
Welcome to our presentation on BPC- Stat:
Accelerating process characterization
with agile development of an automation tool set.
We'll show you our collaborative journey
of the Merck and Adsurgo development teams.
This was made possible by expert insights, management sponsorship,
and the many contributions from our process colleagues.
We can't overstate that enough.
I'm Seth Clark.
And I'm Melissa Matzke.
We're in the Research CMC Statistics group at Merck Research Laboratories.
And today, we'll take you through the problem we were challenged with,
the choice we had to make,
and the consequences of our choices.
And hopefully, that won't take too long and we'll quickly get to the best part,
a demonstration of the solution BPC- Stat.
So let's go ahead and get started.
The monoclonal antibody or mAb fed- batch process
consists of approximately 20 steps or 20 unit operations
across the upstream cell growth process and downstream purification process.
Each step can have up to 50 assays
for the evaluation of process and product quality.
Process characterization is the evaluation of process parameter effects on quality.
Our focus is the statistics workflow
associated with the mAb process characterization.
The statistics workflow includes study design using Sound DOE principles,
robust data management, statistical modeling and simulation.
This is all to support parameter classification
and the development of the control strategy.
The goal for the control strategy is to make statements
about how the quality is to be controlled,
to maintain safety and efficacy through consistent performance and capability.
To do this, we use the statistical models developed from the design studies.
Parameter classification is not a statistical analysis,
but it can be thought of as an exercise
of translating statistically meaningful to practically meaningful.
The practically meaningful effects
will be used to guide and inform SME (subject matter expert) decisions
to be made during the development of the control strategy.
And the translation from statistically to practically meaningful
is done through a simple calculation.
It's the change of the attribute mean, that is the parameter effect,
relative to the difference in the process mean
and the attribute acceptance criteria.
And depending on how much of the acceptance criteria range
gets used by the parameter effect
determines whether that process has a practically meaningful effect on quality.
So we have a defined problem -
the monoclonal antibody PC statistics workflow
and study design through control strategy.
How are we going to implement the statistics workflow in a way
that the process scientists and engineers will actively participate in
and own these components of PC, allowing us, the statisticians,
to provide oversight and guidance and allow us to extend our resources.
We had to choose a statistical software that included data management,
DOE, plotting, linear mix model capabilities.
Of course, it was extendable through automation,
intuitive, interactive and fit- for- purpose without a lot of customization.
And JMP was an obvious clear choice for that.
Why?
Because it has extensive customization and automation through JSL;
many of our engineers,
it's already their current go- to software for statistical analysis;
we have existing experience training in our organization;
and it's an industry- leading DOE with data interactivity.
The profiler and simulator in particular is very well suited for PC studies.
Also, the scripts that are produced are standard, reproducible, portable analysis.
We're using JMP to execute study design,
data management, statistical modeling and simulation
for one unit operation or one step that could have up to 50 responses.
The results of the analysis are moved to a study report
and used for parameter classification.
And we have to do all these 20 times.
And we have to do this for multiple projects.
So you can imagine it's a huge amount of work.
When we started doing this initially, we were finding that we were doing
a lot of editing of scripts before the automation.
We had to edit scripts to extend a copy existing analysis to other responses,
we had to edit scripts to add where conditions,
we had to edit scripts to extend the models to large scale.
We want to stop editing scripts.
Many of you may be familiar with the simulator set up can be very tedious.
You have to set the distribution for each individual process parameter.
You have to set the add random noise,
and you have to set the number of simulation runs and so on and so on.
There are many different steps,
including the possibility of editing scripts if we want to change
from an internal transform to the explicit transform.
The simulator is doing add random noise
on a log- normal type basis, for example, the log transform.
We want to stop that manual set up.
Our process colleagues and us we're spending enormous time
compiling information for the impact ratio calculations
that we use to make parameter classification decisions.
We are using profiles to verify those
and assembling all this information into a heat map
that then would be very tedious exercise
to decompose the information back to the original files.
We want to stop this manual parameter classification exercise.
Of course, last but not least, we have to report our results.
And the reporting involves copying,
or at least in the past involved copying and pasting from other projects.
And then, of course, you have copy and paste errors,
copy and pasting from JMP,
you might put the wrong profile or the wrong attribute and so on.
We want to stop all this copying and pasting.
We clearly had to deal with the consequences of our choice to use JMP.
The analysis process was labor- intensive, taking weeks, sometimes months
to finish an analysis for one unit operation.
It was prone to human error and usually required extensive rework.
It posed to be an exceptional challenge to train colleagues to own the analysis.
We developed a vision with acceleration in mind
to enable our colleagues
with a standardized yet flexible platform approach
to the process characterization and statistics workflow.
So we had along the way some guiding principles.
As we mentioned before, we wanted to stop editing JMP scripts
so any routine analysis, no editing is required.
And our JMP analysis, they need to stand on their own,
they need to be portable without having to install BPC-Stats
so that they live on only requiring the JMP version they were used.
We collected constant feedback, we constantly updated,
we constantly tracked issues relentlessly, updating sometimes daily,
meeting weekly with Adsurgo our development team.
Our interfaces, we made sure that they were understandable.
We use stoplight coloring such as green for good,
yellow for caution, and issues flagged with red.
We had two external approaches or inputs into the system,
an external standardization, which I'll show a bit later,
where the process teams
define the standard requirements for the analysis file.
And our help files, we decided to move them all externally
so that they can continue to evolve as the users in the system evolved.
We broke our development into two major development cycles.
Early development cycle,
where we develop proof of concepts so we would have a problem,
we would develop a proof of concept working prototype to address that problem.
We would iterate on it until it was solving the problem
and it was reasonably stable.
And then we moved it into the late development cycle
and continued the agile development, where in this case,
we applied it to actual project work and did very careful second- person reviews
to make sure all the results were correct and continue to refine the modules
based on feedback over and over again to get to a more stable and better state.
One of these proof of concept wow factors that we did at the very beginning
was the Heat Map tool,
which brought together all kinds of information in the dashboard
and it saved the team's enormous amounts of time.
I'll show you an example of this later.
But you can see the quotes on the right- hand side,
they were very excited about this. They actually helped design it.
And so we got early engagement, we got motivation for additional funding
and a lot of excitement generated by this initial proof of concept.
In summary, we had a problem to solve, the PC statistics workflow.
We had a choice to make and we chose JMP.
And our consequences copying and paste, manual, mistakes, extensive reworking.
We had to develop a solution, and that was BPC-Stat.
I'm extremely happy to end this portion of our talk
and let Seth take you through a demonstration of BPC-Stat.
We have a core demo that we've worked out
and we're actually going to begin at the end.
In the end, which is that proof of concept Heat Map tool
that we had briefly shown a picture of is when the scientists have completed
all of their analysis and the files are all complete,
the information for impact ratio is all available
and collected into a nice summary file,
which I'm showing here.
Where for each attribute in each process factor,
we have information about the profiler,
it's predicted means and ranges as the process parameter changes.
So we can compute changes across that process factor in the attribute
and we can compute that impact ratio that we mentioned earlier.
Now, I'm going to run this tool and we'll see what it does.
So first, it pulls up one of our early innovations by the scientists.
We organized all this information that we had across multiple studies.
Now, this is showing three different process steps here
and you can see on the x- axis, we have the process steps laid out.
In each process step, we have different studies that are contributing to that,
we have multiple process parameters,
and they are all crossed with these attributes that we use
to assess the quality of the product that's being produced.
And we get this Heat Map here.
The white spaces indicate places
where the process parameter either dropped out of the model or was not assessed.
And then the colored ones are where we actually have models built.
And of course, the intensity of the heat
is depending on this practical impact ratio.
This was great solution for the scientists,
but it still wasn't enough because we had disruptions to the discussion.
We could look at this and say, okay, there's something going on here,
we have this high impact ratio,
then they would have to track down where is that coming from.
Oh, it's in this study. It's this process parameter.
I have to go to this file.
I look up that file, I find the script among the many scripts.
I run the script,
I have to find the response and then finally I get to the model.
We enhance this so that now it's just a simple click and the model is pulled up.
The relevant model is pulled up below.
You can see where that impact ratio of one is coming from.
Here, the gap between the predicted process mean
and the attribute limit is the space right here.
And the process parameter trend is taking up essentially the entire space.
That's why we get that impact ratio of one.
Then the scientists can also run their simulators
that have been built or are already here, ready to go.
They can run simulation scenarios to see what the defect rates are.
They can play around with the process parameters
to establish proven acceptable ranges that have lower defect rates.
They can look at interactions, the contributions from that.
They can also put in notes over here on the right
and save that in a journal file
to keep track of the decisions that they're making.
And notice that all of this is designed to support them,
maintaining their scientific dialogue, and prevent the interruption to that.
They can focus their efforts on particular steps.
So if I click on a step, it narrows down to that.
Also, because our limits tend to be in flux,
we have the opportunity to update those
and we can update them on the fly to see what the result is.
And you can see here how this impact changed
and now we have this low- impact ratio
and say, how does that actually look on the model?
The limit's been updated now, you can see there's much more room
and that's why we get that lower impact ratio and we'll get lower failure rates.
That was the heat map tool and it was a huge win
and highly motivated additional investment into this automation.
I started at the end,
now I'm going to move to the beginning of the process statistics workflow,
which is in design.
When we work with the upstream team,
they have a lot of bio reactors that they run in each of these runs.
This is essentially a central composite design.
Each of these runs is a bio reactor and that bio reactor sometimes goes down
because of contamination or other issues that essentially are missing at random.
So we built a simulation
to evaluate this to potential losses called evaluate loss runs.
And we can specify how many runs are lost.
I'm just going to put something small here for demonstration
and show this little graphic.
What it's doing is it's going through randomly selecting points
to remove from the design in calculating variance inflation factors,
which can be used to assess multi linearity
and how well we can estimate model parameters.
And when it's done, it generates a summary report.
This one's not very useful because I had very few simulations,
but I have another example here.
This is 500 simulations on a bigger design.
And you can see we get this nice summary here.
If we lose one bio reactor, we have essentially a zero probability of
getting extreme variance inflation factors or non- estimable parameter estimates.
And so that's not an issue.
If we lose two bio reactors up to about 4%, that's starting to become an issue.
So we might say for this design, two bio reactors is a capability of loss.
And if we really wanted to get into the details,
we can see how each model parameters impacted on variance inflation
for given number of bioreactors lost,
or we can rank order all the combinations of bioreactors that are lost,
which specific design points are impacting the design the most,
and do further assessments like that.
That's our simulation and that's now a routine part of our process that we use.
I'm going to move on here to standardization.
We talked about the beginning of the process statistics workflow,
the end of the process statistics workflow,
now I'm going to go back to what is the beginning of BPC-Sta t itself.
When people install this, they have to do a setup procedure.
And the setup is basically specifying the preferences.
It's specifying those input parameter,
input standardizations that we had talked about earlier,
as well as the help file, what process area they're working with,
and default directory that they're working with.
And then that information is saved into the system and they can move forward.
Let me just show some examples here of the standardization files and the Help file.
Help file can also be pulled up under the Help menu.
And of course, the Help file is the JMP file itself.
But notice that it has in this location column,
these are all videos that we've created that explain and they're all timestamped
and so users can just figure out what they're looking for, what feature.
Click on it, immediately pull up the video.
But what's even more exciting about this is in all the dialogues of BTC-Stat,
when we pull up a dialogue and there's a Help button there,
it knows which row in this table to go to get the help,
and it will automatically pull up.
If I click that Help button, it will automatically pull up
the associated link and training to give immediate help.
That's our Help file.
The standardization.
We have standardizations that we work with the teams
to standardize either across projects or within a specific project,
depending on the needs and for process areas.
We had this problem early on that we weren't getting consistent naming
and it was causing problems and rework.
Now, we have this standardization put in place.
Also, the reporting decimals that we need to use,
the minimum recorded decimals, what names we use when we write this
in a report, our unit, and then a default transform to apply.
That's our attribute standardization.
And then for our group standardization, it's very similar identifying columns,
except we have this additional feature here that we can require
only specific levels be present and otherwise will be flagged.
We can also require that they have a specific value ordering.
So let, for example, the process steps are always listed in process step order,
which is what we need in all our output.
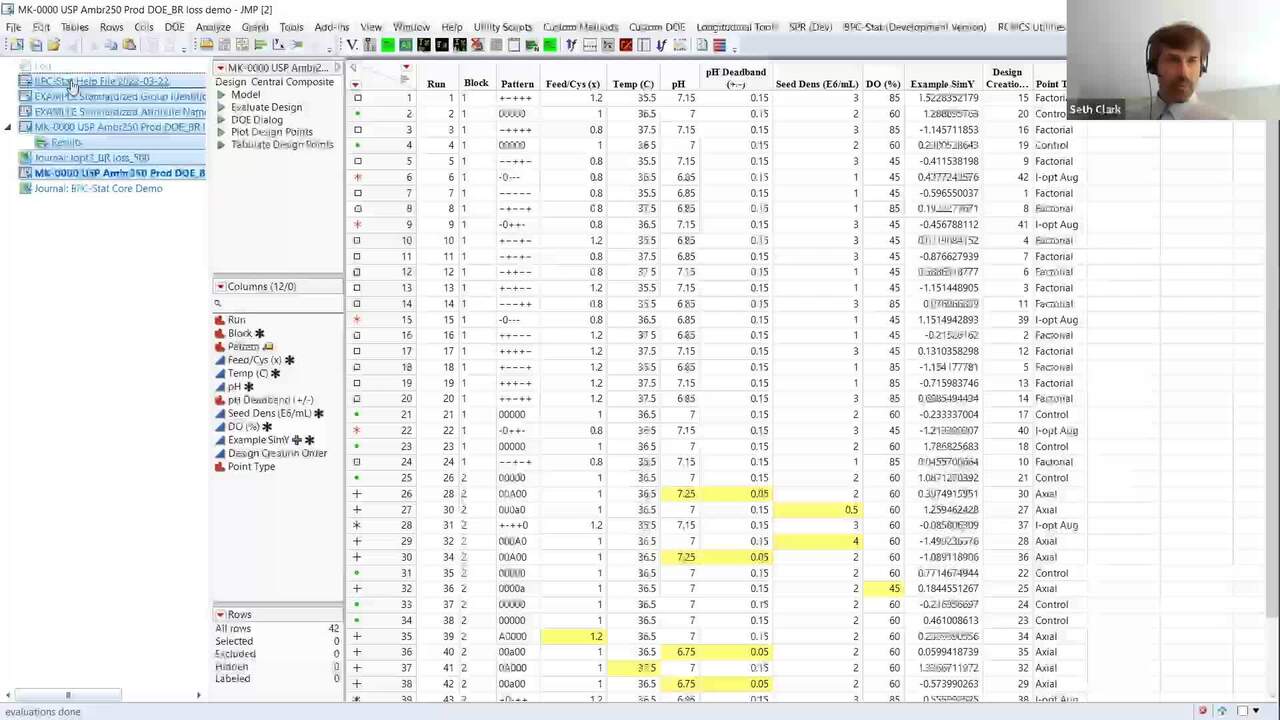
Okay, so I'm going to show an example of this.
Let me see if I can close
some of the previous stuff that we have open here.
Okay, so let me go to this example.
So here's the file. The data has been compiled.
We think it's ready to go, but we're going to make sure it's ready to go.
So we're going to do the standardization.
First thing is looking at attribute
that recognizes the attributes that are erred the standard names.
And then what's left is up here.
And we can see immediately these are process parameters,
which we don't have the standardization set up for.
But we see immediately that something's wrong with this,
and we see in the list of possible attributes that the units are missing.
We can correct that very easily.
It will tell us what it's doing, we're going to make that change.
And then it generates a report,
and then that stoplight coloring and says, oh, we found these.
This is a change we made, pay attention to this caution.
These are ones we didn't find.
And this report is saved back to the data table
so it can be reproduced on demand.
And I'll go through the group standardization
just to take a quick look at that.
Here, it's telling me red, stop light coloring.
We have a problem here, you're missing these columns.
The team has required that this information be included.
It's going to force those columns onto the file.
We have the option with the yellow to add additional columns.
And so we'll go ahead and run that, and it's telling us what it's going to do.
And then it does the same thing, creates a report.
And we look through the report and we notice something's going on here.
Process scale.
Our process scale can only have large lab micro.
Guess what, we have a labbb. We have an extra B in there.
So that's an error. If we find that value, correct it.
Rerun the standardization and everything is good there.
I did want to point out one more thing here.
You'll see that these are our attributes,
there are these little stars indicating properties.
The properties that are assigned when we did the standardization
is this custom property table deck.
And that's going to pass information to the system
about what the reporting precision is when it generates tables.
Also, our default transformation for HCP was logged,
so it automatically created the log transform for us.
So we don't have to do that.
Okay.
That's the standardization, let's move on to a much more interesting things now.
The PC analysis.
Before I get to that, I just want to mention that
we have a module for scaled- down model qualification.
And essentially, it's using JMP's built- in equivalents testing.
But it enhances it by generating some custom plots
and summarizing all that information at a table that's report ready.
It's beautiful.
Unfortunately, we don't have time to cover that.
I'm going to go now into the PC analysis, which I'm really excited about here.
I have this.
Standardization has already been done.
We have this file that contains lab results,
experimental design that's been executed at labscale.
We have large scale data in here. We can't execute...
It's not feasible to execute BOEs at large scale,
but we have this at the control point.
We want to be able to project our models to that large scale.
And because we have different subsets and we have potentially different models,
this one only has a single model,
but we can have different models and different setups,
we decided to create a BPC-Stat workflow and we have a workflow set up tool
that helps us build that based on the particular model we're working with.
I can name each of these workflows and I provide this information
that it's going to track throughout the whole analysis.
What is our large- scale setting, what are our responses?
Notice this is already populated for me.
It looked at the file and said, oh, I know these responses,
they're in your standardized file, they're in this file, they exist.
I assume you want to analyze this and they get pre- populated.
It also recognize this as a transform
because it knows that for that HCP, we want that on a log transform.
And it's going to do it internally transform,
which means JMP will automatically back transform it
so that scientists can interpret it on the original scale.
There are some additional options here. This PC block right now is fixed.
In some cases, the scientists want to look at the actual PC Block means.
But for the simulation, we're interested in a population- type simulation.
We don't want to look at specific blocks, we want to see what the variability is.
So we're going to change that PC Block factor
into a random effect when we get to the simulation.
And we're going to add a process scale to our models
so we can extend our model to a large scale.
The system will review the different process parameters and check the coding.
If there's some issues here or a coding missing,
it will automatically flag that with the stoplight coloring.
We have here the set point. Very tedious exercise, annoying.
We constantly want to show everything at the set point in the profilers
because that's our control,
not the default that JMP's calculating the mathematical center.
So we built this information in so that it could be automatically added.
And then we can define the subsets for an analysis.
And for that, we use a data filter.
I'll show here for this data filter
and there's explanation of this in the dialogue.
But we want to do summary statistics on a small scale.
So I go ahead and select that.
It gives feedback on how many rows are in that subset
and what the subset is so we can double- check that that's correct.
And then for the PC analysis, in this case,
I have the model setup so that, of course,
it's going to analyze the DOE with the center point
but it's also going to do this single factor study,
or what they call OFAT and SDM block,
separate center points that were done as another block.
And that's all built into another block in the study for that PC block.
Lastly, I can specify subsets for confirmation points,
which they like to call verification points,
to check and to see how well the model is predicting.
We don't have those in this case.
And for what is our subset for large scale,
that would include both the lab and the large scale data.
Since it's all the data in this case, I don't have to specify any subset.
Now, I have defined my workflow.
I click okay, and it saves all that information right here as a script.
If I right- click on that, edit it, you can see what it's doing.
It's creating a new namespace.
It's got the model in there, it's got all my responses,
and everything I could need for this analysis.
A s soon as you see this, you start thinking, well,
if I have to add another response, I can stick another response in here.
But that violates the principle of no script editing.
Well, sometimes we do it, but don't tell anybody.
What we did is we built a tool that has a workflow editor
that allows us to go ahead back into that workflow
through point and click and change some of its properties and change the workflow.
I'm going to go ahead now and do the analysis.
And this is where the magic really comes in.
When I do the PC analysis set up,
it's going to go take that workflow information and apply it
across the entire set of scripts that we need for our analysis.
And you see what it just did there.
It dropped a whole bunch of scripts. It grouped them for us.
Everything is ready to go.
It's a step- by- step process, the scientists can follow it through.
If there are scripts that are not applicable,
they can remove those scripts and they're just gone.
We don't worry about them.
And then for the scripts that are present, we have additional customization.
These are essentially generator scripts.
And you can see it generates a dialogue
that's already pre- populated with what we should need,
but we have additional flexibility if we need it.
And then we can get our report and we can enhance it as we need to,
in this case, subsets I may want to include.
And then resave the script back to the table and replace the generator script.
Now, I have a rendered script here that I can use that's portable.
Then for the PC analysis, we have data plots.
Of course, we want to show our data.
Always look at your data, generate the plots.
There's a default plot that's built.
And now the user, we only did one plot
because we wanted the user to have the option to change things
so they might go in here, say, get rid of that title.
I just changed the size and I add a legend, whatever.
You can change the entire plot if they wanted to.
And then one of their all- time favorite features of BPC-Stat
seems to be this repeat analysis.
Once we have an analysis we like, we can repeat it.
And what this is doing is it's hacking the column switcher
and adding some extra features onto it.
It'll take the output, dump it in a vertical list box or tab box,
and allow us to apply our filtering either globally or to each analysis.
Now, I'm in the column switcher
and I can tell it what columns I want it to do.
This works for any analysis, not just plotting.
Click OK.
It runs through the switcher, generates the report.
There I have it. All my responses are plotted.
That was easy.
I go down and there's the script that recreates that.
I can drop it here, get rid of the previous one.
Done.
Descriptive statistics. Here we go.
It's already done.
I have the subsetting applied, to have the tables I need.
Look at this.
It's already formatted to the number of decimals I needed
because it's taking advantage of those properties that we had assigned,
those unique properties based on this table standardization.
So that one is done.
And then the full model.
Full model is set up, ready to go for what would you think?
It's ready to go for residual assessment.
We can go through each of the models one at a time
and take a look to see how the points are behaving, the lack of fit.
Does it look okay?
Here, we have one point that may be a little bit off we might want to explore.
Auto recalc is already turned on,
so I can do a row exclude and it will automatically update this.
Or we have a tool that will exclude the data point in a new column
so that I can analyze it side by side.
And then since I've already specified my responses,
in order to include that side by side,
I would have to go back and modify my workflow.
And we have that workflow editor to do that.
I'm just going to skip ahead to save some time where I've already done that.
This is the same file, same analysis,
but I've added an additional response and it's right here.
Yield without run 21.
Now, scientists can look at this side by side and say,
you know what, that point, yeah, it's a little bit unusual statistically,
but practically there's really no impact.
All right, let's take this further.
This is our routine process.
We do take it all the way through the reduced model
because we want to see if it impacts model selection.
We have automated the model selection
and it takes advantage of the existing stepwise for forward AIC
or the existing effects table where you can click to remove by backward
selection manually if you want, this automates the backward selection
which we typically use for split pot designs.
We also have a forward selection for mixed models which is not currently
a JMP feature and JMP that we find highly useful.
I'm going to go ahead, since it's a fixed model,
I'm going to do that and gets the workflow information.
I know I need to do this on the full model.
It goes ahead and does the selection.
What it's doing in the background here is it's running each model,
it's constructing report of the selection that it's done
in case we want to report that.
And it's going to save those scripts back to the data table.
There's that report right there that contains all the selection process.
Those scripts were just generated and dumped back here.
Now, I can move those scripts back into my workflow section.
I know the reduced model goes in there
and this is my model selection step history.
I can put that information in there.
Okay, so this is great.
Now, when I looked at my reduced model, I have that gone through the selection.
Now I can see the impact of the selection on removing this extra point here.
And again, we see there's just basically,
likely the scientists would conclude there's just no practical difference here.
And they could even go, and should go
and look at the interaction profilers as well, compare them side by side.
This is great.
We want to keep this script because we want to keep track
of the decisions that we made, so there's a record of that.
But we also want to report the final model.
So we want a nice, clean report.
We don't want that without running response in there
because we've decided that it's not relevant,
we need to keep all the data.
Another favorite tool that we developed is the Split Fit Group
which allows us to break up these fit groups
We have the reduced model here. Take the reduced model.
And allows us to break them up into as many groups as we want.
In this case, we're only going to group it up into one group
because we're going to eliminate one response.
We want one group.
When we're done, we're just using this to eliminate this response
we no longer want in there.
Click Okay.
That's some feedback from the model fitting, and boom, we have it.
The fit group is now there and without response analysis has been removed.
Now we have this ready to report.
Notice that the settings for the profiler, they're all the settings we specified.
It's not at the average point or the center point,
it's at the process set point,
which is where we need it to be for comparison purposes.
It's all ready to go.
Okay, so that generates that script there when I did that split.
I can put it up here and I can just rename that.
That's final models.
Okay, very good.
Now, for some real fun.
Remember we had talked about how tedious it is
to set up this simulation script.
Now watch this. Watch how easy this is for the scientists.
And before I do this, I want to point out that this was,
of course, created by a script, obviously JSL,
but this is a script that creates a script that creates a script.
So this was quite a challenge for Adsurgo to develop.
But when I run this, I can pick my model here,
final models, and then in just a matter of seconds,
it generates the simulation script that I need.
I run that, and boom. There it is, all done.
It set up the ranges that I need for the process parameters.
It's set them up to the correct intervals. It set the ad random noise.
But there's even more going on here than what appears.
Notice that the process scale has been added,
we didn't have that in the model before.
That was something that was added so that we could take these labs,
scale DOE models, and extend them to the large scale.
Now we're predicting large scales. That's important.
That was a modification to the model.
Previously, very tedious editing of the script was required to do that.
Notice that we also have this PC block random effect in here we had specified
because we don't want to simulate specific blocks,
now it's an additional random effect.
And the total variance is being plugged into the standard deviation
for the ad random noise, not the default residual random noise.
We also added this little set seed here so we can reproduce our analysis exactly.
So this is really great.
And again, notice that we're at the process set point where it should be.
Okay, last thing I want to show here is the reporting.
We essentially completed the entire analysis,
you can see it's very fast.
We want to report these final models out into a statistics report.
And so we have a tool to do that.
And this report starts with a descriptive statistics.
I'm going to run that first,
and then we're going to go and build the report, export stats to Word.
And then I have to tell it which models do I want to export.
It's asking about verification plots.
We didn't have any in this case for confirmation points.
So we're going to skip that.
And then it defaults to the default directory that we set the output.
I'm going to open the report when I'm done.
And this is important.
We're leaving the journal open for saving and modification.
Because as everybody knows, when you copy stuff,
you generate your profilers,
you dump them in Word, and there's some clipping going on.
We may have to resize things,
we may have to put something on a log scale.
We can do all that in the journal and then just resave it back to Word.
That saves a step. So we generate that.
I click okay here.
It's reading the different tables and the different profilers,
and it's generating this journal up here.
That's actually the report that it's going to render in Word.
And it will be done in just a second here.
Okay.
And then just opening up Word.
And boom, there's our report.
So look at what it did.
It puts captions here, it put our table.
It's already formatted to the reporting precision that we need.
It has this footnote that it added, meeting our standards.
And then for each response, it has a section.
And then the section has the tables with their captions, and the profilers,
and interaction profiler, footnotes, et cetera.
And it repeats on and on for each attribute over and over.
It also generates some initial text
that the scientists can update with some summary statistics.
And so it's pretty much ready to go and highly standardized.
That completes the demo of the system.
Now, I just have one concluding slide that I want to go back to here.
So, in conclusion, BPC-Stat, it's added value to our business.
It's enabled our process teams. It's paralyzed the work.
It's accelerated our timelines.
We've implemented a standardized, yet flexible systematic approach
with that higher, faster acceleration, and much more engagement.
Thank you very much.
