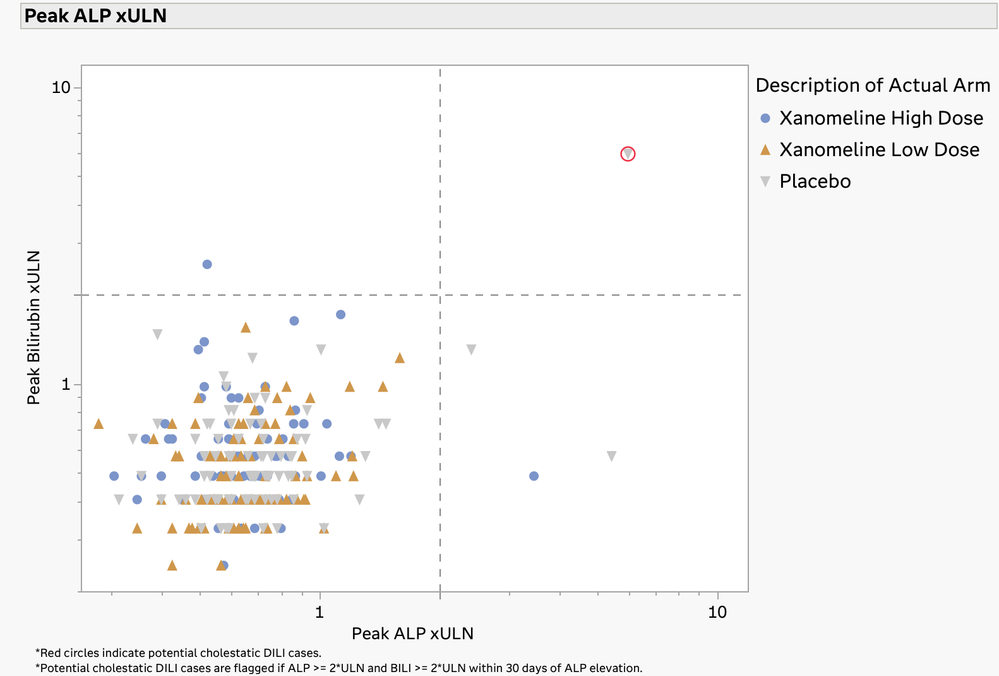
 Daniel_Valente
Daniel_Valente
 Wendy_Murphrey
Wendy_Murphrey
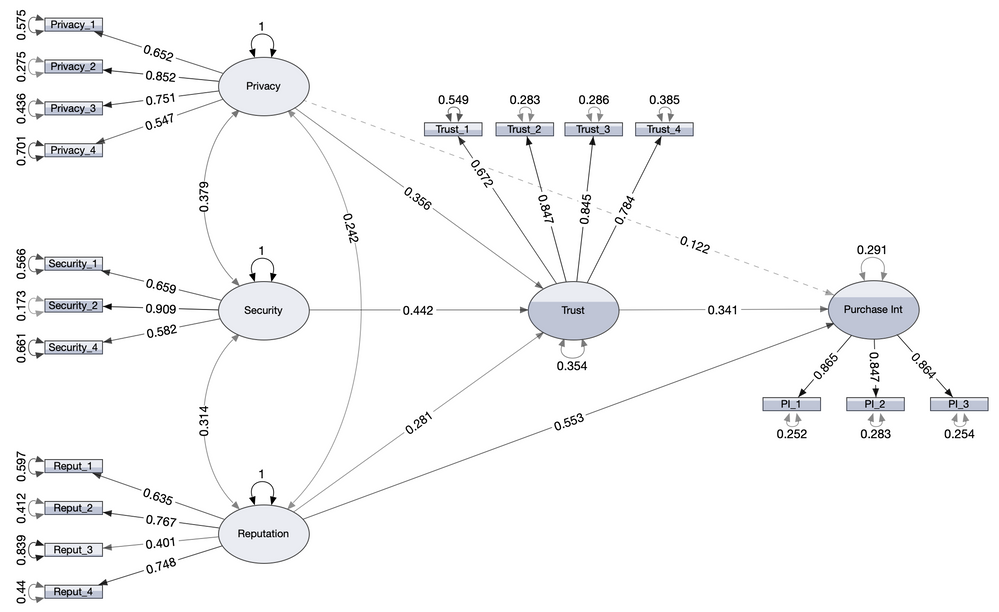
 sseligman
sseligman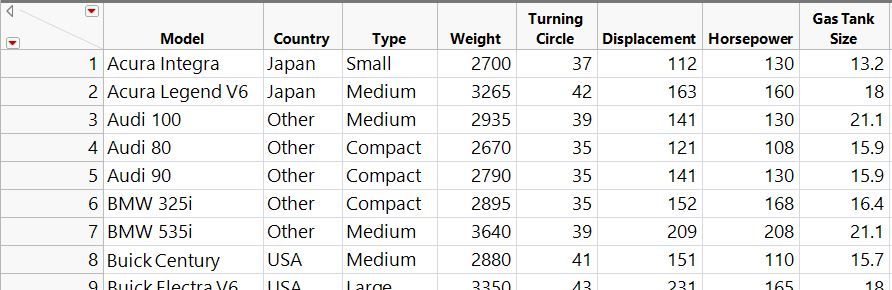
 MikeD_Anderson
MikeD_Anderson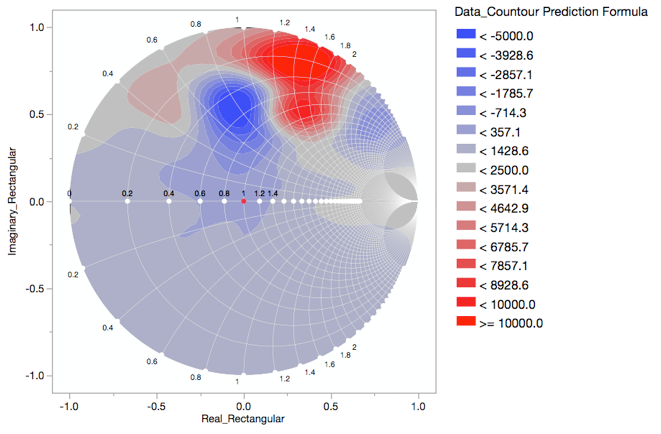
 jordanwalters
jordanwalters