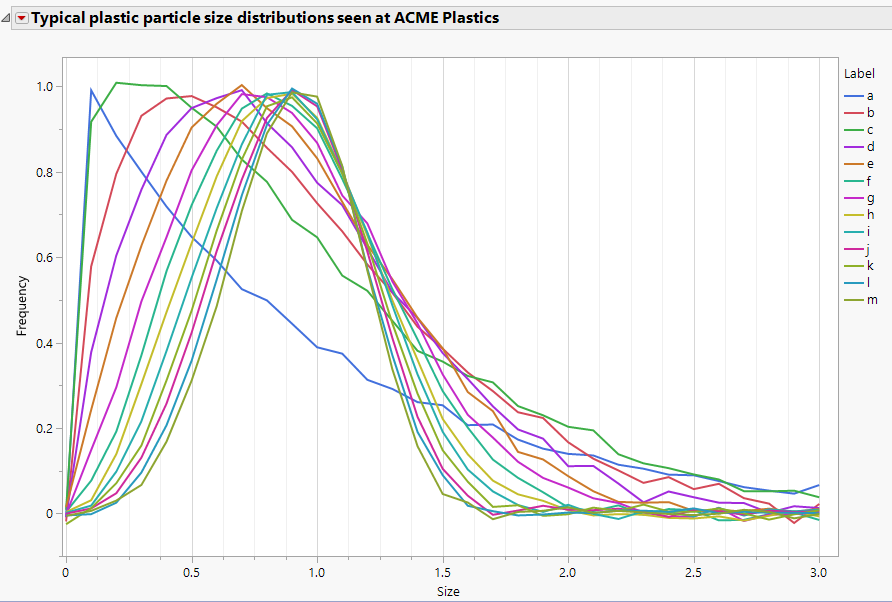
Using functional data as inputs instead of outputs
The Functional Data Explorer (FDE) in JMP Pro is generally used when the output of a process is functional/curved data. However, with a few tricks, functional data can also be used as an inp...
 Jed_Campbell
Jed_Campbell
1265 views
|
1 replies
 Phil_Kay
Phil_Kay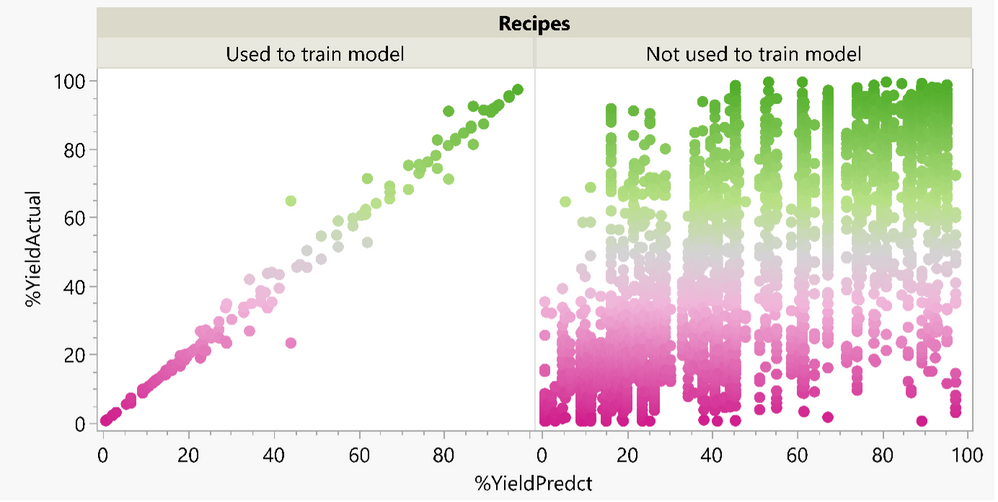
 Bill_Worley
Bill_Worley
 DaeYun_Kim
DaeYun_Kim
 SamGardner
SamGardner
 gail_massari
gail_massari
 Valerie_Nedbal
Valerie_Nedbal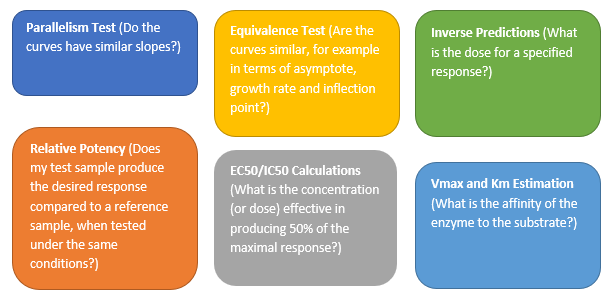
 Richard_Zink
Richard_Zink
 KristenBradford
KristenBradford
 Chris_Kirchberg
Chris_Kirchberg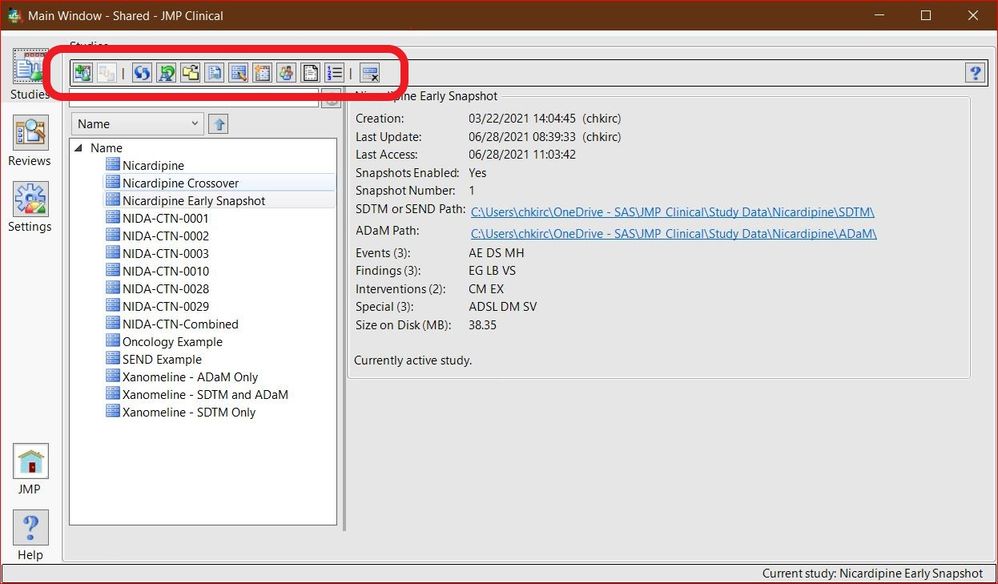
 cweisbart
cweisbart
 Paul_Nelson
Paul_Nelson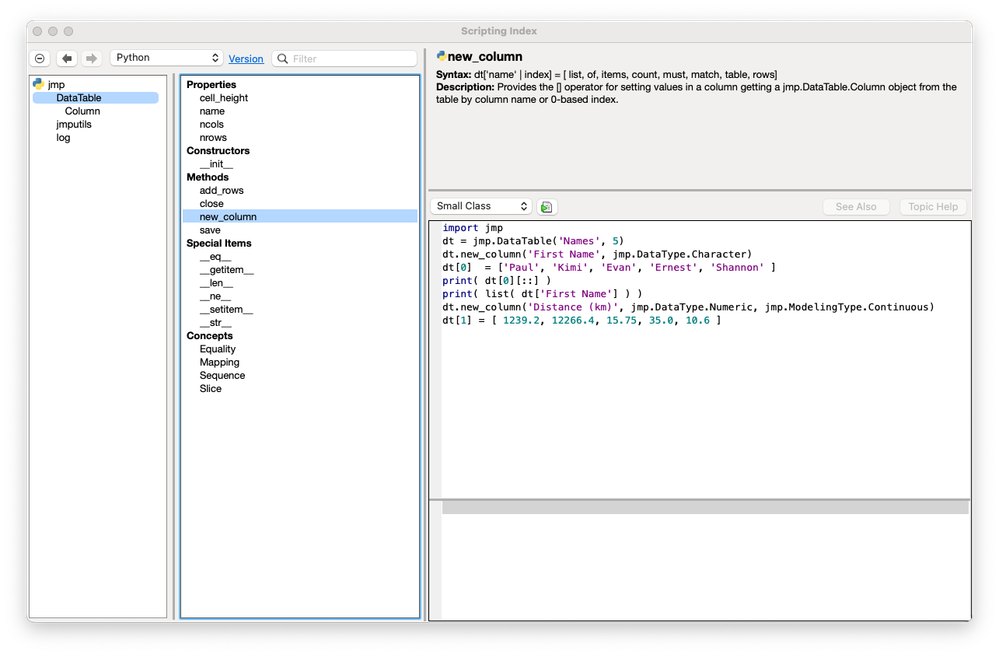
 Craige_Hales
Craige_Hales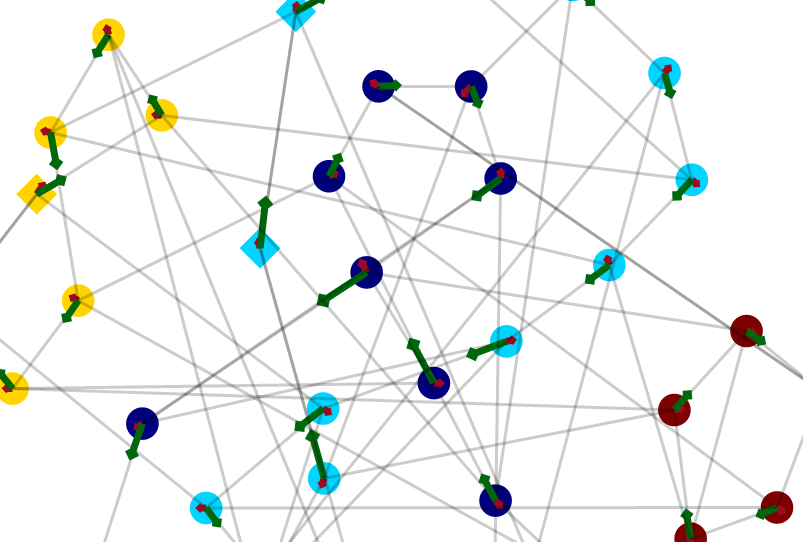
 anne_milley
anne_milley
 Di_Michelson
Di_Michelson
 JohnPonte
JohnPonte Masukawa_Nao
Masukawa_Nao

