This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
- JMP User Community
- :
- Discussions
- :
- SAS code in JMP?
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Topic Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page

Level III
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
SAS code in JMP?
Created:
Apr 4, 2019 07:39 PM
| Last Modified: Apr 5, 2019 09:25 AM
(17129 views)
I would like to know if there is a way I can run a SAS code (below) in JMP. Or how I can emulate the SAS code below in JMP.
proc mixed Class year week treatment rep; model stdmisummax=year|week|treatment/ddfm=kr residual; random rep(year) treatment*rep(year); repeated week/type=ar(1) subject=treatment*rep(year); run;
My factors are: Treatment, week (repeated measure), year, rep (replicate).
Thank you in advance.
PS: I've tried to run something similar in JMP using the repeated measures add in, but it won't work out, because I can't cross three factors to make the subject id.
I think my JMP version is not pro or it is some sort of pro version for the university.
I do not have SAS software.
19 REPLIES 19

Staff
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: SAS code in JMP?
Isadora,
I talked with Adam Morris about your question. Independently, I came up with the same results as him, even though I set the model up in a slightly different fashion. I liked his set up a bit better, so I'd use that one. Please let me know if you have additonal questions.
Don
Level III
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: SAS code in JMP?
@DonMcCormack Thank you very much for your response.
Would you mind sharing your solution as well? I'd like to compare them, because I'm interested in learning more about coding in JMP and other approaches for my data.
Thank you!
Isadora
Staff
Solution
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: SAS code in JMP?
My solution is below:
Fit Model(
Y( :Response ),
Effects(
:Treatment,
:Week,
:Treatment * :Week,
:Year,
:Treatment * :Year,
:Week * :Year,
:Treatment * :Week * :Year
),
Random Effects( :Rep[:Treatment, :Year] ),
NoBounds( 1 ),
Personality( "Mixed Model" ),
Subject( :Treatment, :Year, :Rep ),
Repeated Effects( :Week2 ),
Repeated Structure( "AR(1)" ),
Run( Variogram( AR1( 1 ) ) )
);There are only two differences. For the additional random effect, I nested Rep in Year. I used Treatment, Year, and Rep to implicitly define Subject. I find Adam's approach of explicitly defining Subject more intuitively appealing, though.
Level III
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: SAS code in JMP?
@DonMcCormack That is very helpful!
Thanks for sharing it with me, and for giving me your opinion on which solution is the best approach. I really appreciate that.
Isadora

Staff
Solution
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: SAS code in JMP?
Hi Isadora,
To share with others reading this thread, the proposed solution (from JMP Technical Support) is to create a new Subject column that is the concatenation of the 3 variables identifying the subjects (Treatment, Year, and Rep).
It is also necessary to create a continuous copy of the Week column for use as the Repeated variable.
JMP Pro cannot fit the exact same model as specified by the SAS Code (For AR(1) models, JMP nests the random effects in the subject variable). However, JMP can fit the model omitting the Rep(Year) term. The script below shows how one might set this up.
Thanks,
Adam
New Column("Subject", Character, Formula( :Treatment || ", " || Char( :Year ) || ", " || Char( :Rep ) ));
New Column("Week2", numeric, continuous, formula(:Week));
Fit Model(
Y( :response ),
Effects(
:Treatment,
:Week,
:Year,
:Treatment * :Week,
:Treatment * :Year,
:Week * :Year,
:Treatment * :Week * :Year
),
Random Effects( :Treatment*:Year*:Rep ),
Subject(:Subject),
Repeated Effects( :Week2 ),
Repeated Structure( "AR(1)" ),
Personality( "Mixed Model" )
);
Level III
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: SAS code in JMP?
@AdamMorris , you have been so helpful!
Thank you so much for sharing your knowledge and all this good information! I appreciate that.
Level III
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: SAS code in JMP?
Hi @AdamMorris and @DonMcCormack
I would like to know if you could help me to understand a little better why you used only one term as a random effect. Is it because I'm allowed to use only one random term under Random Effects when I use AR1?
Thank you,
Isadora

Staff
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: SAS code in JMP?
Created:
Jun 12, 2019 01:58 PM
| Last Modified: Jun 12, 2019 02:04 PM
(12772 views)
| Posted in reply to message from bordini 06-05-2019
You can add more than one random effect in the analysis of repeated measures. However you will get a note saying “The repeated subject column has been nested in all random effects.” See the screenshot below. I think that is why Adam suggested dropping Rep(Year) because it will nest in Treatment.

Have you tried including two random effects? What have you seen?
Level III
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: SAS code in JMP?
@jiancao Thank you for your explanation.
Every time I include more than one random effects, I get "0" for Estimate, Std Error (see scren shot) for one of the random effects. Why would that be? Is it because of the nesting?
Thank you for your help,
Isadora
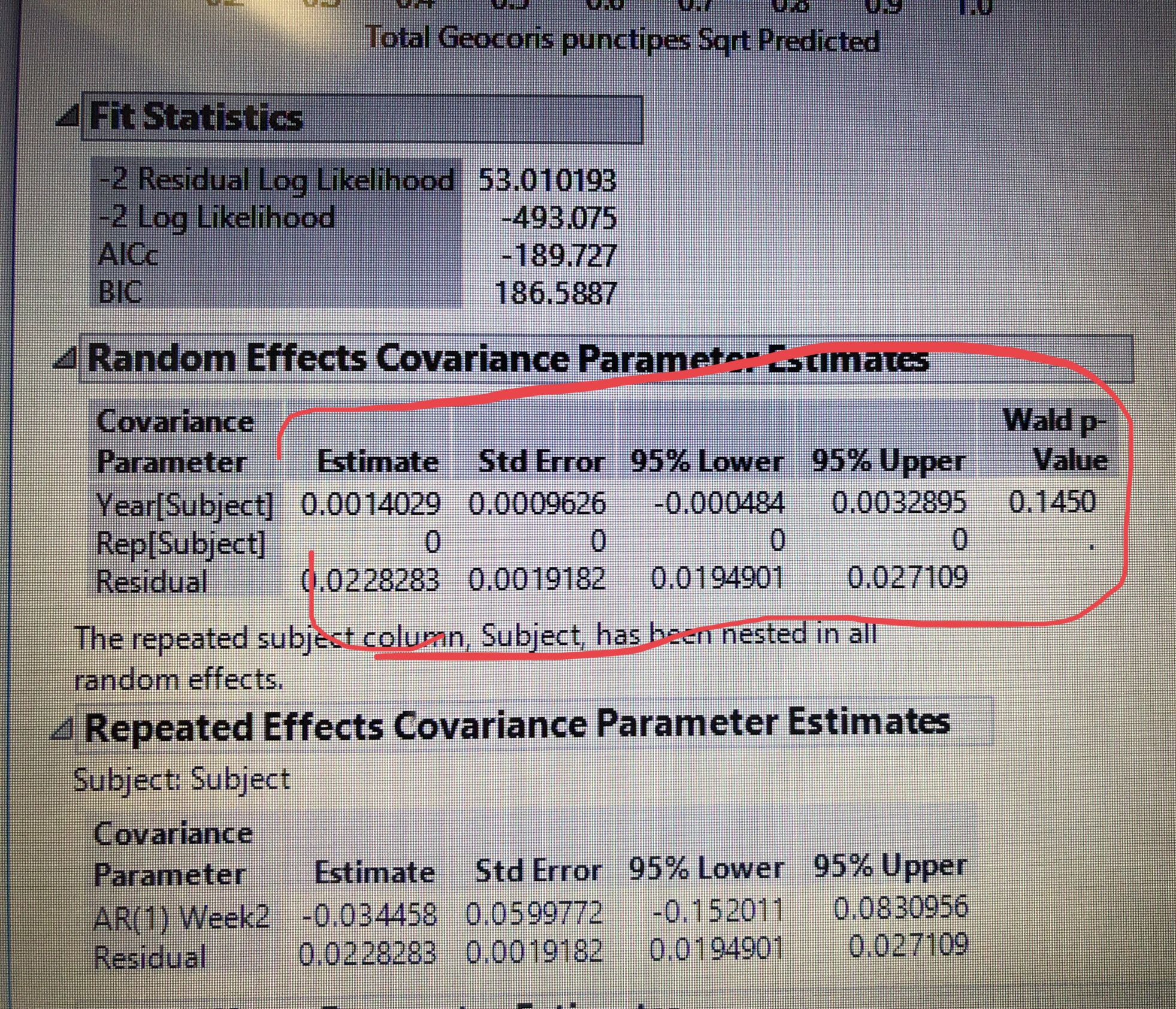{kind=link}
Staff
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Get Direct Link
- Report Inappropriate Content
Re: SAS code in JMP?
Yes, the random effect, Year(Subject), or whatever the first one, is the estimated between subject variation.
- « Previous
-
- 1
- 2
- Next »
- © 2024 JMP Statistical Discovery LLC. All Rights Reserved.
- Terms of Use
- Privacy Statement
- About JMP
- JMP Software
- JMP User Community
- Contact